文章目录
SpringBoot与数据访问
对于数据访问层,无论是SQL还是NOSQL,SpringBoot默认采用整合 Spring Data的方式进行统一处理,添加大量自动配置,屏蔽了很多设置。在这其中,SpringBoot引入各种xxxTemplate,xxxRepository来简化我们对数据访问层的操作。对我们来说只需要进行简单的设置即可。
SpringBoot使用如下三个数据访问方式
- JDBC
- MyBatis
- JPA
SpringBoot中使用JDBC
- 新建一个项目测试:springboot_data_jdbc ; 引入相应的模块!基础模块
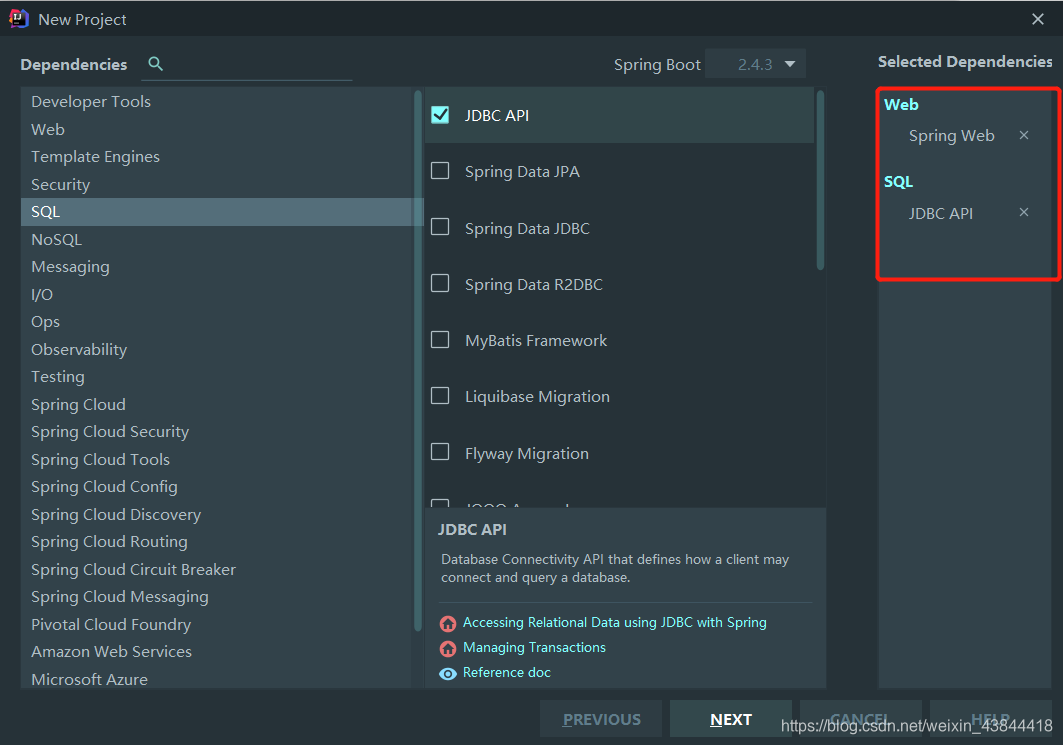
- 项目建好之后,发现自动帮我们导入了如下的启动器:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
- 编写yaml配置文件连接数据库;
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://localhost:3306/ssm?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.cj.jdbc.Driver
- 配置完这一些东西后,我们就可以直接去使用了,因为SpringBoot已经默认帮我们进行了自动配置;去测试类测试一下
@SpringBootTest
class SrpingBootDataJdbc1ApplicationTests {
//DI注入数据源
@Autowired
DataSource dataSource;
@Test
void contextLoads() throws SQLException {
//看一下默认数据源
System.out.println(dataSource.getClass());
//获得连接
Connection connection = dataSource.getConnection();
System.out.println(connection);
//关闭连接
connection.close();
}
}
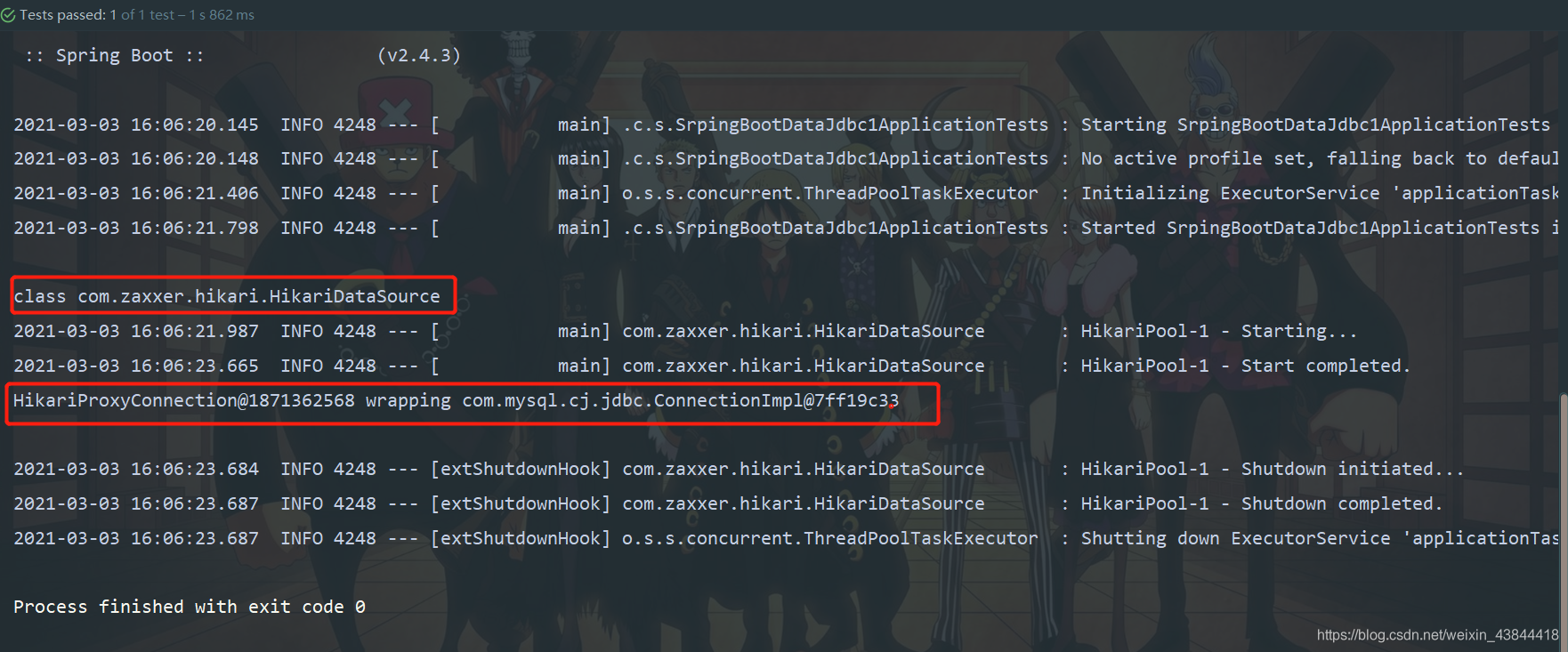
这里我们可以看到控制台输出日志,我们可以知道,SpringBoot默认使用的是class com.zaxxer.hikari.HikariDataSource作为数据源,而数据源的相关配置都在DataSourceProperties里面。
自动配置原理
我们来全局搜索一下,找到数据源的所有自动配置都在 :DataSourceConfiguration文件:

这里导入的类都在DataSourceConfiguration配置类下,可以看出 Spring Boot 2.x 默认使用HikariDataSource 数据源,而以前版本,如 Spring Boot 1.x默认使用org.apache.tomcat.jdbc.pool.DataSource 作为数据源;
HikariDataSource 号称 Java WEB 当前速度最快的数据源,相比于传统的 C3P0 、DBCP、Tomcat jdbc 等连接池更加优秀;
- 首先按照惯例,还是找到jdbc的自动配置类,然后通过查阅自动配置类进行分析,而jdbc的自动配置类就是
org.springframework.boot.autoconfigure.jdbc - 参考
DataSourceConfiguration,根据配置创建数据源,默认使用Tomcat连接池;可以使用spring.datasource.type指定自定义的数据源类型; - SpringBoot默认可以支持的数据源如下;
- org.apache.tomcat.jdbc.pool.DataSource
- HikariDataSource
- BasicDataSource
既然有默认的数据源,我们当然可以进行自定义数据源类型
/**
* Generic DataSource configuration.
*/
@ConditionalOnMissingBean(DataSource.class)
@ConditionalOnProperty(name = "spring.datasource.type")
static class Generic {
@Bean
public DataSource dataSource(DataSourceProperties properties) {
//使用DataSourceBuilder创建数据源,利用反射创建响应type的数据源,并且绑定相关属性
return properties.initializeDataSourceBuilder().build();
}
}
- DataSourceInitializer:ApplicationListener;
- 作用:
- runSchemaScripts();运行建表语句;
- runDataScripts();运行插入数据的sql语句;
- 作用:
默认只需要将文件命名为:
schema-*.sql、data-*.sql
默认规则:schema.sql,schema-all.sql;
可以使用
schema:
- classpath:department.sql
指定位置
操作数据库:自动配置了JdbcTemplate操作数据库
- 编写JdbcController:
@Controller
@RequestMapping("/jdbc")
public class JdbcController {
@Autowired
JdbcTemplate jdbcTemplate;
@ResponseBody
@GetMapping("/list")
public List<Map<String, Object>> userList(){
String sql = "select * from account";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
return maps;
}
}
//其他的方法大家有兴趣可以自己添加
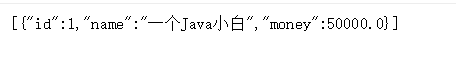
整合Druid数据源
Java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,又不得不使用数据库连接池。
Druid 是阿里巴巴开源平台上一个数据库连接池实现,结合了 C3P0、DBCP 等 DB 池的优点,同时加入了日志监控。
Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
Spring Boot 2.0 以上默认使用 Hikari 数据源,可以说 Hikari 与 Driud 都是当前 Java Web 上最优秀的数据源,我们来重点介绍 Spring Boot 如何集成 Druid 数据源,如何实现数据库监控。
配置数据源
- 导入依赖
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
-
切换数据源;通过 spring.datasource.type 指定数据源。

-
数据源切换之后,在测试类中注入 DataSource,然后获取到它,输出一看便知是否成功切换;

-
切换成功!既然切换成功,就可以设置数据源连接初始化大小、最大连接数、等待时间、最小连接数 等设置项;
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://localhost:3306/springboot?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.cj.jdbc.Driver
#自定义数据源
type: com.alibaba.druid.pool.DruidDataSource
# 数据源其他配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
server:
port: 8081
- 现在需要自己为 DruidDataSource 绑定全局配置文件中的参数,再添加到容器中,而不再使用 Spring Boot 的自动生成了;我们需要 自己添加 DruidDataSource 组件到容器中,并绑定属性;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid(){
return new DruidDataSource();
}
}
- 去测试类中测试一下
@SpringBootTest
class SrpingBootDataJdbc1ApplicationTests {
//DI注入数据源
@Autowired
DataSource dataSource;
@Test
void contextLoads() throws SQLException {
//获得连接
Connection connection = dataSource.getConnection();
DruidDataSource druidDataSource = (DruidDataSource) dataSource;
System.out.println("druidDataSource 数据源最大连接数:" + druidDataSource.getMaxActive());
System.out.println("druidDataSource 数据源初始化连接数:" + druidDataSource.getInitialSize());
//关闭连接
connection.close();
}
}
- 运行结果:

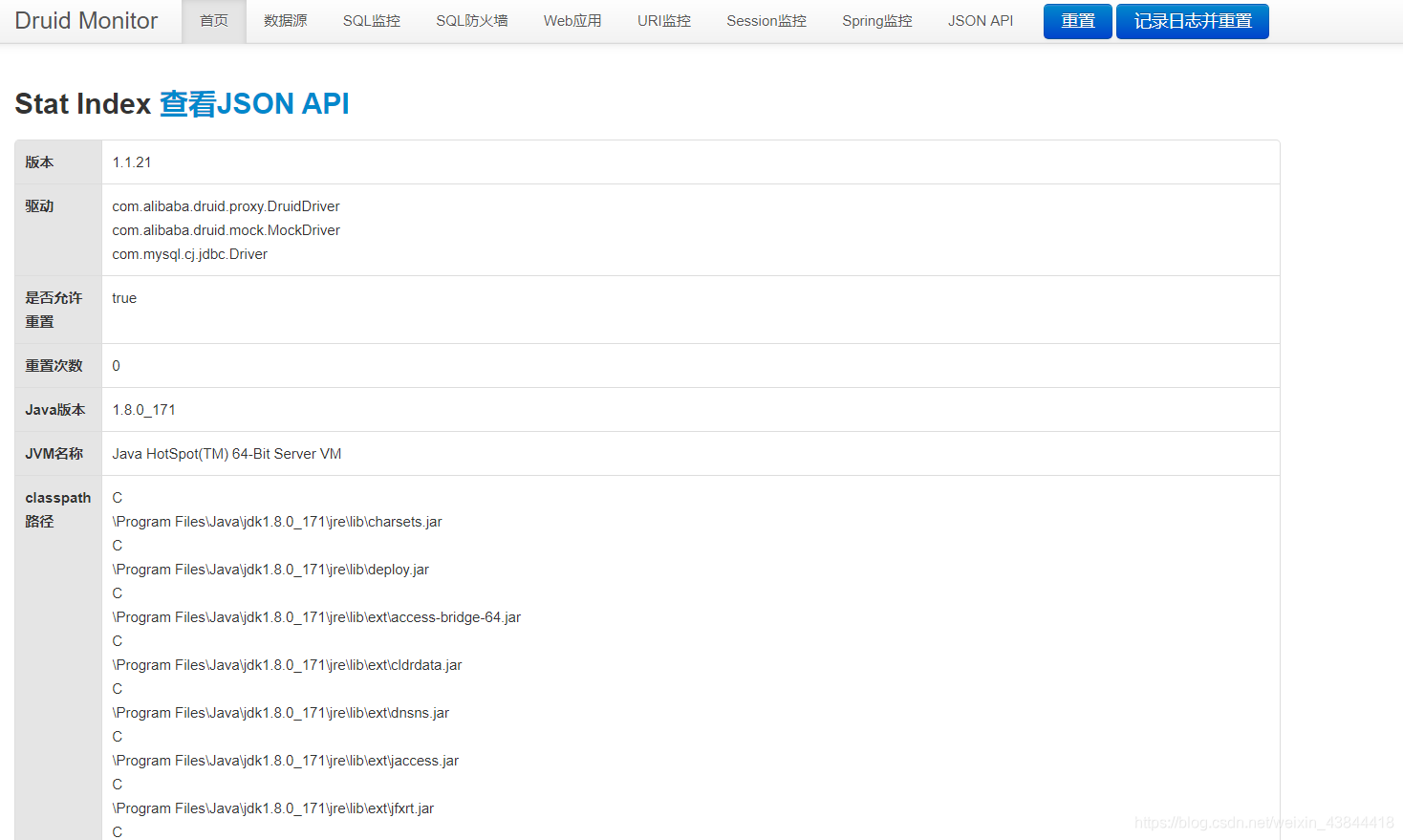
配置Druid数据源监控
- Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看,类似安装 路由器 时,人家也提供了一个默认的 web 页面。
所以第一步需要设置 Druid 的后台管理页面,比如 登录账号、密码 等;配置后台管理;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid(){
return new DruidDataSource();
}
//配置Druid的监控
//1、配置一个管理后台的Servlet
//配置 Druid 监控管理后台的Servlet;
//内置 Servlet 容器时没有web.xml文件,所以使用 Spring Boot 的注册 Servlet 方式
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
Map<String, String> initParam = new HashMap<>();
initParam.put("loginUsername","admin");//后台管理界面的登录账号
initParam.put("loginPassword","123456");//后台管理界面的登录密码
initParam.put("allow","");//默认就是允许所有访问
//deny:Druid 后台拒绝谁访问
//initParams.put("xiaozhang", "192.168.1.20");表示禁止此ip访问
bean.setInitParameters(initParam);
return bean;
}
//2、配置一个web监控的filter
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
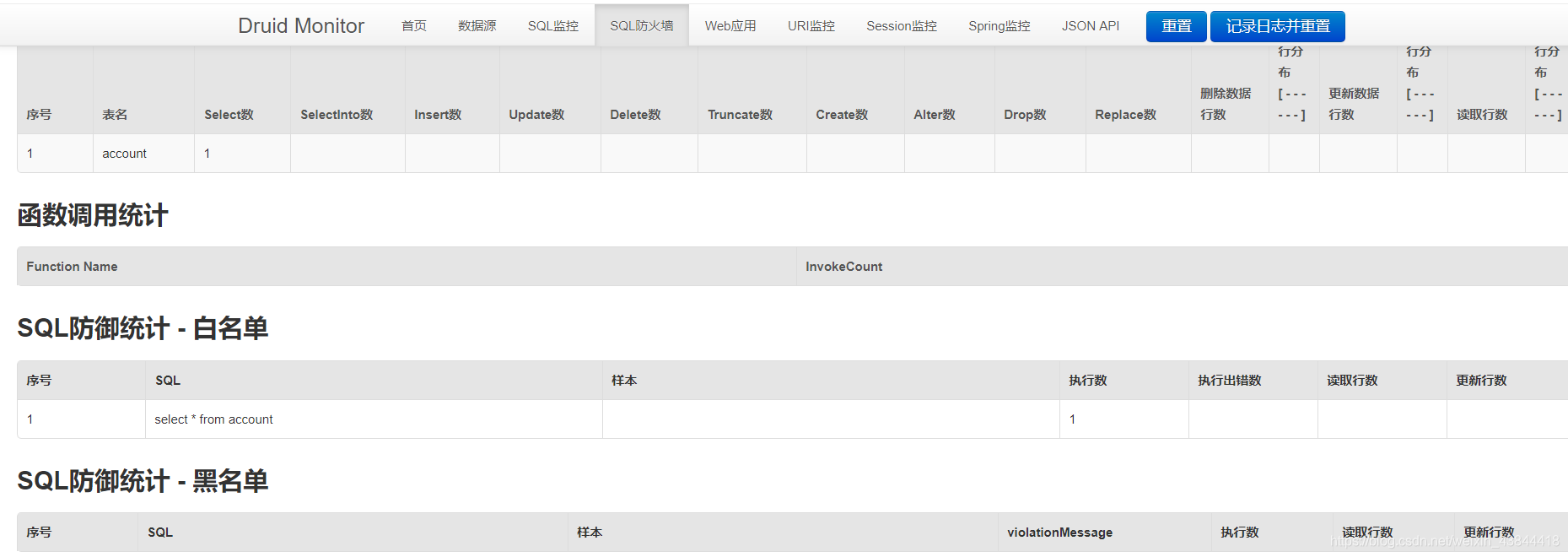
我们运行之前的查询之后可以发现:
SpringBoot整合MyBatis
- 导入 MyBatis 所需要的依赖
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
- 配置数据库连接信息
跟上面整合Druid的一样
- 给数据库建表
- 创建JavaBean,就是根据数据表的属性来创建,属性名最好跟数据库的属性名对的上。
注解版
- 创建mapper目录以及对应的 Mapper 接口
@Mapper//指定这是一个操作数据库的mapper
public interface UserMapper {
@Select("select * from user where id=#{id}")
public User getUserById(Integer id);
@Delete("delete from user where id=#{id}")
public int deleteUserById(Integer id);
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into user(username) values(#{username})")
public int insertUser(User user);
@Update("update user set username=#{username} where id=#{id}")
public int updateUser(User user);
}
- 编写控制类
@RestController
public class UserController {
@Autowired
UserMapper userMapper ;
@GetMapping("/user/{id}")
public User getUser(@PathVariable("id") Integer id){
return userMapper .getUserById(id);
}
@GetMapping("/user")
public User insertUser(User user){
userMapper .insertUser(user);
return user;
}
}
-
然后在浏览器输入localhost:8080/user/id

-
当我们的实体类的属性名跟数据库的不一致时,会查不出数据等,以前xml的时候可以设置别名,那现在要怎么办呢?
-
我们可以自定义MyBatis的配置规则;给容器中添加一个
ConfigurationCustomizer;
@org.springframework.context.annotation.Configuration
public class MyBatisConfig {
@Bean
public ConfigurationCustomizer configurationCustomizer(){
return new ConfigurationCustomizer(){
@Override
public void customize(Configuration configuration) {
configuration.setMapUnderscoreToCamelCase(true);
}
};
}
}
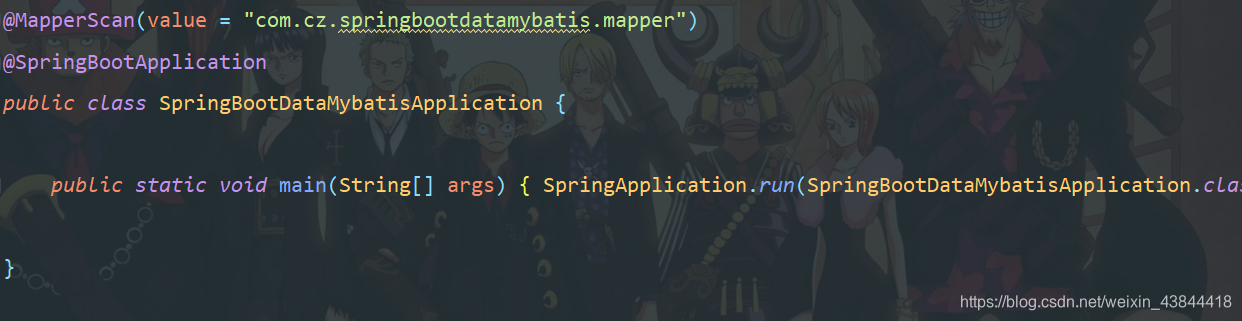
- 当我们有很多Mapper的时候,每个Mapper都要弄一个@Mapper注解。我们可以在主文件中加上:
配置文件版
mybatis:
config-location: classpath:mybatis/mybatis-config.xml 指定全局配置文件的位置
mapper-locations: classpath:mybatis/mapper/*.xml 指定sql映射文件的位置
- 更多使用参照Mybatis的对SpringBoot的官方文档
整合SpringData JPA
SpringData为我们提供使用统一的API来对数据访问层进行操作;这主要是Spring Data Commons项目来实现的。Spring Data Commons让我们在使用关系型或者非关系型数据访问 技术时都基于Spring提供的统一标准,标准包含了CRUD(创建、获取、更新、删除)、查询、 排序和分页的相关操作。

而且SpringDataJPA有着统一的Repository接口如
Repository<T, ID extends Serializable>统一接口RevisionRepository<T, ID extends Serializable, N extends Number & Comparable>基于乐观 锁机制CrudRepository<T, ID extends Serializable>基本CRUD操作PagingAndSortingRepository<T, ID extends Serializable>:基本CRUD及分页
整合SpringData JPA
- 先引入我们的依赖,引入依赖之后,和原先的数据访问方式不同的是,我们可以编写一个实体类(bean)和数据表进行映射,并且配置好映射关系;
//使用JPA注解配置映射关系
@Entity //告诉JPA这是一个实体类(和数据表映射的类)
@Table(name = "tbl_user") //@Table来指定和哪个数据表对应;如果省略默认表名就是user;
public class User {
@Id //这是一个主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//自增主键
private Integer id;
@Column(name = "last_name",length = 50) //这是和数据表对应的一个列
private String lastName;
@Column //省略默认列名就是属性名
private String email;
- 创建好实体类并配置好映射关系之后,我们接着编写一个Dao接口来操作实体类对应的数据表(Repository)
//继承JpaRepository来完成对数据库的操作
public interface UserRepository extends JpaRepository<User,Integer> {
}
- 我们jpa默认使用的hibernate,所以我们可以在配置文件中进行如下基本的配置
spring:
jpa:
hibernate:
# 更新或者创建数据表结构
ddl-auto: update
# 控制台显示SQL
show-sql: true