想学习字符串的切片,需要了解字符串的功能,这篇文章先开始说说字符串。然后集合练习,希望能够给你帮助。不要忘了点个赞哦!
字符串的常见方法:
|-- capitalize() # 首字母大写
|-- center() # 居中对齐
|-- ljust() # 左对齐
|-- rjust() # 右对齐
|-- count() # 统计字符串中出现的符号的次数
|-- startswith() # 以什么开始
|-- endswith() # 以什么结尾
|-- find() # 查找某种符号第一次出现的位置,如果没有改符号,则返回-1
|-- index() # 查找某种符号第一次出现的位置,如果没有改符号,则抛出异常
|-- rfind() # 其他都一样,找最后一个
|-- rindex() # 其他都一样,找最后一个
|-- join() # 按照特定的符号连接元素,组成字符串
|-- split() # 将字符串按照特定符号分隔成列表
|-- lower() # 将字符串转换小写
|-- upper() # 将字符串转换为大写
|-- strip() # 清除字符串两侧的空格
|-- lstrip() # 清除字符串左侧的空格
|-- rstrip() # 清除字符串右侧的空格
|-- replace() # 替换字符串
|-- title() # 将字符串转换为符合标题格式的
translate配合maketrans可以实现简单加密效果(类似于凯撒加密)
|-- isalnum # 只能由大小写字母、数字组成
|-- isalpha # 只能由大小写字母
|-- isascii # 只能由ASCII表中符号组成
|-- isdecimal # 数字
|-- isdigit # 数字
|-- isnumeric # 数字
|-- isidentifier # 有效符号
|-- islower # 小写字母
|-- isupper # 大写字母
|-- isprintable #
|-- isspace # 是否是空格
|-- istitle # 是否是标题
|-- encode(编码规范) # 编码的,将字符串转换为字节数据
|-- decode() # 解码函数,将字节转换为字符串的方法
注意:编码和解码使用同一种编码规则,推荐使用utf-8
切片:
有序序列(列表、元组、字符串):切割、截取等操作
sequence[start:] # 从start位置开始截取,截取到末尾
sequence[start:end] # [start:end),是前闭后开区间
sequence[start:end:step] # step表示步长,注意:如果step为-1,表示从右向左切
需要注意的,切片支持负索引,如果使用负数,表示从右向左的下标
1.根据完整的路径从路径中分离文件路径、文件名及扩展名
'''
作者:lsff
time:2021.1.21
'''
ls="E:\jhj\IT作业\tist.py"
def file(ls):
way=ls[0:11]
name=ls[11:15]
extension=ls[16:]
print(way,name,extension)
file(ls)
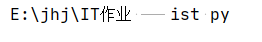
2.获取字符串中汉字的个数
'''
作者:lsff
time:2021.1.21
'''
ls="E:\jhj\IT作业\tist.py"
def number(l):
count = 0
for item in l:
if 0x4E00 <= ord(item) <= 0x9FA5:
count += 1
return count
print(number(ls))
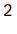
3.将字母全部转换为大写或小写
'''
作者:lsf
time:2021.1.21
'''
ls="E:\jhj\IT作业\tist.py"
print(ls.upper())
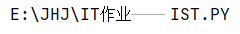
4.根据标点符号对字符串进行分行
'''
作者:lsf
time:2021.1.21
'''
ls="E:\jhj\IT作业\tist.py"
print(ls.split("."))
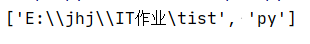
5.去掉字符串数组中每个字符串的空格
'''
作者:lsf
time:2021.1.21
'''
ls=" E:\jhj\IT作业\ist.py "
print(ls.strip())
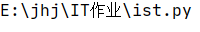
6.随意输入你心中想到的一个书名,然后输出它的字符串长度。 (len()属性:可以得字符串的长度)
'''
作者:lsf
time:2021.1.21
'''
book=str(input("请输入书名:"))
print(len(book))

7.两个学员输入各自最喜欢的游戏名称,判断是否一致,如
果相等,则输出你们俩喜欢相同的游戏;如果不相同,则输
出你们俩喜欢不相同的游戏。
'''
作者:lsf
time:2021.1.21
'''
perple1=str(input("请输入游戏:"))
perple2=str(input("请输入游戏:"))
for i in perple1 :
for y in perple2 :
if i == y :
print("游戏一样")
else:
print("游戏不一样")

8.上题中两位同学输入 lol和 LOL代表同一游戏,怎么办?
game1=str(input("请输入游戏名称:"))
game2=str(input("请输入游戏名称:"))
if game1.upper() == game2.upper():
print("游戏一样")
else:
print("游戏不一样")

9.让用户输入一个日期格式如“2008/08/08”,将 输入的日
期格式转换为“2008年-8月-8日”。
time=input("请输入日期:(格式)2009/08/08")
s1=time.split("/")
newtime="{}年-{}月-{}日".format(s1[0],int(s1[1]),int(s1[2]))
print(newtime)
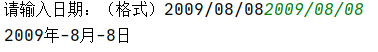
10.接收用户输入的字符串,将其中的字符进行排序(升
序),并以逆序的顺序输出,“cabed”→"abcde"→“edcba”。
ls='cabed'
l=list(ls)
l.sort()
print(l)
l.reverse()
print(l)
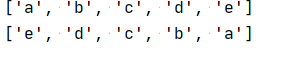
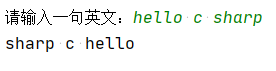
11.接收用户输入的一句英文,将其中的单词以反序输
出,“hello c sharp”→“sharp c hello”。
english=input("请输入一句英文:")
x=english.split(" ")
y=x[::-1]
x1=" ".join(y)
print(x1)
12.从请求地址中提取出用户名和域名
http://www.163.com?userName=admin&pwd=123456、
url='http://www.163.com?userName=admin&pwd=123456'
ls = url.split("/")
s1 = ls[2]
ls2 = s1.split("?")
print("域名是:{}".format(ls2[0]))
s1 = ls2[1]
ls3 = s1.split("&")
s1 = ls3[0]
ls4 = s1.split("=")
print("用户名是:{}".format(ls4[1]))
13.有个字符串数组,存储了10个书名,书名有长有短,现
在将他们统一处理,若书名长度大于10,则截取长度8的
子串并且最后添加“...”,加一个竖线后输出作者的名字。
```clike
ls = ["我自然也欢迎您","遥远的老天爷","红尘往市不在回首嘿嘿黑","活着","白鹿原之青青草原112"] ##10个书名太多了,我只存了几个
dir = {
"我自然也欢迎您":"xiaoluo","遥远的老天爷":"haoboxu","红尘往市不在回首嘿嘿黑":"xuahobo","活着":"haobo","白鹿原之青青草原112":"hahah"}
for i in range(0,len(ls)):
s = ls[i]
if len(s) > 10:
s = s[0:9]+"..._"+str(dir[ls[i]])
ls[i] = s
print(ls)
14.让用户输入一句话,找出所有"呵"的位置。
s = input("请输入一段话!")
ls = []
for i in range(0,len(s)):
if s[i] == "呵":
ls.append(i)
print("呵的位置是%s"%ls)

15.让用户输入一句话,找出所有"呵呵"的位置。
s = input("请输入一段话!")
ls = []
for i in range(0,len(s)-1):
if s[i] == "呵" and s[i+1]=="呵":
ls.append(i)
print("呵呵的位置是%s"%ls)

16.让用户输入一句话,判断这句话中有没有邪恶,如果有邪
恶就替换成这种形式然后输出,如:“老牛很邪恶”,输出后变
成”老牛很**”;
word = input("请输入字符串:")
print("邪恶消失后:{}".format(word.replace("邪恶","**")))

17.判断一个字符是否是回文字符串(面试题)
“1234567654321”
“上海自来水来自海上”
#双指针
def is_palindrome(count):
for i in range(0,len(count)//2):
if count[i] != count[len(count)-i-1]:
return False
return True
word="上海自来水来自海上"
print(is_palindrome(word))
18,遍历磁盘
import sys
import os
def file(url):
files=os.listdir(url)
for i in files :
path=os.path.join(url,i)
if os.path.isfile(path) :
print(path)
elif os.path.isdir(path) :
#如果是文件夹,递归遍历
file(path)
if len(sys.argv) <2 :
print("必须传递参数")
else:
p=sys.argv[1]
file(p)
file("E:\jhj\IT作业\Linux私房菜")

19.使用os模块在磁盘上判断文件夹【c:/a/b】是否存在
如果不存在,则创建文件``
import os
if not os.path.exists('c:/a/b'): #判断所在目录下是否有该文件名的文件夹
os.makedirs('c:/a/b') #创建多级目录用mkdirs,单击目录mkdir
else:
if os.path.exists('file'):
print('the file exists')
else:
os.chdir('c:/a/b')
os.mknod("b.txt") #创建空文件
