Attention Is All You Need
2017NIPS Google
背景
Attention机制最早在视觉领域提出,2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型,并加入了Attention机制来进行图像的分类。
2015年,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,将attention机制首次应用在nlp领域,其采用Seq2Seq+Attention模型来进行机器翻译,并且得到了效果的提升。
2017 年,Google 机器翻译团队发表的《Attention is All You Need》中,完全抛弃了RNN和CNN等网络结构,而仅仅采用Attention机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也成为了大家近期的研究热点。
本文首先介绍常见的Attention机制,然后对论文《Attention is All You Need》进行介绍,该论文发表在NIPS 2017上。
目前主流的处理序列问题像机器翻译,文档摘要,对话系统,QA等都是encoder和decoder框架,
编码器:从单词序列到句子表示
解码器:从句子表示转化为单词序列分布
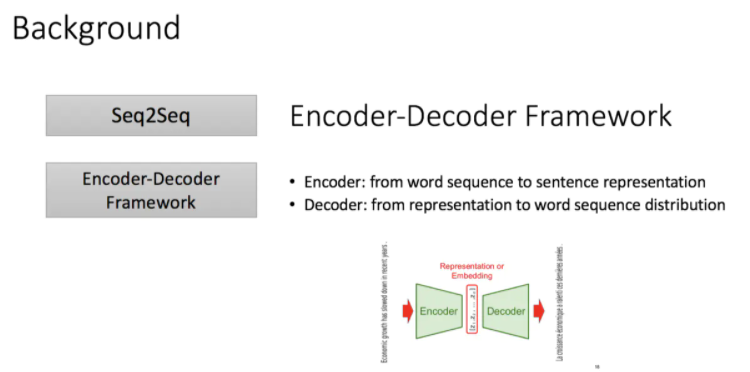
传统的编码器解码器一般使用RNN,这也是在机器翻译中最经典的模型,但正如我们都知道的,RNN难以处理长序列的句子,无法实现并行,并且面临对齐问题。
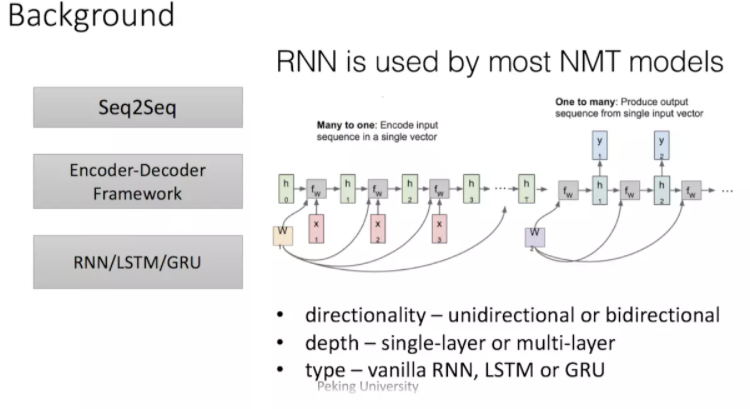
之后这类模型的发展大多从三个方面着手:
input的方向性 - 单向或双向
深度 - 单层或多层
类型– RNN,LSTM或GRU

但是依旧收到一些潜在问题的制约,神经网络需要能够将源语句的所有必要信息压缩成固定长度的向量。这可能使得神经网络难以应付长时间的句子,特别是那些比训练语料库中的句子更长的句子;每个时间步的输出需要依赖于前面时间步的输出,这使得模型没有办法并行,效率低;仍然面临对齐问题。
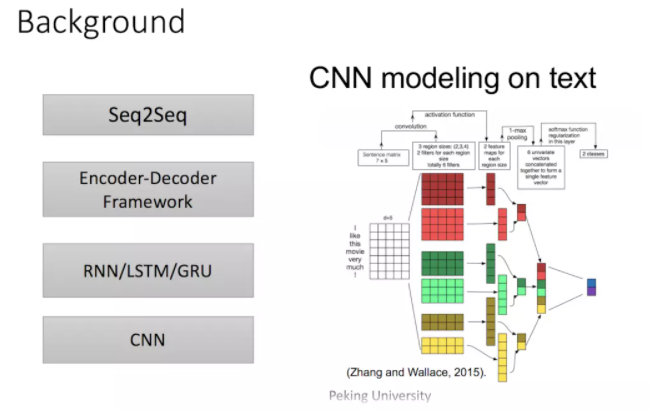
再然后CNN由计算机视觉也被引入到deep NLP中,CNN不能直接用于处理变长的序列样本但可以实现并行计算。完全基于CNN的Seq2Seq模型虽然可以并行实现,但非常占内存,很多的trick,大数据量上参数调整并不容易。
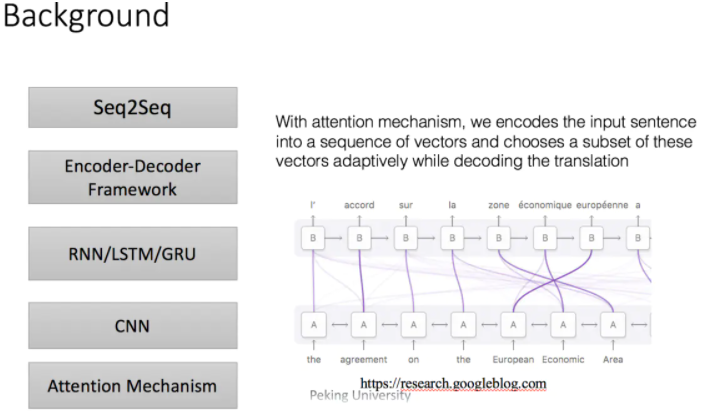
以上这些缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。为了解决上面提到的问题,一种可行的方案是引入attention mechanism。
深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观察时,其实眼睛聚焦的就只有很小的一块,这个时候人的大脑主要关注在这一小块图案上,也就是说这个时候人脑对整幅图的关注并不是均衡的,是有一定的权重区分的。这就是深度学习里的Attention Model的核心思想。所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。我们可以看一下上面这幅图——通过注意力机制,我们将输入句子编码为一个向量序列,并自适应地选择这些向量的一个子集,同时对译文进行译码,例如where are you——>你在哪?现在我们在翻译“你”的时候给"you"更多的权重,那么就可以有效的解决对齐问题。
评价
抛弃了之前传统的encoder-decoder模型必须结合cnn或者rnn的固有模式,只用attention;
目的是在减少计算量和提高并行效率的同时不损害最终的实验结果;
创新之处在于提出了两个新的Attention机制,分别叫做Scaled Dot-Product Attention和Multi-Head Attention。
Attention机制
Attention机制用于计算相关程度,例如在翻译过程中,不同的英文对中文的依赖程度不同,Attention机制通常可以进行如下描述,输入为序列(query) Q Q Q 和 (key-value pairs) { K i , V i ∣ i = 1 , 2 , … , m } \left\{K_{i}, V_{i} \mid i=1,2, \ldots, m\right\} {
Ki,Vi∣i=1,2,…,m},输出为Attention向量,是对key-value pairs中所有values的加权,这个加权的权重是由query和每个key计算出来的(针对不同的输入在不同的键值上反映的相关性不同,计算的权重不同)
其中query、每个key、每个value都是向量,计算如下:
第一步:计算比较 Q Q Q和 K K K的相似度,用 f ( ⋅ ) f(\cdot) f(⋅)来表示
f ( Q , K i ) , i = 1 , 2 , … , m (1) f\left(Q, K_{i}\right), i=1,2, \ldots, m \tag{1} f(Q,Ki),i=1,2,…,m(1)
第二步:将得到的相似度进行Softmax操作,进行归一化
α i = e f ( Q , K i ) ∑ j = 1 m f ( Q , K j ) , i = 1 , 2 , … , m (2) \alpha_{i}=\frac{e^{f\left(Q, K_{i}\right)}}{\sum_{j=1}^{m} f\left(Q, K_{j}\right)}, i=1,2, \ldots, m \tag{2} αi=∑j=1mf(Q,Kj)ef(Q,Ki),i=1,2,…,m(2)
第三步:针对计算出来的权重 α i \alpha_{i} αi,通过权重对 V V V中所有的values进行加权求和计算,得到Attention向量
∑ i = 1 m α i V i (3) \sum_{i=1}^{m} \alpha_{i} V_{i} \tag{3} i=1∑mαiVi(3)
通常第一步中计算方法包括以下四种:
- 点乘
dot productf ( Q , K i ) = Q T K i f\left(Q, K_{i}\right)=Q^{T} K_{i} f(Q,Ki)=QTKi
- 权重
Generalf ( Q , K i ) = Q T W K i f\left(Q, K_{i}\right)=Q^{T} W K_{i} f(Q,Ki)=QTWKi
- 拼接权重
Concatf ( Q , K i ) = W [ Q ; K i ] f\left(Q, K_{i}\right)=W\left[Q ; K_{i}\right] f(Q,Ki)=W[Q;Ki]
- 感知器
Perceptronf ( Q , K i ) = V T tanh ( W Q + U K i ) f\left(Q, K_{i}\right)=V^{T} \tanh \left(W Q+U K_{i}\right) f(Q,Ki)=VTtanh(WQ+UKi)
Transformer Architecture
绝大部分的序列处理模型都采用encoder-decoder结构,其中encoder将输入序列 ( x 1 , x 2 , … , x n ) (x_{1}, x_{2}, \ldots, x_{n}) (x1,x2,…,xn)映射到连续表示 z ⃗ = ( z 1 , z 2 , … , z n ) \vec{z}=\left(z_{1}, z_{2}, \ldots, z_{n}\right) z=(z1,z2,…,zn)然后decoder生成一个输出序列 ( y 1 , y 2 , … , y n ) (y_{1}, y_{2}, \ldots, y_{n}) (y1,y2,…,yn),每个时刻输出一个结果。Transformer模型延续了这个模型,整体架构如下图。
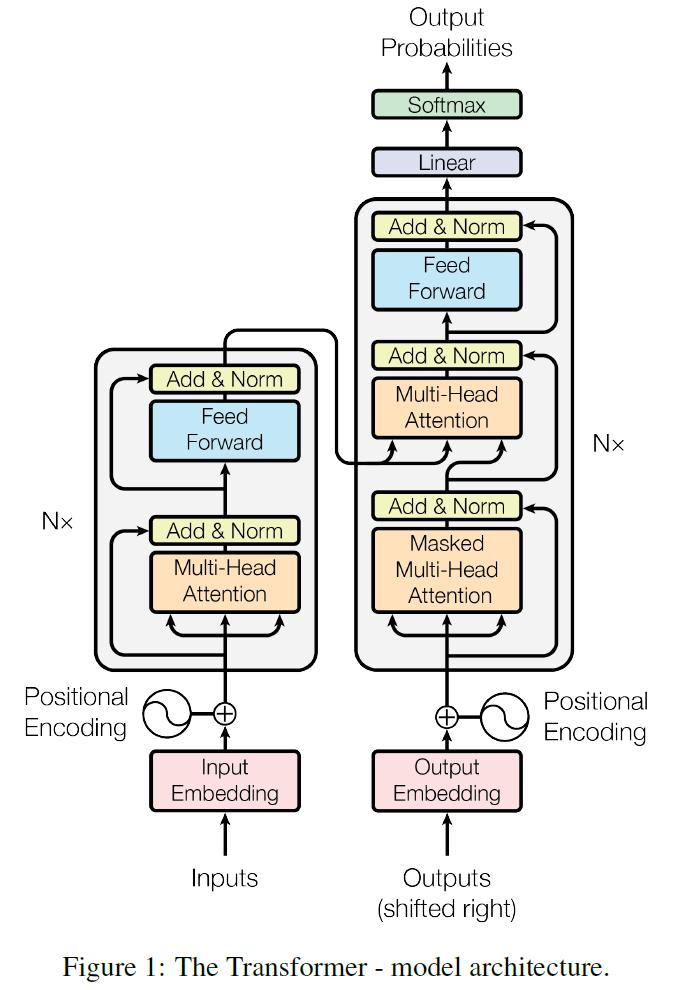
Encoder
Encoder有 N = 6 N=6 N=6层,每层包括两个sub-layers:
- 第一个
sub-layer是multi-head self-attention mechanism,用来计算输入的self-attention - 第二个
sub-layer是简单的全连接网络。
在每个sub-layer都模拟了残差网络,每个sub-layer的输出都是
L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x + Sublayer(x)) LayerNorm(x+Sublayer(x))
其中 S u b l a y e r ( x ) Sublayer(x) Sublayer(x) 表示Sub-layer对输入 x x x做的映射,为了确保连接,所有的sub-layers和embedding layer输出的维数都相同。
概述:
每个层有两个子层。
第一个子层是多头自我注意力机制(multi-head self-attention mechanism)
第二层是简单的位置的全连接前馈网络(position-wise fully connected feed-forward network)。
在两个子层中会使用一个残差连接,接着进行层标准化(layer normalization)。
网络输入是三个相同的向量 Q Q Q, K K K和 V V V,是
word embedding和position embedding相加得到的结果。为了方便进行残差连接,我们需要子层的输出和输入都是相同的维度。
Decoder
Decoder也是 N = 6 N=6 N=6层,每层包括3个sub-layers:
- 第一个是
Masked multi-head self-attention,因为是生成过程,因此在时刻 i i i的时候,大于 i i i的时刻都没有结果,只有小于 i i i的时刻有结果,只能获取到当前时刻之前的输入,也就是一个Mask操作。 - 第二个和第三个
sub-layer与Encoder相同,都是用了残差连接之后接上层标准化
概述:
decoder中的Layer由encoder的Layer中插入一个Multi-Head Attention + Add&Norm组成。输入:
encoder输出的word embedding与输出的position embedding求和做为decoder的输入第一个
Multi-HeadAttention + Add&Norm命名为MA-1层,MA-1层的输出做为下一MA-2层的 Q Q Q输入,MA-2层的 K K K和 V V V输入(从图中看,应该是encoder中第 i ( i = 1 , 2 , 3 , 4 , 5 , 6 ) i(i = 1,2,3,4,5,6) i(i=1,2,3,4,5,6)层的输出对于decoder中第 i ( i = 1 , 2 , 3 , 4 , 5 , 6 ) i(i = 1,2,3,4,5,6) i(i=1,2,3,4,5,6)层的输入)。
MA-2层的输出作为一个前馈层FF的输入,经过AN操作后,经过一个线性+softmax变换得到最后目标输出的概率。对于
decoder中的第一个多头注意力子层,需要添加mask,确保预测位置i的时候仅仅依赖于位置小于 i i i的输出。层与层之间使用的Position-wise feed forward network。
Attention机制的实现
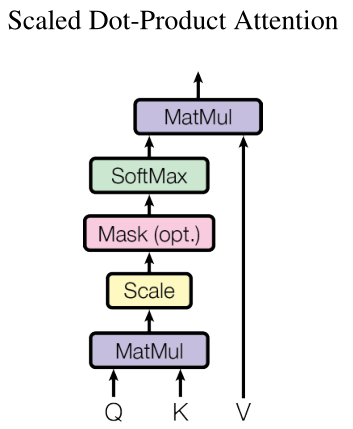
Scaled Dot-Product Attention
有两种常用的注意力函数,一种是加法注意力(additive attention),另外一种是点乘注意力(dot-productattention),论文所采用的就是点乘注意力,这种注意力机制对于加法注意力而言,更快,同时更节省空间。
在Transformer中使用的Attention是Scaled Dot-Product Attention, 是归一化的点乘Attention,计算公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention (Q,K,V)=softmax(dkQKT)V
输入:
queryQ Q Q 和keyK K K的维度是 d k d_k dk,valueV V V 的维度是 d v d_v dv,在实践中,将query和key、value分别处理为矩阵 ( Q , K , V ) (Q, K, V) (Q,K,V), 那么计算输出矩阵形式如上公式。这里把
attention抽象为对value的每个表示(token)进行加权,而加权的weight就是attention weight,而attention weight就是根据query和key计算得到,其意义为:为了用value求出query的结果, 根据query和key来决定注意力应该放在value的哪部分。以前的attention是用LSTM做encoder,也就是用它来生成key和value,然后由decoder来生成query。
计算
query和每个key的点乘操作,并除以 d k \sqrt{d_{k}} dk,然后应用Softmax函数计算权重。除以一个数字 d k \sqrt{d_{k}} dk的意义是(1)是因为如果 d k d_k dk太大,点乘的值太大,如果不做scaling,结果就没有加法注意力好。
(2)为了不让输入太大,导致softmax函数被推动到非常平缓的区域。其中 Q ∈ R m × d k , K ∈ R m × d k , V ∈ R m × d v Q \in \mathbb R^{m \times d_{k}}, K \in \mathbb R^{m \times d_{k}}, V \in \mathbb R^{m \times d_{v}} Q∈Rm×dk,K∈Rm×dk,V∈Rm×dv,输出矩阵维度为 R m × d v \mathbb R^{m \times d_{v}} Rm×dv,如下所示
$Q=\underbrace{\left(\begin{array}{c}q \ q \ q \ \vdots \ q\end{array}\right)}{d{k}}} m , Q=\underbrace{\left(\begin{array}{c}k_1 \ k_2 \ k_3 \ \vdots \ k_m\end{array}\right)}{d{k}}} m , V=\underbrace{\left(\begin{array}{c}v_1 \ v_2 \ v_3 \ \vdots \ v_m\end{array}\right)}{d{v}}} m $
那么
Scaled Dot-Product Attention的示意图如下所示,Mask是可选的操作(opt.),如果是能够获取到所有时刻的输入 ( K , V ) (K, V) (K,V),那么就不使用Mask;如果是不能获取到,那么就需要使用Mask。
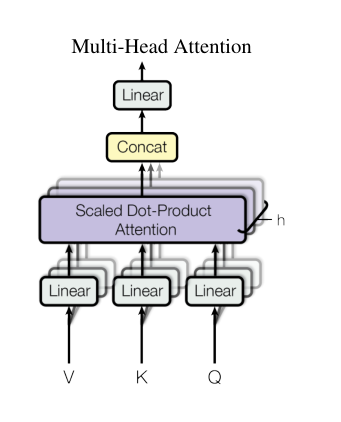
Multi-Head Attention
如果只对 Q , K , V Q,K,V Q,K,V做一次这样的权重操作是不够的,这里提出了Multi-Head Attention,操作包括:
- 首先对 Q , K , V Q,K,V Q,K,V做若干次( h t i m e s h \quad times htimes)线性映射,将输入维度均为 d m o d e l d_{model} dmodel的 Q , K , V Q,K,V Q,K,V 矩阵映射到 Q ∈ R d k , K ∈ R d k , V ∈ R d v Q \in \mathbb R^{d_{k}}, K \in \mathbb R^{d_{k}}, V \in \mathbb R^{d_{v}} Q∈Rdk,K∈Rdk,V∈Rdv
- 然后分别对每个线性映射结果采用
Scaled Dot-Product Attention计算出结果,拼接在一起 - 将合并的结果进行线性变换
总结来说公示如下所示
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) W O where head i = Attention ( Q W i Q , K W i K , V W i V ) \begin{aligned} \operatorname{MultiHead}(Q, K, V) &=\text { Concat }\left(\text { head }_{1}, \ldots, \text { head }_{\mathrm{h}}\right) W^{O} \\ \text { where head }_{\mathrm{i}} &=\text { Attention }\left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right) \end{aligned} MultiHead(Q,K,V) where head i= Concat ( head 1,…, head h)WO= Attention (QWiQ,KWiK,VWiV)
其中线性变换参数为 W i Q ∈ R d model × d k , W i K ∈ R d model × d k , W i V ∈ R d model × d v W_{i}^{Q} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}, W_{i}^{K} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}, W_{i}^{V} \in \mathbb{R}^{d_{\text {model }} \times d_{v}} WiQ∈Rdmodel ×dk,WiK∈Rdmodel ×dk,WiV∈Rdmodel ×dv and W O ∈ R ( h × d v ) × d model W^{O} \in \mathbb{R}^{(h\times d_{v}) \times d_{\text {model }}} WO∈R(h×dv)×dmodel 在论文中取 d m o d e l = 512 d_{model} = 512 dmodel=512,表示每个时刻的输入维度和输出维度, h = 8 h=8 h=8表示8个不同映射下的
Attention操作, d k = d v = d m o d e l h = 64 d_k = d_v = \frac{d_{model}}{h} = 64 dk=dv=hdmodel=64 表示经过线性变换之后、进行Attention操作之前的维度。那么进行一次
Attention之后输出的矩阵维度是 R d v = R 64 \mathbb R^{d_v} = \mathbb R^{64} Rdv=R64,然后进行 h = 8 h = 8 h=8次操作合并之后输出的结果是,因 R 8 × d v = R 512 \mathbb R^{8 \times d_v} = \mathbb R^{512} R8×dv=R512此输入和输出的矩阵维度相同。在上图的
Encoder-Decoder架构中,有三处Multi-head Attention模块,分别是:
Encoder模块的Self-Attention,在Encoder中,每层的Self-Attention的输入 Q = K = V Q=K=V Q=K=V,都是上一层的输出。Encoder中的每个position都能够获取到前一层的所有位置的输出。Decoder模块的Mask Self-Attention,在Decoder中,每个position只能获取到之前position的信息,因此需要做mask,将其设置为 − ∞ -\infty −∞Encoder-Decoder之间的Attention,其中 Q Q Q来自于之前的Decoder层输出, K , V K,V K,V来自于encoder的输出,这样decoder的每个位置都能够获取到输入序列的所有位置信息。
Position-wise Feed-forward Networks
在进行了Attention操作之后,encoder和decoder中的每一层都包含了一个全连接前向网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \operatorname{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2} FFN(x)=max(0,xW1+b1)W2+b2
其中每一层的参数都不同。
Position Embedding
因为模型不包括recurrence/convolution,因此是无法捕捉到序列顺序信息的,例如将 K 、 V K、V K、V按行进行打乱,那么Attention之后的结果是一样的。但是序列信息非常重要,代表着全局的结构,因此必须将序列的token相对或者绝对position信息利用起来。
这里每个token的position embedding 向量维度也是 d m o d e l = 512 d_{model} = 512 dmodel=512 然后将原本的input embedding和position embedding加起来组成最终的embedding作为encoder/decoder的输入。其中position embedding计算公式如下
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d model ) P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d model ) \begin{aligned} P E_{(p o s, 2 i)} &=\sin \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \\ P E_{(p o s, 2 i+1)} &=\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \end{aligned} PE(pos,2i)PE(pos,2i+1)=sin(pos/100002i/dmodel )=cos(pos/100002i/dmodel )
其中 p o s pos pos表示位置
index, i i i表示dimension。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有
sin ( α + β ) = sin α cos β + cos α sin β cos ( α + β ) = cos α cos β − sin α sin β \sin (\alpha+\beta)=\sin \alpha \cos \beta+\cos \alpha \sin \beta\\ \cos (\alpha+\beta)=\cos \alpha \cos \beta-\sin \alpha \sin \beta sin(α+β)=sinαcosβ+cosαsinβcos(α+β)=cosαcosβ−sinαsinβ
这表明位置 p + k p+k p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。在其他
NLP论文中,大家也都看过position embedding,通常是一个训练的向量,但是position embedding只是extra features,有该信息会更好,但是没有性能也不会产生极大下降,因为RNN、CNN本身就能够捕捉到位置信息,但是在Transformer模型中,Position Embedding是位置信息的唯一来源,因此是该模型的核心成分,并非是辅助性质的特征。也可以采用训练的
position embedding,但是试验结果表明相差不大,因此论文选择了sin position embedding,因为
- 这样可以直接计算embedding而不需要训练,减少了训练参数
- 这样允许模型将position embedding扩展到超过了training set中最长position的position,例如测试集中出现了更大的position,sin position embedding依然可以给出结果,但不存在训练到的embedding。

Why Self-Attention
这里将Self-Attention layers和recurrent/convolutional layers来进行比较,来说明Self-Attention的好处。假设将一个输入序列 ( x 1 , x 2 , … , x n ) (x_1,x_2,\ldots,x_n) (x1,x2,…,xn)分别用
- Self-Attention Layer
- Recurrent Layer
- Convolutional Layer
来映射到一个相同长度的序列 ( z 1 , z 2 , … , z n ) (z_1,z_2,\ldots,z_n) (z1,z2,…,zn),其中 x i , z i ∈ R d x_i,z_i \in \mathbb R^{d} xi,zi∈Rd
我们分析下面三个指标:
每一层的
计算复杂度能够被
并行的计算,用需要的最少的顺序操作的数量来衡量网络中long-range dependencies的path length,在处理序列信息的任务中很重要的在于学习long-range dependencies。影响学习长距离依赖的关键点在于前向/后向信息需要传播的步长,输入和输出序列中路径越短,那么就越容易学习long-range dependencies。因此我们比较三种网络中任何输入和输出之间的最长path length
结果如下所示

并行计算
Self-Attention layer用一个常量级别的顺序操作,将所有的positions连接起来
Recurrent Layer需要 O ( n ) O(n) O(n)个顺序操作
计算复杂度分析
如果 序 列 长 度 n < 表 示 维 度 d 序列长度n< 表示维度 d 序列长度n<表示维度d,Self-Attention Layer比recurrent layers快,这对绝大部分现有模型和任务都是成立的。
为了提高在序列长度很长的任务上的性能,我们对Self-Attention进行限制,只考虑输入序列中窗口为 r r r的位置上的信息,这称为Self-Attention(restricted), 这会增加maximum path length到 O ( n / r ) O(n/r) O(n/r)。
length path
如果卷积层kernel width k < n k<n k<n,并不会将所有位置的输入和输出都连接起来。这样需要 O ( n / k ) O(n/k) O(n/k)个卷积层或者 O ( l o g k ( n ) ) O(log_k(n)) O(logk(n))个dilated convolution,增加了输入输出之间的最大path length。
卷积层比循环层计算复杂度更高,是 k k k倍。但是Separable Convolutions将减小复杂度。
同时self-attention的模型可解释性更好(interpretable).
参考文献
论文地址:Attention Is All You Need
语义分割之Dual Attention Network for Scene Segmentation - Hebye - 博客园
论文解读:Attention is All you need - 知乎
论文笔记:Attention is all you need - 简书
有时间再添加的参考文献
Attention Is All You Need_哆啦咪~fo-CSDN博客