目录
一、简介
宽度优先搜索算法(又称广度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。下面我使用宽度优先搜索算法实现克隆图。
二、图的表示
1、邻接矩阵
对于N个点的图,需要N×N的矩阵表示点与点之间是否有边的存在。这种表示法的缺点是浪费空间,尤其是对于N×N的矩阵是稀疏矩阵,即边的数目远远小于N×N的时候,浪费了巨大的存储空间。
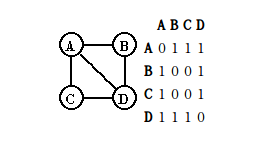
图 1
2、边的数组
使用一个Edge类,它含有两个int实例变量。这种表示方法很简洁但获取顶点v所有邻接顶点要检查图中所有的边。这种表示方法使用较少。
3、邻接链表
对于任何一个node A,外挂一个邻接链表,如果存在 A->X这样的边,就将X链入链表。 这种表示方法的优点是节省空间,缺点是所有链表都存在的缺点,地址空间的不连续造成缓存命中降低,性能有不如临界矩阵这样的数组。我们使用邻接链表来表示此次算法的实现。
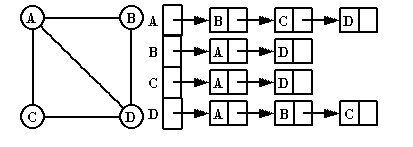
图 2
三、实战
1、题目概述
题目:给你无向连通图中一个节点,实现该图的 深拷贝(克隆)。
我们使用邻接链表来表示此次算法的实现。
class Node {
public:
int val;
vector<Node*> neighbors;
Node() {
val = 0;
neighbors = vector<Node*>();
}
Node(int _val) {
val = _val;
neighbors = vector<Node*>();
}
Node(int _val, vector<Node*> _neighbors) {
val = _val;
neighbors = _neighbors;
}
};2、实现方法1
我们可以利用宽度优先搜索遍历图,先把图的节点都生成一遍,把生成的节点和原始节点存到hash表中(clone nodes)。然后再遍历一遍hash表,生成边(clone edges )。
Node* cloneGraph(Node* node) {
if (node == NULL)
{
return NULL;
}
unordered_map<Node*, Node*> mapNode;
std::queue<Node*> queueNode;
queueNode.push(node);
Node*pnode = node;
//clone nodes
while (!queueNode.empty())
{
node = queueNode.front();
queueNode.pop();
if (mapNode.find(node) != mapNode.end())
{
continue;
}
mapNode[node] = new Node(node->val);
int s = node->neighbors.size();
for (int i = 0; i < s; i++)
{
queueNode.push(node->neighbors[i]);
}
}
//clone edge
unordered_map<Node*, Node*>::iterator it = mapNode.begin();
while (it != mapNode.end())
{
int s = it->first->neighbors.size();
for (int i = 0; i < s; ++i)
{
it->second->neighbors.push_back(mapNode[it->first->neighbors[i]]);
}
++it;
}
return mapNode[pnode];
}3、实现方法2
我们可以利用宽度优先搜索遍历图,把图的节点和节点的neighbour节点都生成一遍,把生成的节点和原始节点存到hash表中(clone nodes)。在遍历的同时生成边(clone edges)。
Node* cloneGraph2(Node* node) {
if (node == NULL)
{
return NULL;
}
unordered_map<Node*, Node*> mapNode;
std::queue<Node*> queueNode;
queueNode.push(node);
Node*pnode = node;
//clone node and edges
mapNode[node] = new Node(node->val);
while (!queueNode.empty())
{
node = queueNode.front();
queueNode.pop();
int s = node->neighbors.size();
for (int i = 0; i < s; i++)
{
if (mapNode.find(node->neighbors[i]) == mapNode.end())
{
mapNode[node->neighbors[i]] = new Node(node->neighbors[i]->val);
queueNode.push(node->neighbors[i]);
}
mapNode[node]->neighbors.push_back(mapNode[node->neighbors[i]]);
}
}
return mapNode[pnode];
}四、总结
深度优先搜索比较简单,但是可以解决很多问题,克隆图就可以通过深度优先搜索轻松的解决。方法1逻辑上比较清晰,方法2只进行一次遍历,效率高。