LearnOpenGL学习笔记—PBR:IBL
结合英文原站,中文站,以及个人实践进行描述。
本项目地址点击 这里这里这里
文章中的代码基于OpenGL的参考,真正实现时使用了WebGL弄了个网页(为了交作业_(:з」∠)_)
所以文章代码不完全等于实现的代码,但是思路和解说是正确的,可以到git项目里看该项目实现“(终版)”的细致说明
0 引入
在前面一篇PBR的光照中,我们仅仅考虑了直接光照部分,仅仅考虑直接光照时求解渲染方程非常简单,只需需根据给定的光源直接计算并叠加,而不需要在法线轴向的半球方向做积分。
Image Based Lighting(以下简称IBL)是基于图像的光照,这种技术专门计算来自于周围环境的间接光照,其会把周围环境的光影信息存储在一张环境贴图中,
这个环境贴图可以是预先生成好的,也可以是运行时动态生成好的。IBL技术使得物体的光照效果与周围的环境更加融合,大大增强沉浸感。
1 渲染方程的求解
IBL的渲染方程与PBR一样,即特化的渲染方程——反射方程,如下所示:
L o ( p , ω o ) = ∫ Ω ( k d c π + D F G 4 ( ω o ⋅ n ) ( ω i ⋅ n ) ) L i ( p , ω i ) n ⋅ ω i d ω i L_o(p,\omega_o)=\int_{\Omega}(k_d\frac{c}{\pi}+\frac{DFG}{4(\omega_o\cdot n)(\omega_i\cdot n)})L_i(p,\omega_i)n\cdot \omega_id\omega_i Lo(p,ωo)=∫Ω(kdπc+4(ωo⋅n)(ωi⋅n)DFG)Li(p,ωi)n⋅ωidωi
我们实现基于物理的光照效果,本质就是要计算上面的渲染方程
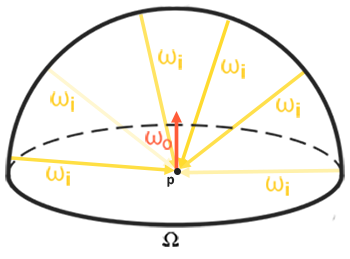
它是对半球方向 Ω \Omega Ω的所有 ω i \omega_i ωi的积分。
在前面一篇PBR中我们求解这个积分方程非常容易,因为仅考虑直接光照且光源为非面积光源时,上述的被积函数部分是一个狄拉克函数,即除了在光源方向上函数值不为0,在半球内的其余定义域该被积函数均为0,因此没有必要求半球积分。
或者说半球积分的值就等于在光源方向上的被积函数值,所以我们采用之前采用累加的处理方式。
但是在IBL中,就没有这么简单了。我们把环境贴图中的每一个像素都当作一个光源,这使得我们必须要求解半球方向的积分,即在整个半球方向采样光照信息。
如果我们直接暴力求解渲染方程的话,在每一个片元着色器上我们都要计算渲染方程的半球积分,耗费极大的性能,这对于实时性应用来说几乎不可能。
因此,为了高效地求解渲染积分方程,IBL方法将渲染方程中的积分项预先计算出来。
计算出来后并存储到指定的纹理图片上,在后面进行光照计算的时候根据相关的信息索引预先计算好的积分值,从而快速高效地求解积分。
这其实就是以空间换时间的思想。为了方便预先计算积分值,我们把公式写成如下的形式:
L o ( p , ω o ) = ∫ Ω ( k d c π + D F G 4 ( ω o ⋅ n ) ( ω i ⋅ n ) ) L i ( p , ω i ) n ⋅ ω i d ω i L_o(p,\omega_o) =\int_{\Omega}(k_d\frac{c}{\pi}+\frac{DFG}{4(\omega_o\cdot n)(\omega_i\cdot n)})L_i(p,\omega_i)n\cdot \omega_id\omega_i Lo(p,ωo)=∫Ω(kdπc+4(ωo⋅n)(ωi⋅n)DFG)Li(p,ωi)n⋅ωidωi
= ∫ Ω k d c π L i ( p , ω i ) n ⋅ ω i d ω i + ∫ Ω ( D F G 4 ( ω o ⋅ n ) ( ω i ⋅ n ) ) L i ( p , ω i ) n ⋅ ω i d ω i =\int_{\Omega}k_d\frac{c}{\pi}L_i(p,\omega_i)n\cdot \omega_id\omega_i +\int_{\Omega}(\frac{DFG}{4(\omega_o\cdot n)(\omega_i\cdot n)})L_i(p,\omega_i)n\cdot \omega_id\omega_i =∫ΩkdπcLi(p,ωi)n⋅ωidωi+∫Ω(4(ωo⋅n)(ωi⋅n)DFG)Li(p,ωi)n⋅ωidωi
上面公式的两个项,分别对应光照的漫反射部分和镜面反射部分。
我们把这两部分分开来,然后分别单独计算漫反射的积分值、镜面反射的积分值。
这个其实相当于过程是,对立方体环境贴图做一个特殊的卷积操作,计算得到的结果存储到各自指定查找表中,供后续的渲染使用。
这个就是IBL算法的核心思想,接下来我们就围绕这个核心思想展开相应的实现细节。
2 hdr文件转成cubemap
在实现积分预计算之前我们还有一件事要完成,就是获取周围环境贴图的辐射率值。
因为我们把环境贴图的每一个像素都当作一个光源,在进行积分计算时,我们要根据给定的入射方向 ω i ω_i ωi去获取该方向上辐射过来的辐射率值。
如果环境贴图是一个立方体贴图的话,这很容易实现,因为立方体贴图就是根据三维向量进行索引的。
但是在IBL中我们的环境贴图并不是一个普通的环境贴图,普通的环境贴图的像素值在低动态范围(Low Dynamic Range),即每个像素的分量不超过1.0。
IBL同样是PBR渲染方法,为了能够捕捉真实的物理光影和细节,我们的环境贴图应该是高动态范围的(High Dynamic Range)。
辐射度文件的格式(扩展名为 .hdr)存储了一张完整的立方体贴图,所有六个面数据都是浮点数,允许指定 0.0 到 1.0 范围之外的颜色值,以使光线具有正确的颜色强度。
这个文件格式使用了一个聪明的技巧来存储每个浮点值:它并非直接存储每个通道的 32 位数据,而是每个通道存储 8 位,再以 alpha 通道存放指数——虽然确实会导致精度损失,但是非常有效率,不过需要解析程序将每种颜色重新转换为它们的浮点数等效值。
下面是一个示例:

这张环境贴图是从球体投影到平面上,以使我们可以将环境信息存储到一张等距柱状投影图(Equirectangular Map) 中。
类似于广角镜头拍摄得到的画面。.hdr格式保存的不是六张独立的图片,它将6张图片从球面投影到一个二维的平面上,从而构成下面这张略带扭曲的矩形纹理图。
为了后续方便获取指定像素的纹理值,我们需要把这张矩形的hdr图转换成立方体贴图。
从hdr转换到cubemap的过程,其实就是利用球面投影到立方图上的二维平面。
可以理解为球面的纹理映射为立方体上的二维纹理(或者说球面上的点映射到立方体上二维平面上的点)。
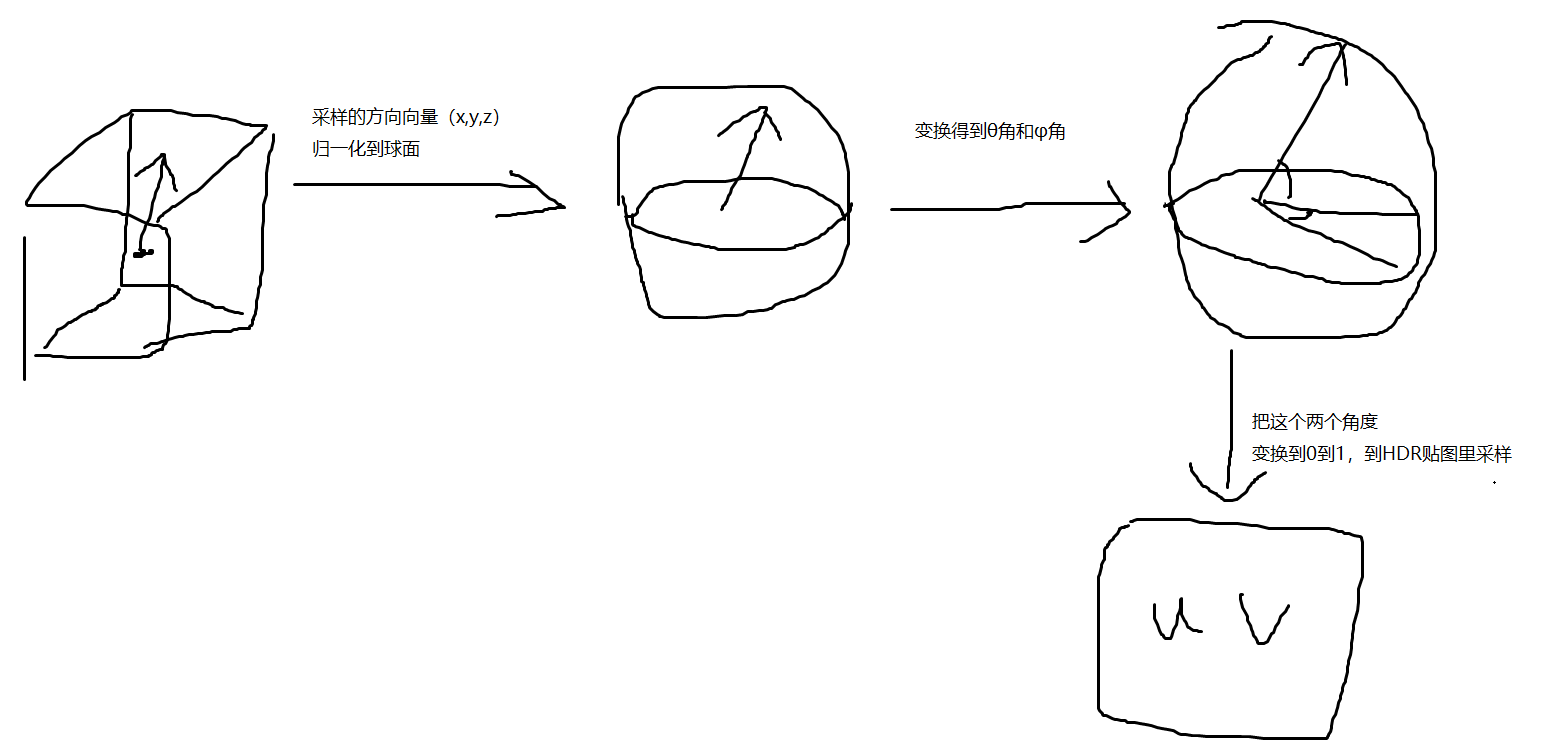
这个映射过程就是利用了球坐标和笛卡尔坐标的关系。
对于一个球心在原点的单位球体上的点 ( x , y , z ) (x,y,z) (x,y,z)
我们也可以用采用天顶角 θ θ θ(与 x z xz xz平面的夹角)和方位角 ϕ ϕ ϕ(在 x z xz xz平面上与 x x x轴的夹角)来唯一地表示,他们的关系如下:
- x = c o s ( θ ) c o s ( ϕ ) y = s i n ( θ ) z = c o s ( θ ) s i n ( ϕ ) x=cos(\theta)cos(\phi)\\ y=sin(\theta) \\ z=cos(\theta)sin(\phi) x=cos(θ)cos(ϕ)y=sin(θ)z=cos(θ)sin(ϕ)
其中 θ θ θ的取值范围为 [ − π / 2 , + π / 2 ] [-π/2,+π/2] [−π/2,+π/2], ϕ ϕ ϕ的取值范围为 [ − π , + π ] [−π,+π] [−π,+π]
我们逆运算很容易地可以分别将其映射到二维纹理坐标uv的 [ 0 , 1 ] [0,1] [0,1]
这样我们就将一个三维立方体贴图纹理坐标映射到了二维的纹理坐标,这个其实就是构建.hdr时的映射过程。
现在我们要再现这个过程,获取三维纹理坐标对应的二维纹理坐标,然后索引上面的hdr贴图,从而得到三维纹理坐标对应的像素值,并将其保存到cubemap当中。
所谓再现这个过程,也就是要将等距柱状投影图转换为立方体贴图,我们需要渲染一个(单位)立方体。
从内部将等距柱状图投影到立方体的每个面,并将立方体的六个面的图像构造成立方体贴图。
此立方体的顶点着色器只是按原样渲染立方体,并将其局部坐标作为 3D 采样向量传递给片段着色器。
代码思路示意
#version 330 core
layout (location = 0) in vec3 position;
layout (location = 1) in vec3 normal;
layout (location = 2) in vec2 texcoord;
layout (location = 3) in vec3 color;
out vec3 worldPos;
uniform mat4 viewMatrix;
uniform mat4 projectMatrix;
void main(){
worldPos = position;
gl_Position = projectMatrix * viewMatrix * vec4(position,1.0f);
}
而在片段着色器中,我们为立方体的每个部分着色,方法类似于将等距柱状投影图整齐地折叠到立方体的每个面一样。
为了实现这一点,我们先获取片段的采样方向,这个方向是从立方体的局部坐标进行插值得到的。
然后根据之前的投影过程,反过来计算得到 θ θ θ和 ϕ ϕ ϕ,投影到 [ 0 , 1 ] [0,1] [0,1]的范围,对hdr的贴图进行采样到立方体的面上
#version 330 core
in vec3 worldPos;
out vec4 fragColor;
uniform sampler2D hdrMap;
// (1/(pi/2), 1/(pi))
const vec2 invAtan = vec2(0.1591, 0.3183);
vec2 sampleSphericalMap(vec3 v)
{
vec2 uv = vec2(atan(v.z, v.x), asin(v.y));
// to [0,1].
uv *= invAtan;
uv += vec2(0.5f);
return uv;
}
void main()
{
// map 3d texcoord to 2d texcoord.
vec2 uv = sampleSphericalMap(normalize(worldPos));
// sample hdr map.
vec3 sampler = texture(hdrMap, uv).rgb;
// save to one face of cubemap.
fragColor = vec4(sampler, 1.0f);
}
通过上面的步骤,就将一个二维的hdr贴图转换成cubemap,方便我们后续的使用。
有了这个高动态范围的环境贴图,接下来我们就展开漫反射积分和镜面反射积分的预计算。
3 预计算漫反射积分
首先来看渲染方程中的漫反射积分部分,把它单独拎出来:
∫ Ω k d c π L i ( p , ω i ) n ⋅ ω i d ω i = k d c π ∫ Ω L i ( p , ω i ) n ⋅ ω i d ω i \int_{\Omega}k_d\frac{c}{\pi}L_i(p,\omega_i)n\cdot \omega_id\omega_i =k_d\frac{c}{\pi}\int_{\Omega}L_i(p,\omega_i)n\cdot \omega_id\omega_i ∫ΩkdπcLi(p,ωi)n⋅ωidωi=kdπc∫ΩLi(p,ωi)n⋅ωidωi
上面的积分公式中,积分变量为 ω i \omega_i ωi
k d k_d kd和 c π \frac{c}{\pi} πc都和积分无关,故可以提出积分外
我们实际上要求积分的被积函数是 L i ( p , ω i ) n ⋅ ω i L_i(p,\omega_i)n\cdot \omega_i Li(p,ωi)n⋅ωi
假设 P P P在原点,则对于每一个半球方向,也就是确定的 n n n,积分值仅仅取决于
ω i ω_i ωi。
因此,我们遍历所有的 n n n,然后预先计算其积分值 ∫ Ω L i ( p , ω i ) n ⋅ ω i d ω i \int_{\Omega}L_i(p,\omega_i)n\cdot \omega_id\omega_i ∫ΩLi(p,ωi)n⋅ωidωi,存储到到一张cubemap当中.
最后渲染时直接用 n n n去采样这个cubemap得到预先计算好的积分值,这个就是预计算漫反射积分的思路。
n n n是给定法线向量,它的取值范围就所有方向,相当于一个球心在原点的单位球体上的所有点。
为了预积分遍历所有的 n n n,我们送入一个立方体进行预计算的渲染,不需要球体,因为立方体的顶点归一化normalize之后也就是对应的球面上的点。
然后在片元着色器根据这个 n n n进行半球方向的积分,最后存储到cubemap当中。同样的,我们需要绘制6次,每次绘制保存到cubemap的六个面中的一面。
关于公式当中的积分数值计算,首先需要注意的是公式当中的积分变量 ω i ω_i ωi是立体角。
为了方便计算,我们需要把它转成以天顶角 θ θ θ和方位角 ϕ ϕ ϕ为变量的表示形式。
- 在球面坐标中,一个方向向量我们通常采用 ( θ , ϕ ) (θ,ϕ) (θ,ϕ)来唯一地表示,分别是天顶角和方位角。
在衡量发光强度和辐射辐射度量学中,立体角有着广泛的应用。
立体角描述了站在某一点的观察者观测到的物体大小的尺度,它被定义为球表面截取的面积微分与球半径平方之比,单位为球面度。
显然,立体角是二维圆心角的三维扩展:
d ω = d A r 2 d\omega=\frac{dA}{r^2} dω=r2dA - 立体角通常转换为 ( θ , ϕ ) (θ,ϕ) (θ,ϕ)来表示,在单位球体上, d ω = d A d\omega=dA dω=dA
我们转换成用 ( θ , ϕ ) (θ,ϕ) (θ,ϕ)来求 d A dA dA
微分面积 d A dA dA,可以看成是一个矩形,宽和高分别为对应的弧长
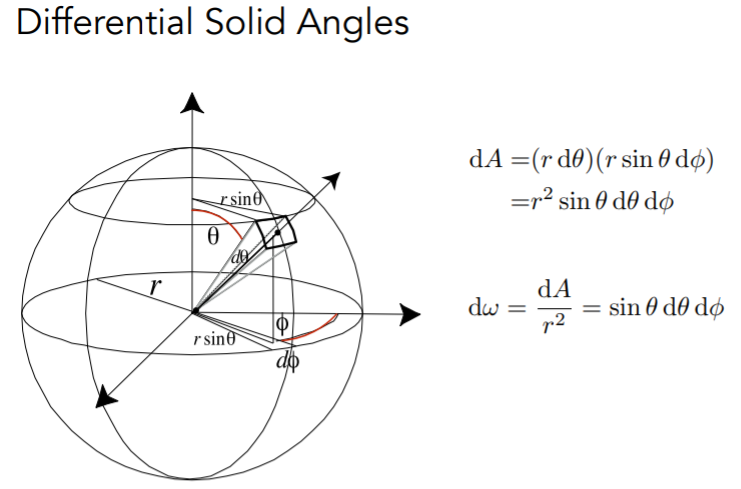
因此,公式中的积分项转成如下的二重积分:
k d c π ∫ Ω L i ( p , ω i ) n ⋅ ω i d ω i = k d c π ∫ ϕ = 0 2 π ∫ θ = 0 1 2 π L i ( p , ϕ i , θ i ) c o s θ s i n θ d θ d ϕ k_d\frac{c}{\pi}\int_{\Omega}L_i(p,\omega_i)n\cdot \omega_id\omega_i=k_d\frac{c}{\pi}\int_{\phi=0}^{2\pi}\int_{\theta=0}^{\frac12\pi}L_i(p,\phi_i,\theta_i)cos\theta sin \theta d\theta d\phi kdπc∫ΩLi(p,ωi)n⋅ωidωi=kdπc∫ϕ=02π∫θ=021πLi(p,ϕi,θi)cosθsinθdθdϕ
- n ⋅ ω i n⋅ωi n⋅ωi就是 c o s θ cosθ cosθ
求解积分需要我们在半球 Ω Ω Ω内采集固定数量的离散样本并对其结果求平均值。
分别给每个球坐标轴指定离散样本数量 n 1 n_1 n1 和 n 2 n_2 n2 以求其黎曼和,积分式会转换为以下离散版本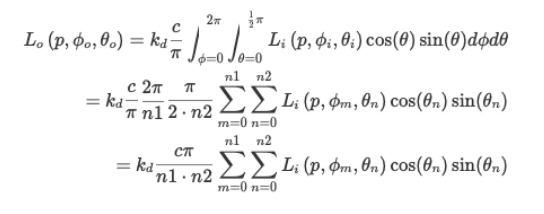
对于公式中的黎曼积分,我们需要确定 d θ dθ dθ和 d ϕ dϕ dϕ,即数值积分步长。
这个步长越小,则计算结果越接近于理论值,但耗费的时间也越多。
此外还需要提的是,我们是在切线空间的半球方向进行采样的,在切线空间获取采样的方向向量之后,我们需要把它转换到世界空间,这里我们没有构建变换矩阵,直接计算切线空间的三个基向量。
计算近似的黎曼积分的着色器代码思路如下
============================Vertex Shader=======================
#version 330 core
layout (location = 0) in vec3 position;
layout (location = 1) in vec3 normal;
layout (location = 2) in vec2 texcoord;
layout (location = 3) in vec3 color;
out vec3 worldPos;
uniform mat4 viewMatrix;
uniform mat4 projectMatrix;
void main(){
worldPos = position;
gl_Position = projectMatrix * viewMatrix * vec4(position,1.0f);
}
============================Fragment Shader=======================
#version 330 core
out vec4 FragColor;
in vec3 worldPos;
uniform samplerCube environmentMap;
const float PI = 3.14159265359;
void main()
{
// 世界向量充当原点的切线曲面的法线,与WorldPos对齐。
// 给定此法线,计算环境的所有传入辐射。
vec3 N = normalize(worldPos);
vec3 irradiance = vec3(0.0);
// 计算切线空间
vec3 up = vec3(0.0, 1.0, 0.0);
vec3 right = normalize(cross(up, N));
up = normalize(cross(N, right));
float sampleDelta = 0.025;
float nrSamples = 0.0;
for(float phi = 0.0; phi < 2.0 * PI; phi += sampleDelta)
{
for(float theta = 0.0; theta < 0.5 * PI; theta += sampleDelta)
{
// 球面到笛卡尔(在切线空间中)
vec3 tangentSample = vec3(sin(theta) * cos(phi), sin(theta) * sin(phi), cos(theta));
// 切线空间到世界空间
vec3 sampleVec = tangentSample.x * right + tangentSample.y * up + tangentSample.z * N;
irradiance += texture(environmentMap, sampleVec).rgb * cos(theta) * sin(theta);
nrSamples++;
}
}
irradiance = PI * irradiance * (1.0 / float(nrSamples));
FragColor = vec4(irradiance, 1.0);
}
- 在片元着色器中,我们取采样步长 d θ dθ dθ和 d ϕ dϕ dϕ均为0.025,然后是两重循环,获取采样方向向量的 ( θ , ϕ ) (θ,ϕ) (θ,ϕ)。
我们把它转换成笛卡尔坐标下的方向向量,用这个方向相应去获取该方向对应的hdr立方体纹理。最后结果除以总数并乘以一个 π π π
剩下的漫反射因子 k d k_d kd和反照率 c c c在渲染时确定。
上面的过程相当于对hdr立方体贴图做一个卷积操作,存储结果的纹理我们称之为辐照度纹理(Irradiance Map)。由于辐照度纹理没有高频的细节,因此我们不需要设置太大分辨率。
在cpu端创建一个比较小的cubemap,然后调用着色器绘制6次写入这个cubemap当中。
思路举例如下:
void IBLAuxiliary::convoluteDiffuseIntegral(int width, int height, unsigned int cubemapTexIndex, unsigned int irradianceTexIndex)
{
// manager.
TextureMgr::ptr texMgr = TextureMgr::getSingleton();
ShaderMgr::ptr shaderMgr = ShaderMgr::getSingleton();
// load shader.
unsigned int shaderIndex = shaderMgr->loadShader("diffuseIntegral",
"./glsl/diffuseIntegral.vert", "./glsl/diffuseIntegral.frag");
// load cube mesh.
Mesh::ptr cubeMesh = std::shared_ptr<Mesh>(new Cube(1.0f, 1.0f, 1.0f));
// load framebuffer.
FrameBuffer::ptr framebuffer = std::shared_ptr<FrameBuffer>(
new FrameBuffer(width, height, "irradianceDepth", {
}, true));
// projection matrix and view matrix.
glm::mat4 captureProjectMatrix = glm::perspective(glm::radians(90.0f), 1.0f, 0.1f, 10.0f);
glm::mat4 captureViewMatrix[] =
{
glm::lookAt(glm::vec3(0.0f), glm::vec3(+1.0f, 0.0f, 0.0f), glm::vec3(0.0f, -1.0f, 0.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(-1.0f, 0.0f, 0.0f), glm::vec3(0.0f, -1.0f, 0.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(0.0f,+1.0f, 0.0f), glm::vec3(0.0f, 0.0f,+1.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(0.0f,-1.0f, 0.0f), glm::vec3(0.0f, 0.0f,-1.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(0.0f, 0.0f,+1.0f), glm::vec3(0.0f, -1.0f, 0.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(0.0f, 0.0f,-1.0f), glm::vec3(0.0f, -1.0f, 0.0f)),
};
// begin to convolute.
framebuffer->bind();
glDisable(GL_BLEND);
glDisable(GL_CULL_FACE);
glEnable(GL_DEPTH_TEST);
glDepthFunc(GL_LEQUAL);
glClearColor(0.0f, 1.0f, 0.0f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
GLuint irradianceTexId = texMgr->getTexture(irradianceTexIndex)->getTextureId();
Shader::ptr shader = shaderMgr->getShader(shaderIndex);
shader->bind();
shader->setInt("environmentMap", 0);
shader->setMat4("projectMatrix", captureProjectMatrix);
texMgr->bindTexture(cubemapTexIndex, 0);
for (unsigned int i = 0; i < 6; ++i)
{
shader->setMat4("viewMatrix", captureViewMatrix[i]);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0,
GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, irradianceTexId, 0);
cubeMesh->draw(false, 0);
}
shader->unBind();
texMgr->unBindTexture(cubemapTexIndex);
framebuffer->unBind();
}
以上的预计算或者说预烘培步骤只需执行一次,然后我们就得到了一张辐照度立方体贴图,类似对原来的立方体贴图做了一个模糊处理,但这并不是模糊处理。

4 预计算镜面反射积分
接下来我们就把目标转到镜面反射的积分预计算上面。我们要预计算的就是渲染方程中的镜面反射部分,如下所示:
∫ Ω ( D F G 4 ( ω o ⋅ n ) ( ω i ⋅ n ) ) L i ( p , ω i ) n ⋅ ω i d ω i = ∫ Ω f r ( p , ω i , ω o ) L i ( p , ω i ) n ⋅ ω i d ω i \int_{\Omega}(\frac{DFG}{4(\omega_o\cdot n)(\omega_i\cdot n)})L_i(p,\omega_i)n\cdot \omega_id\omega_i =\int_{\Omega}f_r(p,\omega_i,\omega_o)L_i(p,\omega_i)n\cdot \omega_id\omega_i ∫Ω(4(ωo⋅n)(ωi⋅n)DFG)Li(p,ωi)n⋅ωidωi=∫Ωfr(p,ωi,ωo)Li(p,ωi)n⋅ωidωi
被积函数中的 f r ( p , ω i , ω o ) f_r(p,\omega_i,\omega_o) fr(p,ωi,ωo)是brdf函数,它与积分变量 ω i \omega_i ωi有关。
brdf函数它不是一个常量,因此我们不能像前面的漫反射积分那样把brdf函数当作常数项并提出积分外。
除此之外,我们还注意到最终的积分值还取决于出射方向 ω o \omega_o ωo。
因此镜面反射的积分值取决于两个变量,一个是 n n n,一个是 ω o \omega_o ωo。
前面算漫反射积分的时候,其仅取决于 n n n,所以我们可以很容易地遍历所有的 n n n,然后把积分值存到到立方体贴图中。
但是在镜面反射积分这里,积分值取决于 n n n和 ω o \omega_o ωo,,这使得问题变得复杂起来,因为我们不能同时用 n n n和 ω o \omega_o ωo去索引立方体贴图。
Epic Games公司提出了提出了一种近似的方案——分割求和近似法(split sum approximation)。
分割求和近似将方程的镜面部分分割成两个独立的部分,我们可以单独求,然后在 PBR 着色器中求和,以用于间接镜面反射部分 IBL。
∫ Ω f r ( p , ω i , ω o ) L i ( p , ω i ) n ⋅ ω i d ω i ≈ ∫ Ω L i ( p , ω i ) d ω i ∗ ∫ Ω f r ( p , ω i , ω o ) n ⋅ ω i d ω i \int_{\Omega}f_r(p,\omega_i,\omega_o)L_i(p,\omega_i)n\cdot \omega_id\omega_i \approx \\ \int_{\Omega}L_i(p,\omega_i)d\omega_i * \int_{\Omega}f_r(p,\omega_i,\omega_o)n\cdot \omega_i d\omega_i ∫Ωfr(p,ωi,ωo)Li(p,ωi)n⋅ωidωi≈∫ΩLi(p,ωi)dωi∗∫Ωfr(p,ωi,ωo)n⋅ωidωi
- 其中 ∫ Ω L i ( p , ω i ) d ω i \int_{\Omega}L_i(p,\omega_i)d\omega_i ∫ΩLi(p,ωi)dωi是对半球方向的辐射率进行积分, ∫ Ω f r ( p , ω i , ω o ) n ⋅ ω i d ω i \int_{\Omega}f_r(p,\omega_i,\omega_o)n\cdot \omega_id\omega_i ∫Ωfr(p,ωi,ωo)n⋅ωidωi则对半球方向的brdf函数进行积分。
我们将原来的积分分成了这两部分,预计算然后保存到两张纹理当中。
可以看到前面一部分的积分仅仅取决于法线向量 n n n,后面一部分表面上看取决于 n n n和 ω o \omega_o ωo,后面深入了解之后就会发现不用这两个变量。
4.1 预滤波HDR环境贴图
首先我们来看前面一部分的积分值,即 ∫ Ω L i ( p , ω i ) d ω i \int_{\Omega}L_i(p,\omega_i)d\omega_i ∫ΩLi(p,ωi)dωi,这部分预计算得到的纹理为预过滤的环境贴图,它返回的是反射的像素值。
我们知道,给定一个物体表面,若其表面的粗糙程度越高,则反射的内容越模糊。
因此,为了把物体的粗糙度考虑进去,我们将考虑物体的粗糙度划分成几个等级。
每个等级预计算一遍积分,并存储到cubemap的一个mipmap当中。
我们为生成的预过滤环境贴图构建mipmap,越粗糙则存储到mipmap的等级越高,正如下图所示:

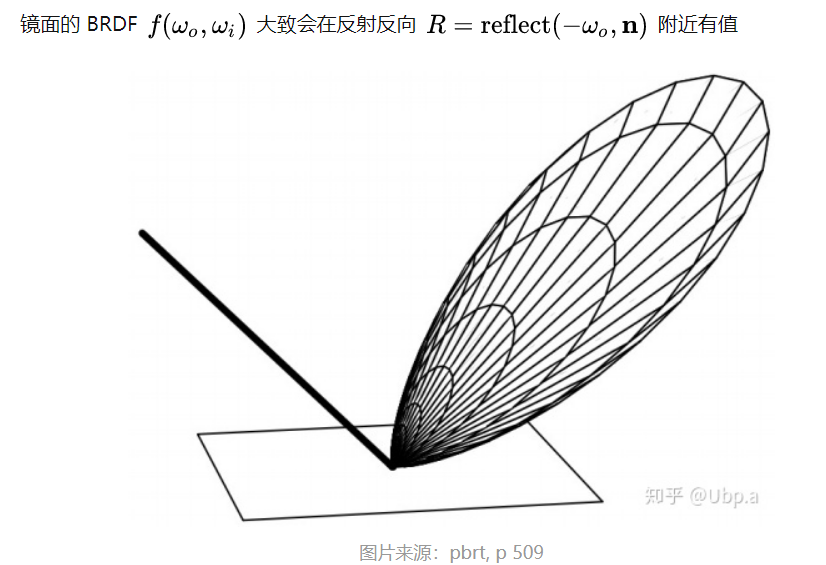
表面越粗糙则反射得越模糊,这一现象其实涉及到一个反射波瓣的问题。
反射波瓣就是反射光线的分布范围。如下图所示,对于一个光滑的完美镜面,其反射波瓣就是反射向量,越粗糙则反射波瓣越大,且基本上都是以反射向量为中心。

因此,当我们进行积分采样时,我们没有必要再在半球方向做一个均匀的采样,因为超出反射波瓣的采样是无效的。
我们应该偏向反射波瓣采样,这里就涉及到了一个重要性采样的问题,采用了重要性采样方法后,我们求解积分方程的数值方法不再是黎曼积分法,而是蒙特卡洛积分法。
并且由于我们在做环境贴图时,事先不知道视角方向,因此 Epic Games 假设视角方向——也就是镜面反射方向——总是等于输出采样方向ωo,以作进一步近似。
4.1.1 蒙特卡洛积分
蒙特卡罗积分方法(Monte Carlo method)是数值分析中的一个重要分支,它的核心概念是使用随机性来解决确定性的问题。
大数定律告诉我们,对于满足某个概率分布的随机变量,其数学期望所描述的积分可以使用这个随机变量随机抽样的样本均值来近似。
因此在一定的误差范围内,我们能够使用大量的随机数来近似积分运算的结果。
在计算机图形学中, 蒙特卡罗方法主要被应用于物理模拟以及光照传输中的积分运算,在离线渲染领域, 渲染方程几乎只能使用蒙特卡洛方法来进行计算。
为了深入理解蒙特卡罗方法,我们首先要复习概率论相关的一些基础内容。
4.1.1.1 概率密度函数、概率分布函数
概率密度函数(probability density function, 简称PDF)用于描述连续型随机变量所服从的概率分布。
对于连续随机变量 X X X,其概率密度函数 p ( x ) p(x) p(x),是通过区间 [ x , x + d x ] [x,x+dx] [x,x+dx]内的,随机数的概率, p ( x ) d x p(x)dx p(x)dx来定义的。
然而这种定义方式并不直观,所以连续随机变量的概率分布一般通过更直观的称为概率分布函数或者累积分布函数(cumulative distribution function, 简称CDF)来定义。
连续随机变量 X X X的累积分布函数用大写字母 P P P表示,其定义如下:
P ( y ) = P r { x ≤ y } = ∫ − ∞ y p ( x ) d x P(y)=Pr\{x\leq y\}=\int_{-\infty}^yp(x)dx P(y)=Pr{ x≤y}=∫−∞yp(x)dx
可以看到,概率分布函数 P ( y ) P(y) P(y),定义的是所有随机数的值中,小于或等于 y y y的随机变量的概率的积分。
即理解成对于一个随机数 x x x,其小于等于 y y y的概率。
因此,概率分布函数是一个递增函数。
连续随机变量的概率密度函数 p ( x ) p(x) p(x)具有以下的属性:
∀ x : p ( x ) ≥ 0 \forall x:p(x) \geq 0 ∀x:p(x)≥0
∫ − ∞ + ∞ p ( x ) d x = 1 \int _{-\infty}^{+\infty}p(x)dx = 1 ∫−∞+∞p(x)dx=1
p ( x ) = d P ( x ) d x p(x)=\frac{dP(x)}{dx} p(x)=dxdP(x)
可以看到, p ( x ) p(x) p(x)是 P ( x ) P(x) P(x)的导数。
那么给定一个随机变量的区间范围 [ a , b ] [a,b] [a,b],随机变量的值 x x x落在这个区间的概率计算如下:
P r { a ≤ x ≤ b } = P r ( x ≤ b ) − P r ( x ≤ a ) = P ( b ) − P ( a ) = ∫ a b p ( z ) d z Pr\{a\leq x\leq b\}=Pr(x\leq b)-Pr(x\leq a)\\ =P(b)-P(a)=\int_a^b p(z)dz Pr{ a≤x≤b}=Pr(x≤b)−Pr(x≤a)=P(b)−P(a)=∫abp(z)dz
这里的 P r Pr Pr函数是概率函数,而不是概率分布函数。
直观来讲,概率密度函数 p ( x ) p(x) p(x)给定的,并不是随机变量取值 x x x的概率,概率密度函数与轴围成的面积才是给定的概率。
如下所示,图(a)是概率分布函数,而图(b)是概率密度函数。
给定区间的 [ a , b ] [a,b] [a,b]的概率,就是下图(b)中的面积。
这也对应了上式的积分形式(积分的几何意义就是面积)。
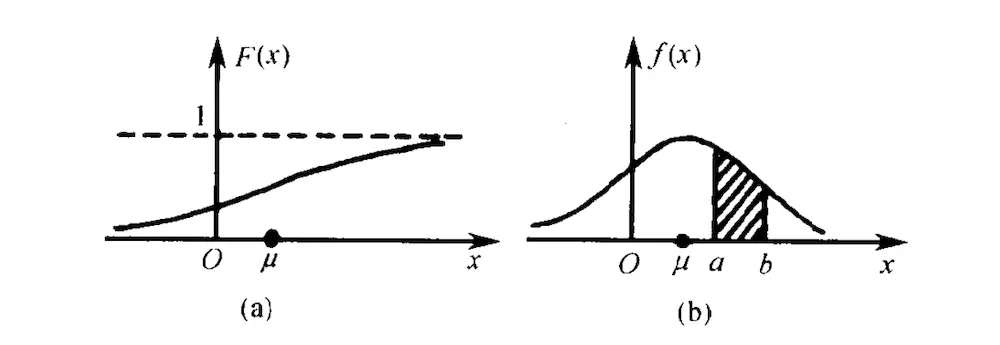
在这里,我们要特别关注的一个分布,那就是均匀分布。
对于 [ a , b ] [a,b] [a,b]区间上的均匀分布,其概率密度函数为常数 1 b − a \frac{1}{b-a} b−a1。
它表示随机抽样结果落于区间 [ x , x + d x ] [x,x+dx] [x,x+dx]的概率,在每个 x x x处都相同。
均匀分布的随机变量是整个蒙特卡罗方法的基础。
在计算机模拟中,通过都是由系统提供的random()函数生成某个区间内的均匀分布,然后通过一些方法将均匀分布的随机变量转换为具有任意概率密度分布的随机变量。
4.1.1.2 数学期望
对于离散随机变量 X X X,假设其值 x i x_i xi对应的抽样概率为 p i p_i pi,则该随机变量 X X X的数学期望,或称为均值,为:
E [ X ] = Σ i = 1 n p i x i E[X]=\Sigma_{i=1}^np_ix_i E[X]=Σi=1npixi
数学期望代表的是对一个随机变量 X X X,进行抽样的平均结果。
例如,对于骰子的例子,它的数学期望为:
E [ X d i e ] = Σ i = 1 6 p i x i = Σ i = 1 6 1 6 x i = 1 6 ( 1 + 2 + 3 + 4 + 5 + 6 ) = 3.5 E[X_{die}]=\Sigma_{i=1}^6p_i x_i\\ =\Sigma_{i=1}^6\frac16x_i=\frac16(1+2+3+4+5+6)=3.5 E[Xdie]=Σi=16pixi=Σi=1661xi=61(1+2+3+4+5+6)=3.5
相应地,对于连续随机变量 X X X,其期望值为随机变量值 x x x与其概率密度函数 p ( x ) p(x) p(x)的乘积,在全定义域上的积分:
E [ X ] = ∫ − ∞ + ∞ x p ( x ) d x E[X]=\int_{-\infty}^{+\infty}xp(x)dx E[X]=∫−∞+∞xp(x)dx
- 该积分形式,可以通过离散划分连续随便变量的定义域,然后按照离散数学期望得到一个近似的公式,当划分数趋向于无穷大且划分区间趋向于无穷小时,就是该积分的定义。
E [ X ] ≈ b − a n Σ i = 1 n x i p ( x i ) n → + ∞ , b − a n Σ i = 1 n x i p ( x i ) = ∫ a b x p ( x ) d x = E [ X ] E[X]\approx\frac{b-a}{n}\Sigma_{i=1}^{n}x_ip(x_i) \\ n\to+\infty,\ \frac{b-a}{n}\Sigma_{i=1}^{n}x_ip(x_i)=\int_a^bxp(x)dx=E[X] E[X]≈nb−aΣi=1nxip(xi)n→+∞, nb−aΣi=1nxip(xi)=∫abxp(x)dx=E[X]
通常我们对随机变量的函数更感兴趣。
考虑以随机变量 X X X为自变量的函数 Y = g ( X ) Y=g(X) Y=g(X),我们只知道随机变量 X X X的概率分布,要求出随机变量 Y Y Y的数学期望值。
- 设 Y Y Y是随机变量 X X X的函数 Y = g ( X ) Y=g(X) Y=g(X),且函数 g g g是连续函数
- 若 X X X是离散型随机变量,它的概率函数为 P { X = x i } = p i , i = 1 , 2 , … P\{X=x_i\}=p_i,i=1,2,… P{
X=xi}=pi,i=1,2,…
则有:
E [ Y ] = E [ g ( X ) ] = Σ i = 1 ∞ g ( x i ) p i E[Y]=E[g(X)]=\Sigma_{i=1}^{\infty}g(x_i)p_i E[Y]=E[g(X)]=Σi=1∞g(xi)pi - 若 X X X是连续型随机变量,它的概率密度函数为 p ( x ) p(x) p(x)
则有:
E [ Y ] = E [ g ( X ) ] = ∫ − ∞ + ∞ g ( x ) p ( x ) d x E[Y]=E[g(X)]=\int_{-\infty}^{+\infty}g(x)p(x)dx E[Y]=E[g(X)]=∫−∞+∞g(x)p(x)dx
4.1.1.3 大数定律
在统计学中,很多问题涉及对大量独立的随机变量抽样 x i x_i xi的和进行处理。
这些随机变量拥有相同的概率密度函数 p ( x ) p(x) p(x),这样的随机变量称为独立同分布的随机变量。
当这些随机变量抽样的和,被除以这些随机变量抽样的数量 N N N时,我们就能得到该随机变量的期望值的一个估计:
E [ X ] ≈ X ‾ = 1 N Σ i = 1 N x i E[X]\approx\overline X=\frac1N\Sigma_{i=1}^Nx_i E[X]≈X=N1Σi=1Nxi
随着抽样数 N N N的增大,该估计的方差逐渐减小。
N N N足够大时,该估计的值就能够充分接近实际数学期望的值,这样我们就能够将统计方法用于解决确定性问题。
大数定律(law of large numbers)告诉我们,当 N → ∞ N\to\infty N→∞时,我们可以确定随机变量的统计平均值趋近于数学期望的值,即:
P { E [ X ] = l i m N → ∞ 1 N Σ i = 1 N x i } = 1 P\{E[X]=lim_{N\to \infty}\frac1N\Sigma_{i=1}^Nx_i\} = 1 P{ E[X]=limN→∞N1Σi=1Nxi}=1
因此,随机变量的数学期望可以通过对随机变量执行大量的重复抽样来近似计算得到。
4.1.1.4 蒙特卡罗积分
假设我们要计算一个一维函数的积分,如 ∫ a b f ( x ) d x \int_a^bf(x)dx ∫abf(x)dx。数值分析方法通常采用一些近似方法来计算积分。
一种最简单的求积分的方法就是采用梯形法,它通过将被积函数沿作用域上划分成多个区域,然后计算这些区域面积的和。
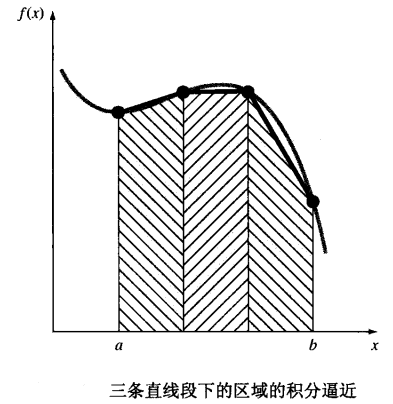
这种方法不适用于多维积分的计算,计算机图形学领域用的最多的还是蒙特卡罗方法。
之前提到,大数定律用于对数学期望的积分公式进行估计,即对积分 ∫ − ∞ + ∞ x f ( x ) d x \int_{-\infty}^{+\infty}xf(x)dx ∫−∞+∞xf(x)dx进行估计。
但是通常情况下我们要求的积分公式是对任意的一个函数积分
假设函数 g ( x ) g(x) g(x)的定义域为 x ∈ S x∈S x∈S(可以是一个多维空间),我们希望计算如下的积分:
I = ∫ x ∈ S g ( x ) d x I=\int_{x\in S}g(x)dx I=∫x∈Sg(x)dx
先暂时搁置如上的积分
由前面我们知道,给定任意一个关于随机变量的实数函数 f f f以及服从 p ( x ) p(x) p(x)概率密度函数的随机变量 x x x
我们可以采用如下的公式来近似计算随机变量函数 f ( x ) f(x) f(x)的数学期望:
E [ f ( x ) ] = ∫ x ∈ S f ( x ) p ( x ) d x ≈ 1 N Σ i = 1 N f ( x i ) E[f(x)]=\int_{x\in S}f(x)p(x)dx\approx\frac1N\Sigma_{i=1}^Nf(x_i) E[f(x)]=∫x∈Sf(x)p(x)dx≈N1Σi=1Nf(xi)
现在我们让之前搁置的积分 I I I的被积函数, g ( x ) = f ( x ) p ( x ) g(x)=f(x)p(x) g(x)=f(x)p(x)
则 f ( x ) = g ( x ) p ( x ) f(x)=\frac{g(x)}{p(x)} f(x)=p(x)g(x)
那么就有这个变换
∫ x ∈ S f ( x ) p ( x ) d x = ∫ x ∈ S g ( x ) d x ≈ 1 N Σ i = 1 N g ( x i ) p ( x i ) \int_{x\in S}f(x)p(x)dx=\int_{x\in S}g(x)dx\approx\frac1N\Sigma_{i=1}^N\frac{g(x_i)}{p(x_i)} ∫x∈Sf(x)p(x)dx=∫x∈Sg(x)dx≈N1Σi=1Np(xi)g(xi)
可以看到通过这个变换,我们巧妙地转换成我们要求的积分公式,这就是蒙特卡洛方法求积分的核心思想。
变换的式子它的期望为
E [ 1 N Σ i = 1 N g ( x i ) p ( x i ) ] = 1 N Σ i = 1 N E [ g ( x i ) p ( x i ) ] = 1 N N ∫ g ( x ) p ( x ) p ( x ) d x = ∫ g ( x ) d x E[\frac1N\Sigma_{i=1}^N\frac{g(x_i)}{p(x_i)}]=\frac1N\Sigma_{i=1}^NE[\frac{g(x_i)}{p(x_i)}]\\ =\frac1NN\int\frac{g(x)}{p(x)}p(x)dx=\int g(x)dx E[N1Σi=1Np(xi)g(xi)]=N1Σi=1NE[p(xi)g(xi)]=N1N∫p(x)g(x)p(x)dx=∫g(x)dx
估计方差为
σ 2 = 1 N ∫ ( g ( x ) p ( x ) − I ) 2 p ( x ) d x \sigma^2=\frac1N\int(\frac{g(x)}{p(x)}-I)^2p(x)dx σ2=N1∫(p(x)g(x)−I)2p(x)dx
可以看到,随着 N N N的增大,方差随之降低(成反比),这就是一般蒙特卡罗方法的特点。
实际上蒙特卡罗方法最大的问题就是估计逼近正确结果的速度非常慢。
理论上, p ( x ) p(x) p(x)的函数的选择可以是任意的,这也是蒙特卡罗方法的优点,因为通常很难生成与被积函数具有一致分布的随机数。
我们通过使 g ( x i ) g(x_i) g(xi)和 p ( x i ) p(x_i) p(xi)的比值尽可能地小,减少估计误差,在实践上通常我们尽可能地使 p ( x ) p(x) p(x)的分布接近于 g ( x ) g(x) g(x)。
综上,蒙特卡洛积分方法计算任意函数的积分步骤如下:
- 首先对一个满足某种概率分布的随机数进行抽样;
- 使用该抽样值计算 g ( x i ) p ( x i ) \frac{g(x_i)}{p(x_i)} p(xi)g(xi)的值,这称为该样本的贡献值;
- 最后对所有抽样点计算的结果求平均值。
上面的步骤中,最困难的就是怎么样对一个具有任意分布函数的随机变量进行抽样。
4.1.1.5 随机抽样
首先定义什么是抽样。
给定一个定于域空间 Ω 0 \Omega_0 Ω0及其概率密度函数 p ( x ) p(x) p(x),其中 x ∈ Ω 0 x\in \Omega_0 x∈Ω0则应有:
∫ Ω 0 p ( x ) d x = 1 \int_{\Omega_0}p(x)dx=1 ∫Ω0p(x)dx=1
抽样是这样的一个算法,它能够从 p ( x ) p(x) p(x)对应的随机变量 X X X中产生一系列随机数 X 1 , X 2 , … X1,X2,… X1,X2,…使得对任意的 Ω ∈ Ω 0 Ω∈Ω_0 Ω∈Ω0满足如下:
P { X k ∈ Ω } = ∫ Ω p ( x ) d x ≤ 1 P\{X_k\in\Omega\}=\int_{\Omega}p(x)dx\leq 1 P{ Xk∈Ω}=∫Ωp(x)dx≤1
在实现中我们并不能直接从 p ( x ) p(x) p(x)产生随机数,在计算机程序中这个过程必须要求首先具有某些基础随机数的一个序列。
我们通常采用均匀随机数random来产生一个均匀分布的随机数,然后用来作为抽样所需的基础随机数。
目前抽象方法根据不同情况有不同的方法,这里暂不介绍
4.1.1.6 重要性采样
重要性采样(importance sampling)是蒙特卡罗方法中最重要的方差缩减方法。
它通过选择对一个与目标概率分布具有相似形状的分布函数进行抽样来减少方差。
重要性采样试图在被积函数中贡献较多的区域放置更多的采样点,以体现这部分区域的重要性。
之前提到,给定一个概率密度函数 p ( x ) p(x) p(x)以及根据该概率密度函数抽样得到的 N N N个随机数 x i x_i xi,根据蒙特卡洛方法,被积函数的积分 I I I可以通过以下公式来近似估计
I N = 1 N Σ i = 1 N f ( x i ) p ( x i ) I_{N}=\frac1N\Sigma_{i=1}^N\frac{f(x_i)}{p(x_i)} IN=N1Σi=1Np(xi)f(xi)
一个理想的估计的方差应该为0,即
σ 2 = 1 N ∫ ( f ( x ) p ( x ) − I ) 2 p ( x ) d x = 0 \sigma^2=\frac1N\int(\frac{f(x)}{p(x)}-I)^2p(x)dx=0 σ2=N1∫(p(x)f(x)−I)2p(x)dx=0
被积函数部分的 p ( x ) > 0 p(x)>0 p(x)>0,故应有 ( f ( x ) p ( x ) − I ) 2 = 0 (\frac{f(x)}{p(x)}-I)^2=0 (p(x)f(x)−I)2=0,从而有如下的推导:
p ( x ) = ∣ f ( x ) ∣ I p(x)=\frac{|f(x)|}{I} p(x)=I∣f(x)∣
若我们采用该公式得到的概率密度函数进行采样,那么方差就会被完全消除。但是之前要求我们首先计算 I I I的值,而这正是我们尝试去求解的,因而套娃了。
但是我们可以通过选取与被积函数 f ( x ) f(x) f(x)具有相似形状的概率密度函数来减少方差。
选择用于抽样的概率密度函数非常重要,尽管蒙特卡罗方法本身没有限制对概率密度函数的选择,但是选择不好的概率密度函数会大大增加蒙特卡罗估计的方差。
直观来讲,重要性采样就是根据被积函数 f ( x ) f(x) f(x)的值来调整 p ( x ) p(x) p(x)的概率分布, f ( x ) f(x) f(x)值大的地方就多采样几个点;值小的地方就少采样一点。
p ( x ) p(x) p(x)概率密度函数越是接近 f ( x ) f(x) f(x),蒙特卡罗方法估算的结果就越精确。
4.1.1.7 预滤波HDR环境贴图
回到话题,为了加速这一步蒙特卡洛积分方法的收敛速度,Epic Games公司提出使用超均匀分布序列(Low-discrepancy Sequence)——Hammersley序列。
相对于普通的伪随机数,Hammersley序列的随机数分布更加均匀,如下图所示,将其应用到蒙特卡洛采样能够提升收敛速度。
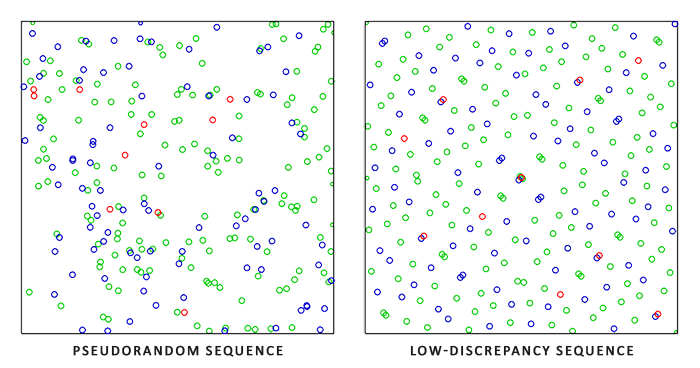
我们使用的是二维的Hammersley序列。
一个二维的Hammersley序列 H N = { x 1 , … , x N } , N ≥ 1 H_N=\{x_1,…,x_N\}, N\geq 1 HN={ x1,…,xN},N≥1是散落分布在单位正方形内的点集,其数学定义为:
H N = { x i = ( i / N Φ 2 ( i ) ) , f o r i = 0 , . . . , N − 1 } H_N=\{x_i= (\begin{matrix} i/N\\ \Phi_2(i) \end{matrix} ),\ \ for\ \ i=0,...,N-1 \} HN={ xi=(i/NΦ2(i)), for i=0,...,N−1}
其中 Φ 2 ( i ) \Phi_2(i) Φ2(i)是Van der Corput序列,它输入 i i i,然后将 i i i的二进制编码以小数点为对称做一个镜像操作,返回 [ 0 , 1 ) [0,1) [0,1)的浮点数,其数学定义为:
Φ 2 ( i ) = a 0 2 + a 1 2 2 + . . . + a r 2 r + 1 \Phi_2(i)=\frac{a_0}{2}+\frac{a_1}{2^2}+...+\frac{a_r}{2^{r+1}} Φ2(i)=2a0+22a1+...+2r+1ar
- 其中的 a 0 a 1 … a n a_0a_1…a_n a0a1…an是 i i i的二进制编码每一位二进制位,也就是
i = a 0 + a 1 ⋅ 2 + a 2 ⋅ 2 2 + a 3 ⋅ 2 3 + … + a r ⋅ 2 r i=a_0+a_1\cdot 2+a_2\cdot 2^2+a_3\cdot 2^3+…+a_r\cdot 2^r i=a0+a1⋅2+a2⋅22+a3⋅23+…+ar⋅2r
然后我们需要将这个二维的序列转换成我们对半球方向的三维采样.
我们利用球面坐标和笛卡尔坐标之间的关系
首先将Hammersley序列 x i = ( u , v ) T ∈ H N x_i=(u,v)^T\in H_N xi=(u,v)T∈HN映射到 ( ϕ , θ ) (\phi,\theta) (ϕ,θ),然后转换成笛卡尔坐标下的向量形式。
一个均匀映射和一个余弦映射公式如下:
U n i f o r m m a p p i n g = { θ = c o s − 1 ( 1 − v ) ϕ = 2 π u C o s i n u s m a p p i n g = { θ = c o s − 1 ( ( 1 − v ) ) ϕ = 2 π u Uniform\ \ mapping= \{\begin{matrix} \theta=cos^{-1}(1-v)\\ \phi=2\pi u \end{matrix} \\ Cosinus\ \ mapping= \{\begin{matrix} \theta=cos^{-1}(\sqrt{(1-v)})\\ \phi=2\pi u \end{matrix} Uniform mapping={ θ=cos−1(1−v)ϕ=2πuCosinus mapping={ θ=cos−1((1−v))ϕ=2πu
均匀映射就是将序列映射到一个均匀的分布,余弦映射则将序列映射到一个更偏向于半球中心轴上的分布。
两者的区别如下图所示。

Hammersley序列可以通过位移操作快速地实现,代码思路见下
float radicalInverseVdc(uint bits)
{
bits = (bits << 16u) | (bits >> 16u);
bits = ((bits & 0x55555555u) << 1u) | ((bits & 0xAAAAAAAAu) >> 1u);
bits = ((bits & 0x33333333u) << 2u) | ((bits & 0xCCCCCCCCu) >> 2u);
bits = ((bits & 0x0F0F0F0Fu) << 4u) | ((bits & 0xF0F0F0F0u) >> 4u);
bits = ((bits & 0x00FF00FFu) << 8u) | ((bits & 0xFF00FF00u) >> 8u);
return float(bits) * 2.3283064365386963e-10; // / 0x100000000
}
vec2 hammersley(uint i, uint N)
{
return vec2(float(i) / float(N), radicalInverseVdc(i));
}
但是,并非所有 OpenGL 相关驱动程序都支持位运算符(例如WebGL和OpenGL ES 2.0)
在这种情况下,我们需要不依赖位运算符的替代版本 Van Der Corput 序列,性能会差一点,得到的东西是一样的:
float VanDerCorpus(uint n, uint base)
{
float invBase = 1.0 / float(base);
float denom = 1.0;
float result = 0.0;
for(uint i = 0u; i < 32u; ++i)
{
if(n > 0u)
{
denom = mod(float(n), 2.0);
result += denom * invBase;
invBase = invBase / 2.0;
n = uint(float(n) / 2.0);
}
}
return result;
}
// ----------------------------------------------------------------------------
vec2 HammersleyNoBitOps(uint i, uint N)
{
return vec2(float(i)/float(N), VanDerCorpus(i, 2u));
}
接着我们要用Hammersley序列实现我们的重要性采样。
前面已经提到过,我们将考虑物体的粗糙度,因为不同粗糙度下的反射波瓣大小不同。
我们将粗糙度换分成5个等级,每个等级根据当前的粗糙度进行重要性采样。
因此做重要性采样时我们需要根据粗糙度确定当前的反射波瓣大小,反射波瓣越大则采样范围越大。
我们将结合之前PBR提到的法线分布函数,法线分布函数给定一个法线向量,它返回微平面法线与给定法线朝向一致的分布概率。
Trowbridge-Reitz GGX法线分布函数的数学定义为:
N D F G G X T R ( n , h , α ) = α 2 π ( ( n ⋅ h ) 2 ( α 2 − 1 ) + 1 ) 2 NDF_{GGXTR}(n,h,\alpha)=\frac{\alpha^2}{\pi((n\cdot h)^2(\alpha^2-1)+1)^2} NDFGGXTR(n,h,α)=π((n⋅h)2(α2−1)+1)2α2
我们将法线分布函数与余弦映射结合起来做重要性采样:
I m p o r t a n t s a m p l i n g = { θ = c o s − 1 ( 1 − v v ( α 2 − 1 ) + 1 ) ϕ = 2 π u Important\ \ sampling= \{\begin{matrix} \theta=cos^{-1}(\sqrt{\frac{1-v}{v(\alpha^2-1)+1}})\\ \phi=2\pi u \end{matrix} Important sampling={ θ=cos−1(v(α2−1)+11−v)ϕ=2πu
这也是Epic Games公司提出的映射方法,与之前的余弦映射相比,该式子多了一个分母 v ( α 2 − 1 ) + 1 v(\alpha^2-1)+1 v(α2−1)+1,取自法线分布函数。
当粗糙度 α α α增大时,余弦值减小, θ θ θ取值范围越大,反射波瓣也就越大,这个就是我们用到重要性采样的大体思路。
对于给定的Hammersley序列、法线向量N、粗糙度roughness,一个重要性采样代码思路会如下,根据迪士尼对 PBR 的研究,Epic Games 使用了平方粗糙度以获得更好的视觉效果。:
vec3 importanceSampleGGX(vec2 Xi, vec3 N, float roughness)
{
float a = roughness * roughness;
float phi = 2.0 * PI * Xi.x;
float cosTheta = sqrt((1.0 - Xi.y) / (1.0 + (a * a - 1.0) * Xi.y));
float sinTheta = sqrt(1.0 - cosTheta * cosTheta);
vec3 H;
H.x = cos(phi) * sinTheta;
H.y = sin(phi) * sinTheta;
H.z = cosTheta;
// from tangent space to world space.
vec3 up = abs(N.z) < 0.999 ? vec3(0.0, 0.0, 1.0) : vec3(1.0, 0.0, 0.0);
vec3 tangent = normalize(cross(up, N));
vec3 bitangent = cross(N, tangent);
vec3 sampleVec = H.x * tangent + H.y * bitangent + H.z * N;
return normalize(sampleVec);
}
最后我们就利用重要性采样进行数值积分的计算,如下所示:
∫ Ω L i ( p , ω i ) d ω i ≈ 1 N Σ k = 1 N L i ( l k ) \int_{\Omega}L_i(p,\omega_i)d\omega_i \approx \frac1N\Sigma_{k=1}^NL_i(l_k) ∫ΩLi(p,ωi)dωi≈N1Σk=1NLi(lk)

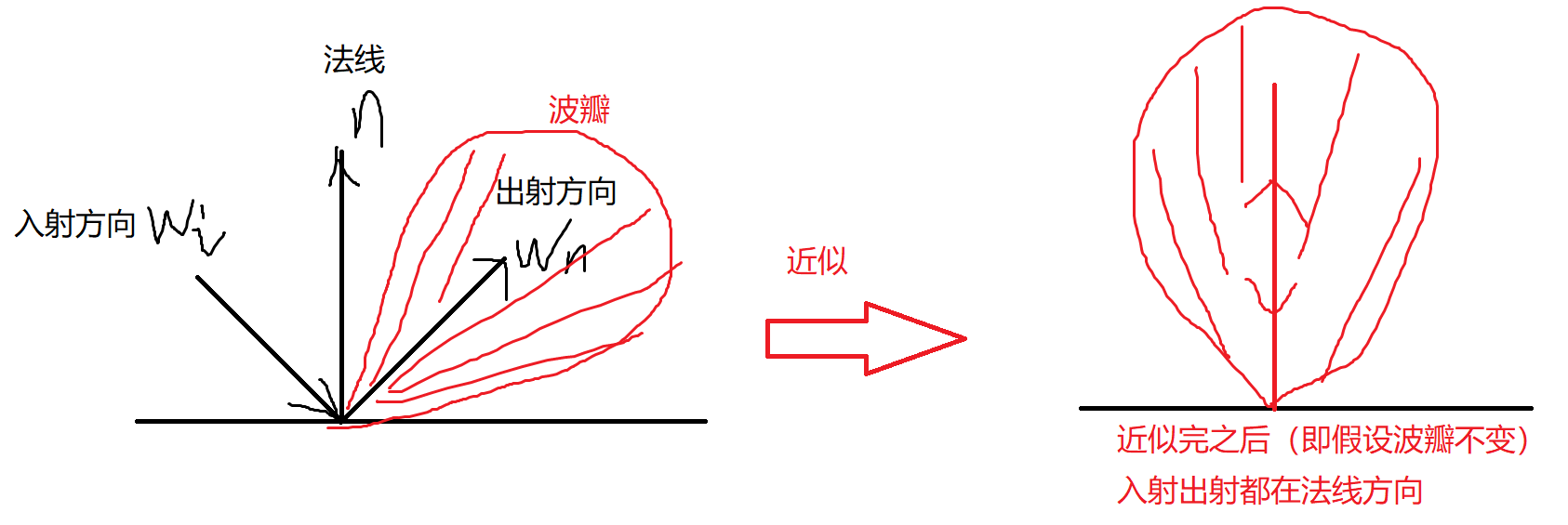
我们使用 Cook-Torrance BRDF 的法线分布函数(NDF)生成采样向量及其散射强度,该函数将法线和视角方向作为输入。
由于我们在卷积环境贴图时事先不知道视角方向,因此 Epic Games 假设视角方向——也就是镜面反射方向——总是等于输出采样方向ωo,以作进一步近似。翻译成代码如下:
vec3 N = normalize(w_o);
vec3 R = N;
vec3 V = R;
这样,预过滤的环境卷积就不需要关心视角方向了。这意味着当从如下图的角度观察表面的镜面反射时,得到的掠角镜面反射效果不是很好(图片来自文章《Moving Frostbite to PBR》)。

实现的积分计算代码如下:
Ephic Games公司发现再乘上一个权重 c o s θ l k cosθ_{lk} cosθlk效果更佳,因而在采样之后,又乘以了 NdotL
∫ Ω L i ( p , ω i ) d ω i ≈ 1 N Σ k = 1 N L i ( l k ) ∗ c o s θ l k \int_{\Omega}L_i(p,\omega_i)d\omega_i \approx \frac1N\Sigma_{k=1}^NL_i(l_k)*cosθ_{lk} ∫ΩLi(p,ωi)dωi≈N1Σk=1NLi(lk)∗cosθlk
实现的积分计算代码参考如下
#version 330 core
in vec3 worldPos;
out vec4 fragColor;
uniform float roughness;
uniform samplerCube environmentMap;
const float PI = 3.14159265359;
float radicalInverseVdc(uint bits);
vec2 hammersley(uint i, uint N);
vec3 importanceSampleGGX(vec2 Xi, vec3 N, float roughness);
void main()
{
vec3 N = normalize(worldPos);
vec3 V = N;
const uint sampleCount = 1024u;
float totalWeight = 0.0f;
vec3 prefilteredColor = vec3(0.0f);
for(uint i = 0u;i < sampleCount;++ i)
{
vec2 Xi = hammersley(i, sampleCount);
// sample halfway vector.
vec3 H = importanceSampleGGX(Xi, N, roughness);
// reflect vector.
vec3 L = normalize(2.0 * dot(V, H) * H - V);
float NdotL = max(dot(N, L), 0.0);
if(NdotL > 0.0f);
{
prefilteredColor += texture(environmentMap, L).rgb * NdotL;
totalWeight += NdotL;
}
}
prefilteredColor = prefilteredColor / totalWeight;
fragColor = vec4(prefilteredColor, 1.0f);
}
可以在cpu端生成多个mipmap层次的cubemap,对于每一个粗糙度等级,我们将预计算的结果存储到对应mipmap等级的cubemap纹理当中,最后我们就得到多个mipmap等级的Pre-Filtered Environment Map。
可以参考如下代码
void IBLAuxiliary::convoluteSpecularIntegral(int width, int height, unsigned int cubemapTexIndex,
unsigned int prefilteredTexIndex)
{
// manager.
TextureMgr::ptr texMgr = TextureMgr::getSingleton();
ShaderMgr::ptr shaderMgr = ShaderMgr::getSingleton();
// load shader.
unsigned int shaderIndex = shaderMgr->loadShader("prefilterEnvMap",
"./glsl/prefilterEnvMap.vert", "./glsl/prefilterEnvMap.frag");
// load cube mesh.
Mesh::ptr cubeMesh = std::shared_ptr<Mesh>(new Cube(1.0f, 1.0f, 1.0f));
// projection matrix and view matrix.
glm::mat4 captureProjectMatrix = glm::perspective(glm::radians(90.0f), 1.0f, 0.1f, 10.0f);
glm::mat4 captureViewMatrix[] =
{
glm::lookAt(glm::vec3(0.0f), glm::vec3(+1.0f, 0.0f, 0.0f), glm::vec3(0.0f, -1.0f, 0.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(-1.0f, 0.0f, 0.0f), glm::vec3(0.0f, -1.0f, 0.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(0.0f,+1.0f, 0.0f), glm::vec3(0.0f, 0.0f,+1.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(0.0f,-1.0f, 0.0f), glm::vec3(0.0f, 0.0f,-1.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(0.0f, 0.0f,+1.0f), glm::vec3(0.0f, -1.0f, 0.0f)),
glm::lookAt(glm::vec3(0.0f), glm::vec3(0.0f, 0.0f,-1.0f), glm::vec3(0.0f, -1.0f, 0.0f)),
};
// begin to filter.
GLuint prefilteredTexId = texMgr->getTexture(prefilteredTexIndex)->getTextureId();
Shader::ptr shader = shaderMgr->getShader(shaderIndex);
shader->bind();
shader->setInt("environmentMap", 0);
shader->setMat4("projectMatrix", captureProjectMatrix);
texMgr->bindTexture(cubemapTexIndex, 0);
unsigned int maxMipLevels = 5;
for (unsigned int mip = 0; mip < maxMipLevels; ++mip)
{
unsigned int mipWidth = width * std::pow(0.5, mip);
unsigned int mipHeight = height * std::pow(0.5, mip);
std::stringstream ss;
ss << mip;
FrameBuffer::ptr framebuffer = std::shared_ptr<FrameBuffer>(
new FrameBuffer(mipWidth, mipHeight, "prefilteredDepth" + ss.str(), {
}, true));
framebuffer->bind();
glDisable(GL_BLEND);
glDisable(GL_CULL_FACE);
glEnable(GL_DEPTH_TEST);
glEnable(GL_TEXTURE_CUBE_MAP_SEAMLESS);
glDepthFunc(GL_LEQUAL);
glClearColor(0.0f, 1.0f, 0.0f, 1.0f);
float roughness = (float)mip / (float)(maxMipLevels - 1);
shader->setFloat("roughness", roughness);
for (unsigned int i = 0; i < 6; ++i)
{
shader->setMat4("viewMatrix", captureViewMatrix[i]);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0,
GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, prefilteredTexId, mip);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
cubeMesh->draw(false, 0);
}
framebuffer->unBind();
}
shader->unBind();
texMgr->unBindTexture(cubemapTexIndex);
}
4.2 预计算 BRDF
接下来我们计算目标方法第二部分的积分,即brdf函数积分:
∫ Ω f r ( p , ω i , ω o ) n ⋅ ω i d ω i \int_{\Omega}f_r(p,\omega_i,\omega_o)n\cdot \omega_id\omega_i ∫Ωfr(p,ωi,ωo)n⋅ωidωi
我们知道 f r ( p , w i , w o ) = D F G 4 ( ω o ⋅ n ) ( ω i ⋅ n ) f_r(p, w_i, w_o) = \frac{DFG}{4(\omega_o \cdot n)(\omega_i \cdot n)} fr(p,wi,wo)=4(ωo⋅n)(ωi⋅n)DFG
所以积分值取决于三个变量: n ⋅ ω o n\cdot \omega_o n⋅ωo,表面粗糙度以及菲涅尔方程输入值的 F 0 F_0 F0
三个变量太多了,为了简化且方便预计算,我们设法将一些变量提出积分符号外:
∫ Ω f r ( p , ω i , ω o ) n ⋅ ω i d ω i = ∫ Ω f r ( p , ω i , ω o ) F ( ω o , h ) F ( ω o , h ) n ⋅ ω i d ω i = ∫ Ω f r ( p , ω i , ω o ) F ( ω o , h ) F ( ω o , h ) n ⋅ ω i d ω i \int_{\Omega}f_r(p,\omega_i,\omega_o)n\cdot \omega_id\omega_i =\int_{\Omega}f_r(p,\omega_i,\omega_o)\frac{F(\omega_o,h)}{F(\omega_o,h)}n\cdot \omega_id\omega_i\\ =\int_{\Omega}\frac{f_r(p,\omega_i,\omega_o)}{F(\omega_o,h)}F(\omega_o,h)n\cdot \omega_id\omega_i ∫Ωfr(p,ωi,ωo)n⋅ωidωi=∫Ωfr(p,ωi,ωo)F(ωo,h)F(ωo,h)n⋅ωidωi=∫ΩF(ωo,h)fr(p,ωi,ωo)F(ωo,h)n⋅ωidωi
将菲涅尔项 F ( ω o , h ) = ( F 0 + ( 1 − F 0 ) ( 1 − ω o ⋅ h ) 5 ) F(\omega_o,h)=(F_0+(1-F_0)(1-\omega_o\cdot h)^5) F(ωo,h)=(F0+(1−F0)(1−ωo⋅h)5)带入上式
∫ Ω f r ( p , ω i , ω o ) F ( ω o , h ) ( F 0 + ( 1 − F 0 ) ( 1 − ω o ⋅ h ) 5 ) n ⋅ ω i d ω i \int_{\Omega}\frac{f_r(p,\omega_i,\omega_o)}{F(\omega_o,h)}(F_0+(1-F_0)(1-\omega_o\cdot h)^5)n\cdot \omega_id\omega_i ∫ΩF(ωo,h)fr(p,ωi,ωo)(F0+(1−F0)(1−ωo⋅h)5)n⋅ωidωi
= ∫ Ω f r ( p , ω i , ω o ) F ( ω o , h ) ( F 0 ( 1 − ( 1 − ω o ⋅ h ) 5 ) + ( 1 − ω o ⋅ h ) 5 ) n ⋅ ω i d ω i = \int_{\Omega}\frac{f_r(p,\omega_i,\omega_o)}{F(\omega_o,h)}(F_0(1-(1-\omega_o\cdot h)^5)+(1-\omega_o\cdot h)^5)n\cdot \omega_id\omega_i =∫ΩF(ωo,h)fr(p,ωi,ωo)(F0(1−(1−ωo⋅h)5)+(1−ωo⋅h)5)n⋅ωidωi
得到的结果分成两部分:
∫ Ω f r ( p , ω i , ω o ) F ( ω o , h ) ( F 0 ( 1 − ( 1 − ω o ⋅ h ) 5 ) + ( 1 − ω o ⋅ h ) 5 ) n ⋅ ω i d ω i \begin{aligned} \int_{\Omega}\frac{f_r(p,\omega_i,\omega_o)}{F(\omega_o,h)}(F_0(1-(1-\omega_o\cdot h)^5)+(1-\omega_o\cdot h)^5)n\cdot \omega_id\omega_i\\ \end{aligned} ∫ΩF(ωo,h)fr(p,ωi,ωo)(F0(1−(1−ωo⋅h)5)+(1−ωo⋅h)5)n⋅ωidωi
= F o ∫ Ω f r ( p , ω i , ω o ) ( 1 − ( 1 − ω o ⋅ h ) 5 ) n ⋅ ω i d ω i + ∫ Ω f r ( p , ω i , ω o ) ( 1 − ω o ⋅ h ) 5 n ⋅ ω i d ω i \begin{aligned} =F_o\int_{\Omega}f_r(p,\omega_i,\omega_o)(1-(1-\omega_o\cdot h)^5)n\cdot \omega_id\omega_i +\int_{\Omega}f_r(p,\omega_i,\omega_o)(1-\omega_o\cdot h)^5 n\cdot \omega_i d\omega_i \end{aligned} =Fo∫Ωfr(p,ωi,ωo)(1−(1−ωo⋅h)5)n⋅ωidωi+∫Ωfr(p,ωi,ωo)(1−ωo⋅h)5n⋅ωidωi
现在我们把 F 0 F_0 F0提到积分外面了,两项积分取决于 n ⋅ ω o n⋅ω_o n⋅ωo和粗糙度roughness
我们构建这样的一个二维查找表,它的横轴坐标取值为 n ⋅ ω o n⋅ω_o n⋅ωo,纵轴坐标取值为粗糙度roughness。
我们渲染屏幕空间大小的四边形,遍历 n ⋅ ω o n⋅ω_o n⋅ωo和粗糙度roughness,计算其上面公式中的两项积分的结果,存储为纹理的像素值。
最后渲染时使用纹理坐标 ( n ⋅ ω o , r o u g h n e s s ) (n\cdot \omega_o, roughness) (n⋅ωo,roughness)去索引像素值
做法思路可参考如下
float geometrySchlickGGX(float NdotV, float roughness)
{
float a = roughness;
float k = (a * a) / 2.0f;
float nom = NdotV;
float denom = NdotV * (1.0 - k) + k;
return nom / denom;
}
float geometrySmith(vec3 N, vec3 V, vec3 L, float roughness)
{
float NdotV = max(dot(N, V), 0.0);
float NdotL = max(dot(N, L), 0.0);
float ggx2 = geometrySchlickGGX(NdotV, roughness);
float ggx1 = geometrySchlickGGX(NdotL, roughness);
return ggx1 * ggx2;
}
vec2 integrateBRDF(float NdotV, float roughness)
{
vec3 V;
V.x = sqrt(1.0 - NdotV * NdotV);
V.y = 0.0f;
V.z = NdotV;
float A = 0.0;
float B = 0.0;
vec3 N = vec3(0.0, 0.0, 1.0);
const uint sampleCount = 1024u;
for(uint i = 0u;i < sampleCount;++i)
{
vec2 Xi = hammersley(i, sampleCount);
vec3 H = importanceSampleGGX(Xi, N, roughness);
vec3 L = normalize(2.0 * dot(V, H) * H - V);
float NdotL = max(L.z, 0.0);
float NdotH = max(H.z, 0.0);
float VdotH = max(dot(V, H), 0.0);
if(NdotL > 0.0)
{
float G = geometrySmith(N, V, L, roughness);
float G_Vis = (G * VdotH) / (NdotH * NdotV);
float Fc = pow(1.0 - VdotH, 5.0);
A += (1.0 - Fc) * G_Vis;
B += Fc * G_Vis;
}
}
A /= float(sampleCount);
B /= float(sampleCount);
return vec2(A, B);
}
void main()
{
vec2 value = integrateBRDF(Texcoord.x, Texcoord.y);
fragColor = vec4(value, 0.0f, 1.0f);
}
用opengl可以在cpu端创建一个二维纹理,并送入一个屏幕大小的四边形进行预计算的渲染。
void IBLAuxiliary::convoluteSpecularBRDFIntegral(int width, int height, unsigned int brdfLutTexIndex)
{
// manager.
TextureMgr::ptr texMgr = TextureMgr::getSingleton();
ShaderMgr::ptr shaderMgr = ShaderMgr::getSingleton();
// load shader.
unsigned int shaderIndex = shaderMgr->loadShader("genBrdfLUT",
"./glsl/genBrdfLUT.vert", "./glsl/genBrdfLUT.frag");
// load quad mesh.
Mesh::ptr quadMesh = std::shared_ptr<Mesh>(new ScreenQuad());
FrameBuffer::ptr framebuffer = std::shared_ptr<FrameBuffer>(
new FrameBuffer(width, height, "brdfDepth", {
}, true));
Shader::ptr shader = shaderMgr->getShader(shaderIndex);
framebuffer->bind();
glDisable(GL_BLEND);
glDisable(GL_CULL_FACE);
glDisable(GL_DEPTH_TEST);
glDepthFunc(GL_LEQUAL);
glClearColor(0.0f, 1.0f, 0.0f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
GLuint brdfLutTexId = texMgr->getTexture(brdfLutTexIndex)->getTextureId();
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, brdfLutTexId, 0);
shader->bind();
quadMesh->draw(false, 0);
shader->unBind();
framebuffer->unBind();
}

5 计算渲染方程
在前面的步骤中我们预计算获取了Irradiance Map、Pre-Filtered Environment Map以及BRDF Lookup Texture。
最后我们就直接查找这些纹理,用以我们的光照计算。
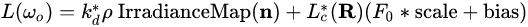
光照计算部分直接就是一开始提到的渲染方程,渲染方程中的积分项从纹理中直接获取,不再需要实时计算。
思路如下
// ambient lighting.
vec3 ambientS = fresnelSchlickRoughness(max(dot(normal, viewDir), 0.0f), F0, roughness);
vec3 ambientD = vec3(1.0f) - ambientS;
ambientD *= (1.0 - metallic);
vec3 irradiance = texture(irradianceMap, normal).rgb;
vec3 R = normalize(reflect(-viewDir, normal));
const float MAX_REFLECTION_LOD = 4.0;
vec3 prefilteredColor = texture(prefilteredMap, R, roughness * MAX_REFLECTION_LOD).rgb;
vec2 envBrdf = texture(brdfLutMap, vec2(max(dot(normal, viewDir), 0.0f), roughness)).rg;
vec3 envSpecular = prefilteredColor * (ambientS * envBrdf.x + envBrdf.y);
vec3 ambient = (albedo * irradiance * ambientD + envSpecular) * ao;
fragColor.xyz = ambient + fragColor.xyz * shadow + pointLightRadiance;
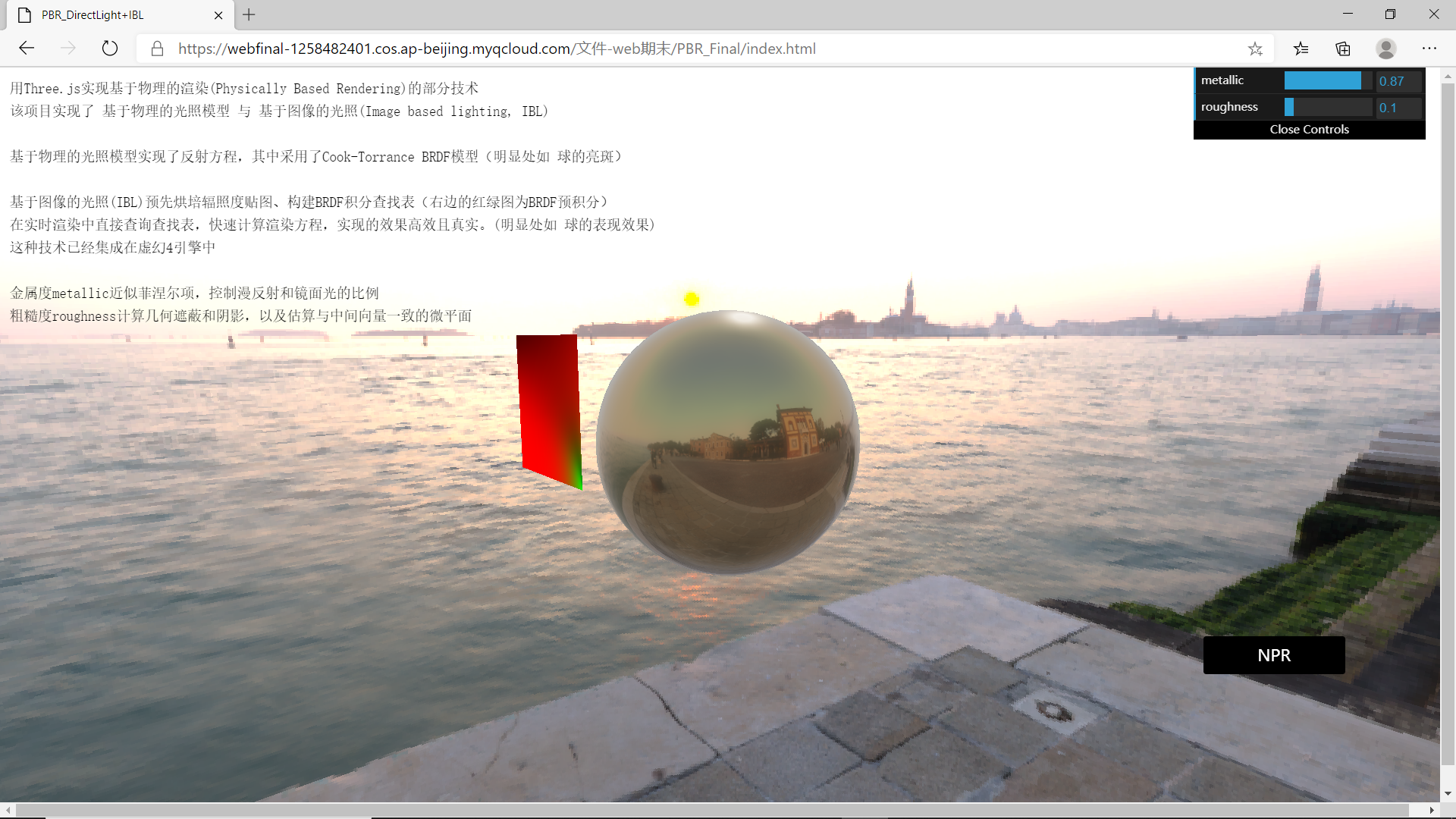
6 动手试试
因为当做前端课的作业,所以用three.js来进行了实现
报告和工程文件都在git上了,实现结果的截图如下(旁边那个是BRDF预积分图(虽然放着比较丑还是放出来一下