一、组合数据类型container objects

组合数据类型container objects:能够表示多个数据的类型
集合类型:集合类型是一个元素集合,元素无序不重不变
序列类型:序列类型是一个元素向量,元素有序可重可变可不变。序列类型的典型代表是列表类型、元组类型、字符串类型(但元组一旦定义,元素就不能变了)
映射类型:映射类型是“键-值”数据项的组合,元素无序不重键不可变值可变可不变,每个元素是一个键值对。映射类型的典型代表是字典类型
集合类型是一个具体的数据类型名称,而序列类型和映射类型是一类数据类型的总称。
不可变数据类型:immutable,如数字、元组、字符串
可变数据类型:mutable,如列表、集合、字典
可迭代对象:iterable,如range()、序列(列表元组字符串)、集合、字典、文件,generator
不可迭代对象:如数字
很多函数的参数以及返回值都是iterable:map(), filter() ,zip() ,range(), dict.keys(), dict.items() 和 dict.values()
二、字符串Python tutorial
从九个方面展开:基,建,增,删,改,查,操,切,复
(一)基:基本概念
字符串:字符的序列sequence
字符串类名:str

(二)建:创建、定义
1、通过一对单引号、一对双引号创建字符串
2、通过三对单引号、三对双引号创建字符串
3、转义符“\”

4、通过str()创建字符串

(三)改、删
字符串是immutable的,一旦创建就不能被更改。

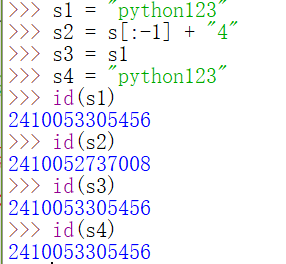
变相修改:(实际上,这不是改,而是新建了一个新的字符串)

这里,通过id()查看变量的内存地址,可以看到变量的值和变量引用的内存地址的区别。s1,s4,同一个字符串,在内存中只有一份
Python中:
- 不可变数据类型:immutable,如数字、元组、字符串
- 可变数据类型:mutable,如列表、集合、字典
- 可以使用id()的进行查看(id()用来返回数据的内存地址)
- 可变和不可变说的是变量的值和变量引用的内存地址
- 不可变数据类型,变量值变化,变量引用地址就会变化,即该地址的值不变
- 可变数据类型,变量值变化,变量引用地址不变,即该地址的值可变
(四)查
1、正向递增序号(0 ~ n-1),反向递减序号(-1 ~ -n)
2、索引查单个,序号超出范围会报错IndexError
3、切片查多个,序号超出范围,取实际长度
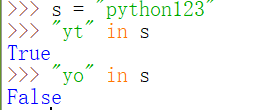
 4、查询子串是否存在、在不在,in,not in。 (这个在所有组合数据类型中都有)
4、查询子串是否存在、在不在,in,not in。 (这个在所有组合数据类型中都有)
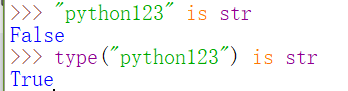
5、查询identity是否是,is, is not
6、查询以XX开头、结尾

7、查询序号
str.index(object[, start, end])返回一个int,默认从序号0开始查

8、查询子串出现次数
str.count(sub,start,end),返回一个int,默认从序号0开始查找,包含start本身

9、正则表达式查找
略。
(五)操,字符串操作
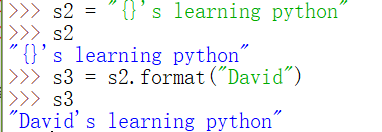
1、格式化输出,可以用str.format()

2、格式化拆分
str.split(sep)返回一个列表,sep可以是单个或多个字符,无sep默认以空格拆分
注意返回的列表不含拆分字符sep

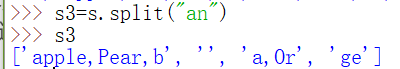
3、合并字符串
str.join(iterable),返回一个字符串。将iterable变量除最后一个元素外的每一个元素后增加一个str字符

4、大小写
str.title(),把str每个首字母大写,每个非首字母小写

str.capitalize(),把str最开头的字母大写,其余全部小写

str.upper()和str.lower()是全部大小写,返回一个新str,原str不变

str.swapcase(),把大的变小的,把小的变大的

str.isupper(), str.islower()

5、去掉左/右边的内容
str.strip(chars),去掉左边和右边的chars,返回一个str
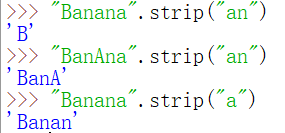
str.lstrip(chars), str.rstrip(chars)去掉左边或右边的chars,返回一个str

6、加乘法,返回一个str

7、替换
str.replace(old,new),返回一个str

8、比较
从左往右一个一个比较,如果一边完了,另一边还有,还剩的大
按ASCII码值,ord()可以把单字符转换成ASCII,小写字母大于大写字母

>>> help(str)
Help on class str in module builtins:
class str(object)
| str(object='') -> str
| str(bytes_or_buffer[, encoding[, errors]]) -> str
|
| Create a new string object from the given object. If encoding or
| errors is specified, then the object must expose a data buffer
| that will be decoded using the given encoding and error handler.
| Otherwise, returns the result of object.__str__() (if defined)
| or repr(object).
| encoding defaults to sys.getdefaultencoding().
| errors defaults to 'strict'.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __format__(self, format_spec, /)
| Return a formatted version of the string as described by format_spec.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mod__(self, value, /)
| Return self%value.
|
| __mul__(self, value, /)
| Return self*value.
|
| __ne__(self, value, /)
| Return self!=value.
|
| __repr__(self, /)
| Return repr(self).
|
| __rmod__(self, value, /)
| Return value%self.
|
| __rmul__(self, value, /)
| Return value*self.
|
| __sizeof__(self, /)
| Return the size of the string in memory, in bytes.
|
| __str__(self, /)
| Return str(self).
|
| capitalize(self, /)
| Return a capitalized version of the string.
|
| More specifically, make the first character have upper case and the rest lower
| case.
|
| casefold(self, /)
| Return a version of the string suitable for caseless comparisons.
|
| center(self, width, fillchar=' ', /)
| Return a centered string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| count(...)
| S.count(sub[, start[, end]]) -> int
|
| Return the number of non-overlapping occurrences of substring sub in
| string S[start:end]. Optional arguments start and end are
| interpreted as in slice notation.
|
| encode(self, /, encoding='utf-8', errors='strict')
| Encode the string using the codec registered for encoding.
|
| encoding
| The encoding in which to encode the string.
| errors
| The error handling scheme to use for encoding errors.
| The default is 'strict' meaning that encoding errors raise a
| UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
| 'xmlcharrefreplace' as well as any other name registered with
| codecs.register_error that can handle UnicodeEncodeErrors.
|
| endswith(...)
| S.endswith(suffix[, start[, end]]) -> bool
|
| Return True if S ends with the specified suffix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| suffix can also be a tuple of strings to try.
|
| expandtabs(self, /, tabsize=8)
| Return a copy where all tab characters are expanded using spaces.
|
| If tabsize is not given, a tab size of 8 characters is assumed.
|
| find(...)
| S.find(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| format(...)
| S.format(*args, **kwargs) -> str
|
| Return a formatted version of S, using substitutions from args and kwargs.
| The substitutions are identified by braces ('{' and '}').
|
| format_map(...)
| S.format_map(mapping) -> str
|
| Return a formatted version of S, using substitutions from mapping.
| The substitutions are identified by braces ('{' and '}').
|
| index(...)
| S.index(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| isalnum(self, /)
| Return True if the string is an alpha-numeric string, False otherwise.
|
| A string is alpha-numeric if all characters in the string are alpha-numeric and
| there is at least one character in the string.
|
| isalpha(self, /)
| Return True if the string is an alphabetic string, False otherwise.
|
| A string is alphabetic if all characters in the string are alphabetic and there
| is at least one character in the string.
|
| isascii(self, /)
| Return True if all characters in the string are ASCII, False otherwise.
|
| ASCII characters have code points in the range U+0000-U+007F.
| Empty string is ASCII too.
|
| isdecimal(self, /)
| Return True if the string is a decimal string, False otherwise.
|
| A string is a decimal string if all characters in the string are decimal and
| there is at least one character in the string.
|
| isdigit(self, /)
| Return True if the string is a digit string, False otherwise.
|
| A string is a digit string if all characters in the string are digits and there
| is at least one character in the string.
|
| isidentifier(self, /)
| Return True if the string is a valid Python identifier, False otherwise.
|
| Use keyword.iskeyword() to test for reserved identifiers such as "def" and
| "class".
|
| islower(self, /)
| Return True if the string is a lowercase string, False otherwise.
|
| A string is lowercase if all cased characters in the string are lowercase and
| there is at least one cased character in the string.
|
| isnumeric(self, /)
| Return True if the string is a numeric string, False otherwise.
|
| A string is numeric if all characters in the string are numeric and there is at
| least one character in the string.
|
| isprintable(self, /)
| Return True if the string is printable, False otherwise.
|
| A string is printable if all of its characters are considered printable in
| repr() or if it is empty.
|
| isspace(self, /)
| Return True if the string is a whitespace string, False otherwise.
|
| A string is whitespace if all characters in the string are whitespace and there
| is at least one character in the string.
|
| istitle(self, /)
| Return True if the string is a title-cased string, False otherwise.
|
| In a title-cased string, upper- and title-case characters may only
| follow uncased characters and lowercase characters only cased ones.
|
| isupper(self, /)
| Return True if the string is an uppercase string, False otherwise.
|
| A string is uppercase if all cased characters in the string are uppercase and
| there is at least one cased character in the string.
|
| join(self, iterable, /)
| Concatenate any number of strings.
|
| The string whose method is called is inserted in between each given string.
| The result is returned as a new string.
|
| Example: '.'.join(['ab', 'pq', 'rs']) -> 'ab.pq.rs'
|
| ljust(self, width, fillchar=' ', /)
| Return a left-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| lower(self, /)
| Return a copy of the string converted to lowercase.
|
| lstrip(self, chars=None, /)
| Return a copy of the string with leading whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| partition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string. If the separator is found,
| returns a 3-tuple containing the part before the separator, the separator
| itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing the original string
| and two empty strings.
|
| replace(self, old, new, count=-1, /)
| Return a copy with all occurrences of substring old replaced by new.
|
| count
| Maximum number of occurrences to replace.
| -1 (the default value) means replace all occurrences.
|
| If the optional argument count is given, only the first count occurrences are
| replaced.
|
| rfind(...)
| S.rfind(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| rindex(...)
| S.rindex(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| rjust(self, width, fillchar=' ', /)
| Return a right-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| rpartition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string, starting at the end. If
| the separator is found, returns a 3-tuple containing the part before the
| separator, the separator itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing two empty strings
| and the original string.
|
| rsplit(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| Splits are done starting at the end of the string and working to the front.
|
| rstrip(self, chars=None, /)
| Return a copy of the string with trailing whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| split(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| splitlines(self, /, keepends=False)
| Return a list of the lines in the string, breaking at line boundaries.
|
| Line breaks are not included in the resulting list unless keepends is given and
| true.
|
| startswith(...)
| S.startswith(prefix[, start[, end]]) -> bool
|
| Return True if S starts with the specified prefix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| prefix can also be a tuple of strings to try.
|
| strip(self, chars=None, /)
| Return a copy of the string with leading and trailing whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| swapcase(self, /)
| Convert uppercase characters to lowercase and lowercase characters to uppercase.
|
| title(self, /)
| Return a version of the string where each word is titlecased.
|
| More specifically, words start with uppercased characters and all remaining
| cased characters have lower case.
|
| translate(self, table, /)
| Replace each character in the string using the given translation table.
|
| table
| Translation table, which must be a mapping of Unicode ordinals to
| Unicode ordinals, strings, or None.
|
| The table must implement lookup/indexing via __getitem__, for instance a
| dictionary or list. If this operation raises LookupError, the character is
| left untouched. Characters mapped to None are deleted.
|
| upper(self, /)
| Return a copy of the string converted to uppercase.
|
| zfill(self, width, /)
| Pad a numeric string with zeros on the left, to fill a field of the given width.
|
| The string is never truncated.
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| maketrans(x, y=None, z=None, /)
| Return a translation table usable for str.translate().
|
| If there is only one argument, it must be a dictionary mapping Unicode
| ordinals (integers) or characters to Unicode ordinals, strings or None.
| Character keys will be then converted to ordinals.
| If there are two arguments, they must be strings of equal length, and
| in the resulting dictionary, each character in x will be mapped to the
| character at the same position in y. If there is a third argument, it
| must be a string, whose characters will be mapped to None in the result.
PS: source, bilibili, python123