之前写过一篇文章,介绍Nginx如何监控各server流量,主要是通过新增第三方status模块查看所有server及upstream状态进行查看,之后总有人问有没有办法监控upstream并进行告警,所以今天介绍一下,完整的upstream监控及告警方法
应用:Nginx/Tengine
模块:ngx_http_upstream_check_module
监控:zabbix
告警:企业微信/钉钉
因为默认nginx的upstream是被动式的,不会进行主动监测,所以这里直接用tengine的upstream_check模块
如果你是tengine,只要是1.4以上版本,直接默认开启该模块了,如果你是nginx,需要重新编译nginx,添加该模块,编译方法这里不多说了,下载源码,用--add-module添加编译即可
upstream_check模块提供主动式后端服务器健康检查功能,下面是该模块提供的一些指令
check
Syntax: check interval=milliseconds [fall=count] [rise=count] [timeout=milliseconds] [default_down=true|false] [type=tcp|http|ssl_hello|mysql|ajp] [port=check_port] Default: interval=30000 fall=5 rise=2 timeout=1000 default_down=true type=tcp Context: upstream
该指令可以打开后端服务器的健康检查功能,指令后面的参数意义是:
interval:向后端发送的健康检查包的间隔
fall(fall_count):如果连续失败次数达到fall_count,服务器就被认为是down
rise(rise_count):如果连续成功次数达到rise_count,服务器就被认为是up
timeout:后端健康请求的超时时间
default_down:设定初始时服务器的状态,如果是true,就说明默认是down的
type:健康检查包的类型,现在支持以下多种类型
tcp:简单的tcp连接,如果连接成功,就说明后端正常
ssl_hello:发送一个初始的SSL hello包并接受服务器的SSL hello包
http:发送HTTP请求,通过后端的回复包的状态来判断后端是否存活
mysql:向mysql服务器连接,通过接收服务器的greeting包来判断后端是否存活
ajp:向后端发送AJP协议的Cping包,通过接收Cpong包来判断后端是否存活
port:指定后端服务器的检查端口,你可以指定不同于真实服务的后端服务器的端口,比如后端提供的是443端口的应用,你可以去检查80端口的状态来判断后端健康状况。默认是0,表示跟后端server提供真实服务的端口一样该选项出现于Tengine-1.4.0
check_keepalive_requests
Syntax: check_keepalive_requests request_num Default: 1 Context: upstream
该指令可以配置一个连接发送的请求数,其默认值为1,表示Tengine完成1次请求后即关闭连接
check_http_send
Syntax: check_http_send http_packet Default: "GET / HTTP/1.0" Context: upstream
该指令可以配置http健康检查包发送的请求内容。为了减少传输数据量,推荐采用”HEAD”方法。当采用长连接进行健康检查时,需在该指令中添加keep-alive请求头,如:”HEAD / HTTP/1.1\r\nConnection: keep-alive\r\n\r\n”。同时,在采用”GET”方法的情况下,请求uri的size不宜过大,确保可以在1个interval内传输完成,否则会被健康检查模块视为后端服务器或网络异常
check_http_expect_alive
Syntax: check_http_expect_alive [ http_2xx | http_3xx | http_4xx | http_5xx ] Default: http_2xx | http_3xx Context: upstream
该指令指定HTTP回复的成功状态,默认认为2XX和3XX的状态是健康的
check_shm_size
Syntax: check_shm_size size Default: 1M Context: http
所有的后端服务器健康检查状态都存于共享内存中,该指令可以设置共享内存的大小。默认是1M,如果你有1千台以上的服务器并在配置的时候出现了错误,就可能需要扩大该内存的大小
check_status
Syntax: check_status [html|csv|json] Default: check_status html Context: location
显示服务器的健康状态页面。该指令需要在http块中配置。在Tengine-1.4.0以后,你可以配置显示页面的格式。支持的格式有: html、csv、 json。默认类型是html。你也可以通过请求的参数来指定格式,假设‘/status’是你状态页面的URL, format参数改变页面的格式
比如:
/status?format=html /status?format=csv /status?format=json
下面是一个HTML状态页面的例子(server number是后端服务器的数量,generation是Nginx reload的次数。Index是服务器的索引,Upstream是在配置中upstream的名称,Name是服务器IP,Status是服务器的状态,Rise是服务器连续检查成功的次数,Fall是连续检查失败的次数,Check type是检查的方式,Check port是后端专门为健康检查设置的端口)

下面是json格式

监控数据就是从这里获取,在zabbix的agent中添加脚本如下:
json
urllib3
():
url = http = urllib3.PoolManager()
up_status = http.request(url).data.decode()
up_status = json.loads(up_status)
upstreams = []
upserver up_status[][]:
status = {: upserver[]: upserver[]: upserver[]: upserver[]: upserver[]: upserver[]}
upstreams.append(status)
result = { : upstreams}
result
__name__ == :
:
(call_api())
e:
(e)
这里主要是把status返回的数据处理成zabbix需要的格式,因为我是用zabbix自动发现功能,所以这里直接写成遍历server,执行脚本输出如下:
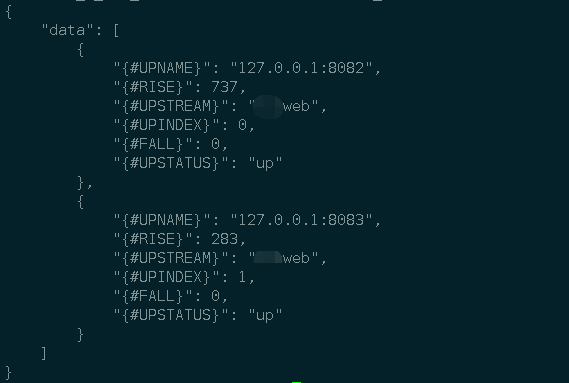
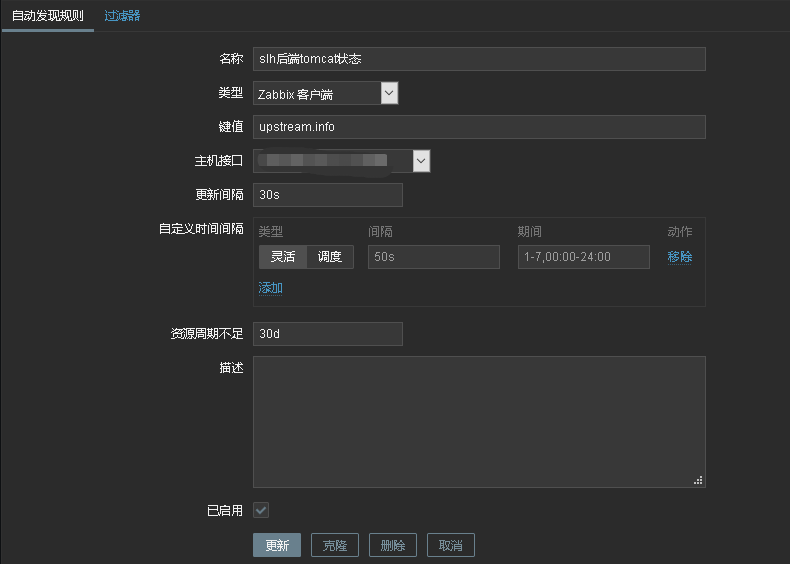
数据收集就没问题了,接着在zabbix中添加自动发现规则
接着添加监控项原型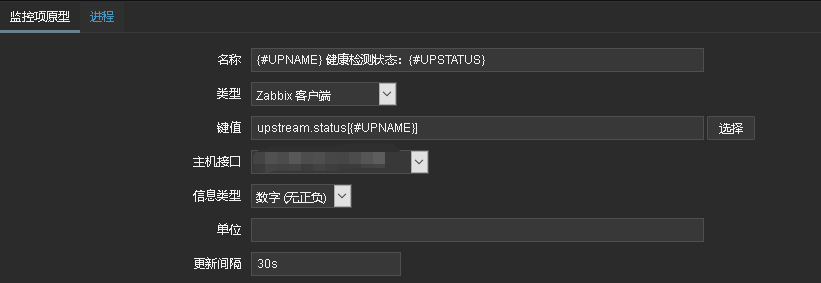
监控项原型主要是获取upstream后端server状态,接着添加触发器
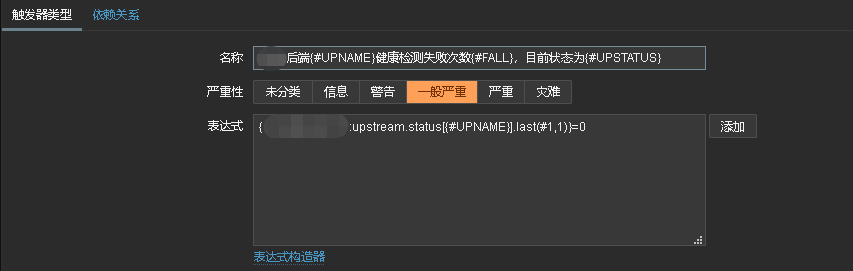
监控很简单,就添加完了,当upstream后端server状态down掉就会触发规则,将告警信息通过告警媒介发送到企业微信,当然你也可以是钉钉或短信,看你自己配置的告警媒介
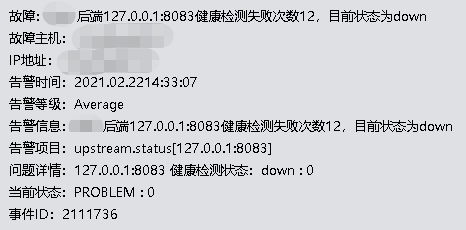
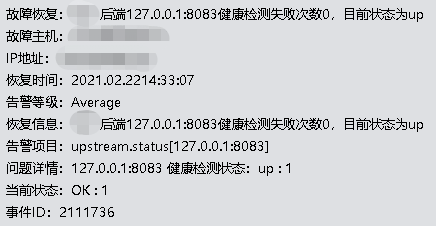
恢复后通知: