目录
- 一、字符串
-
- 1. 字符串基础知识
- 2. 字符串常见操作
-
- 2.1 连接字符串
- 2.2 字符串的常用方法
-
- 2.2.1 字符串检索方法:count()、find()、rfind()、index()、rindex()
- 2.2.2 替换字符串方法:replace() 、expandtabs()、translate()、maketrans()
- 2.2.3 分割字符串方法:split()、splitlines()、partition()、rpartition()
- 2.2.4 大小写转换方法:capitalize()、title()、lower()、upper()、swapcase()
- 2.2.5 字符串修剪方法:strip()、lstrip()、rstrip()
- 2.2.6 字符串填充方法:center()、ljust()、rjust()、zfill()
- 2.2.7 字符串检测方法:startswith()、endswith()、islower()、isupper()、istitle()、isdigit() 等
- 3. 课后练习
一、字符串
字符串几乎是所有编程语言在项目开发过程中,涉及最多的一块内容。大部分项目的运行结果,都需要以文本的形式展示给客户,比如财务系统的总账报表;电子游戏的比赛结果,火车站的列车时刻表等。这些都是经过程序精密的计算、判断和梳理,将我们想要的内容以文本形式直观地展示出来。曾经流传过这样一句话:开发一个项目,基本上就是在不断地处理字符串。本小节学习重点如下:
- 定义字符串。
- 字符串长度和编码。
- 字符串连接和截取。
- 字符串查找和替换。
- 熟悉字符串的其他常规操作。
1. 字符串基础知识
1.1 上节知识点补充
数字之间的逻辑运算,示例代码如下:
a = 0
b = 1
c = 2
# and运算符,只要有一个值为0,则结果为0,否则结果为最后一个非0数字
print(a and b) # 0
print(b and a) # 0
print(a and c) # 0
print(c and a) # 0
print(b and c) # 2
print(c and b) # 1
# or运算符,只有所有值为0结果才为0,否则结果为第一个非0数字
print(a or b) # 1
print(a or c) # 2
print(b or c) # 1
问题:1 or 2、1 and 2、0 and 2 or 1 or 4、0 or False and 1、1 < (2==2)、1 < 2 == 2 分别输出什么?
1.2 定义字符串、转义字符
在 Python 中,使用单引号 ' 或双引号 " 可以定义字符串。语法格式如下:
'内容'
"内容"
单引号和双引号常用于表示单行字符串。也可以在字符串中添加换行符 \n 间接定义多行字符串。

程序输出结果如下图所示:

在使用单引号定义的字符串中,可以直接包含双引号,而不必进行转义;而在使用双引号定义的字符串中,可以直接包含单引号,而不必进行转义。即外单内双,外双内单。示例代码如下:
str1 = "I'm Amo, a teacher!"
str2 = 'I "am" Amo, a teacher!'
print(str1)
print(str2)
print(type(str1), type(str2))
程序运行结果如下:

思考:如何创建一个字符串 I'm Amo?
注意:使用 type()函数返回结果为 <class 'str'>, 则数据类型为 str(字符串)。并且 Python 不支持字符类型,单个字符也算一个字符串。
单引号、双引号定义多行字符串时,需要添加换行符 \n,而三引号不需要添加换行符,语法格式如下:
'''多行
字符串'''
"""多行
字符串"""
同时字符串中可以包含单引号、双引号、换行符、制表符,以及其他特殊字符,对于这些特殊字符不需要使用反斜杠 \ 进行转义。另外,三引号中还可以包含注释信息。使用三引号定义一段 HTML 字符串,这时使用三引号定义非常方便,如果使用转义字符逐个转义特殊字符就非常麻烦,如下:
str3 = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>Hello World</h1>
</body>
<script>
console.log("amo is so cool~")
</script>
</html>
"""
三引号可以帮助开发人员从引号和转义字符的泥潭里面解脱出来,确保字符串的原始格式。三引号一般用于函数注释、类注释、定义 SQL 语句等,读者可以在 Python 源码中看到大量三引号的应用,如下:

使用 str() 函数可以创建空字符串,也可以将任意类型的对象转换为字符串。使用 str() 函数创建字符串的不同形式:

str() 函数的返回值由类型 __str__ 魔法方法决定。下面示例自定义一个 list 类型,定义 __str__ 魔法方法的返回值为 list 字符串表示,同时去掉左右两侧的中括号分隔符。如下:
class MyList(list): # 自定义list类型,继承于list
def __init__(self, value): # 类型初始化函数
self.value = list(value) # 把接受的参数转换为列表并存储起来
def __str__(self):
# 把传入的值转换为字符串,并去掉左右两侧的中括号分隔符
return str(self.value).replace("[", "").replace("]", "")
s = str(MyList([1, 2, 3]))
print(s)
字符串的输出:
print('hello world') # 直接输出
name = 'Amo'
print(name) # 输出变量
print('我的名字是%s' % name) # 格式化输出
print(f'我的名字是{name}') # 格式化输出
字符串的输入,在 Python 中,使用 input() 接收用户输入。
name = input('请输入您的名字:')
print(f'您输入的名字是{name}')
print(type(name))
password = input('请输入您的密码:')
print(f'您输入的密码是{password}')
print(type(password))
程序运行结果如下图所示:

输入的特点总结:
- 当程序执行到
input,等待用户输入,输入完成之后才继续向下执行。 - 在 Python 中,
input接收用户输入后,一般存储到变量,方便使用。 - 在 Python 中,
input会把接收到的任意用户输入的数据都当做字符串处理。
转义字符
在 Python 字符串中如果显示特殊字符,必须经过转义才能够显示。例如,换行符需要使用 \n 表示,制表符需要使用 \t 表示,单引号需要使用 \' ,双引号需要使用 \" 表示,等等。Python 可用的字符转义序列说明如下表所示:
| 转 义 序 列 | 含 义 |
|---|---|
| \newline(下一行) | 忽略反斜杠和换行 |
| \\ | 反斜杠(\) |
| \’ | 单引号(’) |
| \" | 双引号(") |
| \a | ASCII 响铃(BEL) |
| \b | ASCII 退格(BS) |
| \f | ASCII 换页(FF) |
| \n | ASCII 换行(LF) |
| \r | ASCII 回车(CR) |
| \t | ASCII 水平制表(TAB) |
| \v | ASCII 垂直制表(VT) |
| \ooo | 八进制的 ooo 的字符。与标准C中一样,最多可接收3个八进制数字 |
| \xhh | 十六进制值 hh 的字符。与标准C不同,只需要2个十六进制数字 |
| \N{name} | Unicode 数据库中名称为 name 的字符。【提示】:只在字符串字面值中识别的转义序列 |
| \uxxxx | 16 位的十六进制值为 xxxx 的字符。4个十六进制数字是必需的。【提示】:只在字符串字面值中识别的转义序列 |
| \Uxxxxxxxx | 32 位的十六进制值为 xxxxxxxx 的字符,任何 Unicode 字符可以这种方式被编码。8个十六进制数字是必需的。【提示】:只在字符串字面值中识别的转义序列 |
分别使用转义字符、八进制数字、十六进制数字表示换行符,如下:
str1 = "Hi, \nAmoXiang" # 使用转义字符\n表示换行符
str2 = "Hi, \12AmoXiang" # 使用八进制数字12表示换行符
str3 = "Hi, \x0aAmoXiang" # 使用十六进制数字 0a 表示换行符
print(str1)
print(str2)
print(str3)
程序运行结果如下图所示:

如果八进制数字不满3位,则首位自动补充0。如果八进制数字超出3位,十六进制数字超出2位,超出数字将视为普通字符显示,如下:
str1 = "Hi, \012AmoXiang" # 使用3位八进制数字表示换行符,最多允许使用3位八进制数字
str2 = "Hi, \12Python" # 使用2位八进制数字表示换行符
str3 = "Hi, \x0a0AmoXiang" # 最多允许使用2位十六进制数字
print(str1)
print(str2)
print(str3)
程序运行结果如下图所示:

1.3 原生字符串、Unicode 字符串、字符编码类型
在 Python3 中,字符串常见的有 3 种形式:普通字符串(str)、Unicode 字符串(unicode) 和原生字符串(也称原义字符串)。原生字符串的出现目的:解决在字符串中显示特殊字符。在原生字符串里,所有的字符都直接按照字面的意思来使用,不支持转义序列和非打印的字符。
原生字符串的这个特性让一些工作变得非常方便。例如,在使用正则表达式的过程中,正则表达式字符串,通常是由代表字符、分组、匹配信息、变量名和字符类等特殊符号组成。当使用特殊字符时,\字符 格式的特殊字符容易被歧义,这时使用原生字符串就会派上用场。可以使用 r 或 R 来定义原生字符串,这个操作符必须紧靠在第一个引号前面。语法格式如下:
r"原生字符串"
R"原生字符串"
定义文件路径的字符串时,会使用很多反斜杠,如果每个反斜杠都用歧义字符串来表示会很麻烦,可以采用下面代码来表示:
# str1 = "C:\Users\AmoXiang\PycharmProjects" # 直接写\ 会报错 \U转义
str2 = "C:\\Users\\AmoXiang\\PycharmProjects" # 转义字符
str3 = r"C:\Users\AmoXiang\PycharmProjects" # 不转义,使用原生字符串
# print(str1)
print(str2) # 输出:C:\Users\AmoXiang\PycharmProjects
print(str3) # 输出:C:\Users\AmoXiang\PycharmProjects
Unicode 字符串
从 Python 1.6 开始支持 Unicode 字符串,用来表示双字节、多字节字符、实现与其他字符编码的格式转换。在 Python 中,定义 Unicode 字符串与定义普通字符串一样简单,语法格式如下:
u'Unicode 字符串'
U"Unicode 字符串"
引号前面的操作符 u 或 U 表示创建的是一个 Unicode 字符串。如果想加入特殊字符,可以使用 Unicode 编码。例如:
str1 = u"Hello\u0020World"
print(str1) # 输出:Hello World
被替换的 \u0020 标识符表示在给定位置插入编码值为 0x0020 的 Unicode 字符(空格符)。Unicode 字符串的作用:u 操作符后面字符串将以 Unicode 格式进行编码,防止因为源码存储格式问题,导致再次使用时出现乱码。
unicode() 和 unichr() 函数可以作为 Unicode 版本的 str()和chr()。unicode()函数可以把任何 Python 的数据类型转换成一个 Unicode 字符串,如果对象定义了 __unicode__() 魔术方法,它还可以把该对象转换成相应的 Unicode 字符串。unichr() 函数和chr()函数功能基本一样,只不过返回 Unicode 的字符。
字符编码类型
字符编码就是把字符集中的字符编码为指定集合中某一对象,以便文本在计算机中存储和传递。常用字符编码类型如下。
- ASCII:全称为美国国家信息交换标准码,是最早的标准编码,使用 7 个或8个二进制位进行编码,最多可以给 256 个字符分配数值,包括 26 个大写与小写字母、10 个数字、标点符号、控制字符以及其他符号。
- GB2312:一个简体中文字符集,由 6763 个常用汉字和 682 个全角的非汉字字符组成。GB2312 编码使用两个字节表示一个汉字,所以理论上最多可以表示 256×256 =65536 个汉字。这种编码方式仅在中国通行。
- GBK:该编码标准兼容 GB2312,并对其进行扩展,也采用双字节表示。其共收录汉字 21003个、符号 883 个,提供 1894 个造字码位,简、繁体字融于一库。
- Unicode:是为了解决传统字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode 通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为 0 即可。
- UTF-8:为了提高 Unicode 的编码效率,于是就出现了 UTF-8 编码。UTF-8 可以根据不同的符号自动选择编码的长短。比如英文字母可以只用1个字节就够了。
读者想要详细了解可以点击 编码百度百科 进行学习。
1.4 字节串、字符编码和解码
在 Python 中,有两种常用的字符串类型,分别为 str 和 bytes。其中, str 表示 Unicode 字符(ASCII或者其他),bytes 表示二进制数据(包括编码的文本)。这两种类型的字符串不能拼接在一起使用。通常情况下,str 在内存中以 Unicode 表示,一个字符对应若干个字节。但是如果在网络上传输,或者存到磁盘上,就需要把 str 转换为字节类型,即 bytes 类型。
字节串(bytes)也称字节序列,是不可变的序列,存储以字节为单位的数据。提示:bytes 类型是 Python3 新增的一种数据类型。字节串与字符串的比较:
- 字符串是由多个字符构成,以字符为单位进行操作。默认为 Unicode 字符,字符范围为 0~65535。字符串是字符序列,它是一种抽象的概念,不能直接存储在硬盘,用以显示供人阅读或操作。
- 字节串是由多个字节构成,以字节为单位进行操作。字节是整型值,取值范围 0~255。字节串是字节序列,因此可以直接存储在硬盘。
除了操作单元不同外,字节串与字符串的用法基本相同。它们之间的映射被称为解码或编码。定义字节串的方法如下:
(1) 使用字面值:以 b 操作符为前缀的 ASCII 字符串。语法格式如下:
b"ASCII 字符串"
b"转义序列"
字节是 0~255 之间的整数,而 ASCII 字符集范围为 0~255,因此它们之间可以直接映射。通过转义序列可以映射更大规模的字符集。使用字面值直接定义字节串,如下:
# 创建空字节串的字面值
byte1 = b''
byte2 = b""
byte3 = b''''''
byte4 = b""""""
# 创建非空字节串的字面值
byte5 = b'ABCD'
byte6 = b'\x41\x42'
print(byte1)
print(byte6)
(2) 使用 bytes() 函数:使用 bytes() 函数可以创建一个字节串对象,简明语法格式如下:
bytes() # 生成一个空的字节串,等同于b''
bytes(整型可迭代对象) # 用可迭代对象初始化一个字节串,元素必须为[0,255]中的整数
bytes(整数n) # 生成n个值为零的字节串
bytes('字符串', encoding='编码类型') # 使用字符串的转换编码生成一个字节串
下面示例使用 bytes()函数创建多个字节串对象:
a = bytes() # 等效于b''
b = bytes([10, 20, 30, 65, 66, 67]) # 等效于b'\n\x14\xleABC'
print(b)
c = bytes(range(65, 65 + 26))
print(c)
d = bytes(5)
print(d)
e = bytes('hello 中国', 'utf-8')
print(e)
程序运行结果如下:

字节串是不可变序列,使用 bytearray() 可以创建可变的字节序列,也称为字节数组(bytearray)。数组是每个元素类型完全相同的一组列表,因此可以使用操作列表的方法来操作数组。bytearray() 函数的简明语法格式如下:
bytearray() # 生成一个空的可变字节串,等同于 bytearray(b'')
bytearray(整型可迭代对象) # 用可迭代对象初始化一个可变字节串,元素必须为 [0, 255] 中的整数
bytearray(整数n) # 生成 n 个值为零的可变字节串
bytearray(字符串, encoding='utf-8') # 用字符串的转换编码生成一个可变字节串
字符编码和解码
在编码转换时,通常以 Unicode 作为中间码,即先将一种类型的字符串解码(decode)成 Unicode,再从 Unicode 编码(encode)成另一种类型的字符串。
(1) 使用 encode()
使用字符串对象的 encode()方法可以根据参数 encoding 指定的编码格式将字符串编码为二进制数据的字节串,语法格式如下:
str.encode(encoding='UTF-8', errors='strict')
str 表示字符串对象:参数 encoding 表示要使用得编码类型,默认为 UTF-8 ,参数 errors 设置不同错误的处理方案,默认为 strict,表示遇到非法字符就会抛出异常,其他取值包括 ignore(忽略非法字符)、replace(用 ? 替换非法字符)、xmlcharrefreplace (使用 XML 的字符引用)、backslashreplace ,以及通过 codecs.register_error() 注册的任何值。
【示例1】本例使用 encode()方法对 中文 字符串进行编码。
u = "中文"
str1 = u.encode("gb2312")
print(str1)
str2 = u.encode("gbk")
print(str2)
str3 = u.encode("utf-8")
print(str3)
(2) 使用 decode()
与 encode() 方法操作相反,使用 decode()方法可以解码字符串,即根据参数 encoding 指定的编码格式将二进制数据的字节串解码为字符串。语法格式如下:
str.decode(encoding='UTF-8', errors='strict')
str 表示被 decode()解码的字节串,该方法的参数与 encode()方法的参数用法相同。最后返回解码后的字符串。
【示例2】针对示例1,可以使用下面代码对编码字符串进行解码。
u = "中文"
str1 = u.encode("gb2312")
u1 = str1.decode("gb2312")
print(u1) # 输出:中文
u2 = str1.decode("utf-8") # 报错,因为str1是gb2312编码的
"""
报错如下:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 0: invalid continuation byte
"""
encode()和decode()方法的参数编码格式必须一致,否则将抛出上面代码所示的异常。
1.5 计算字符串的长度、访问字符串、遍历字符串
由于不同的字符所占字节数不同,所以要计算字符串的长度,需要先了解各字符所占的字节数。在 Python 中,数字、英文、小数点、下划线和空格占一个字节;一个汉字可能会占 2~4 个字节,占几个字节取决于采用的编码。汉字在 GBK/GB2312 编码中占 2 个字节,在 UTF-8/unicode 编码中一般占用 3个字节(或4个字节)。下面以 Python 默认的 UTF-8 编码为例进行说明,即一个汉字占 3 个字节,如下图所示。

在 Python 中,提供了 len() 函数计算字符串的长度,语法格式如下:
len(string)
其中,string 用于指定要进行长度统计的字符串。例如,定义一个字符串,内容为 人生苦短,我用 Python!,然后应用 len() 函数计算该字符串的长度,代码如下:

上面的代码在执行后,将输出结果15。从上面的结果中可以看出,在默认的情况下,通过 len() 函数计算字符串的长度时,不区分英文、数字和汉字,所有字符都按一个字符计算。在实际开发时,有时需要获取字符串所占的实际字节数,即如果采用 UTF-8 编码,汉字占3个字节,采用 GBK 或者 GB2312 编码时,汉字占2个字节。这时,可以通过使用 encode() 方法进行编码后再进行获取。示例代码如下:

获取采用 UTF-8 编码的字符串的长度:因为汉字加中文标点符号共7个,占 21 个字节,英文字母和英文的标点符号占8个字节,共29个字节。获取采用 GBK 编码的字符串的长度:因为汉字加中文标点符号共7个,占14个字节,英文字母和英文标点符号占8个字节,共22个字节。
访问字符串
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。Python 访问字符串中的字符有两种方式。
(1) 索引访问。索引又叫 下标,就是编号。比如火车座位号,座位号的作用:按照编号快速找到对应的座位。同理,索引的作用即是通过索引快速找到对应的数据。

在 Python 中,字符串是一种有序序列,字符串里的每一个字符都有一个数字编号标识其在字符串中的位置,从左至右依次是:0、1、2、…、n-1,如图所示:

Python 比较神奇,它的索引可以是负数。这个索引从右向左计数,也就是从最后的一个元素开始计数,从右至左依次是 -1、-2、-3、…、-n(其中 n 是字符串的长度)。如图所示:

通过索引来访问字符串中的某个字符。代码如下:
str1 = "AmoXiang" # 定义字符串
print(str1[2]) # 读取第3个字符,输出为o
print(str1[-2]) # 读取倒数第2个字符,输出为n
(2) 切片访问。切片操作是访问字符串元素的另一种方法,它可以访问一定范围内的元素。通过切片操作可以生成一个新的字符串。字符串、列表、元组 都支持切片操作。实现切片操作的语法如下:
sname[start:end:step]
参数说明:
- sname:表示字符串的名称,也就是变量名。
- start:索引值,表示切片的开始位置(包括该位置),如果不指定,则默认为 0。
- end:索引值,表示切片的截止位置(不包括该位置),如果不指定,则默认为字符串的长度。
- step:表示切片的步长(正负数都可以),如果省略,则默认为1,当省略该步长时,最后一个冒号也可以省略。
字符串切片示例代码如下:
str1 = "123456789123456789"
print(str1[0:6]) # 输出:123456
print(str1[1:20:2]) # 输出:246813579
str2 = "abcdefghijklmnopqrstuvwxyz"
print(str2[:20]) # 不指定start,则从第1个字符开始,输出:abcdefghijklmnopqrst
print(str2[20:]) # 不指定end,则直到结尾字符,输出:uvwxyz
print(str2[:-6]) # 指定end为负数,则从右向左倒数第6个字符
print(str2[:]) # 不指定start和end,相当于print(str2)
print(str2[::3]) # 仅指定步长:adgjmpsvy
print(str2[::-1]) # 逆序(反转)输出:zyxwvutsrqponmlkjihgfedcba
print(str2[:19:-1]) # 倒序输出最后6个字符zyxwvu
print(str2[-10:-19:-1]) # 倒序输出中间9个字符:qponmlkji
注意:当切片的第3个参数为负数时,表示逆序输出,即输出顺序为从右到左,而不是从左到右,切片的方向一定要保持一致,例如:str2[1:10:-1] 1:10 表示是从左到右顺序,而步长为-1,表示从右到左顺序,方向不一致,所以最后切片的结果一定为空。练习:说出下面程序的输出结果。
name = "abcdefg"
print(name[2:5:1])
print(name[2:5])
print(name[:5])
print(name[1:])
print(name[:])
print(name[::2])
print(name[:-1])
print(name[-4:-1])
print(name[::-1])
print(name[-1:-3:1])
遍历字符串
在字符串过滤、筛选和编码时,经常需要遍历字符串。遍历字符串的方法有多种,具体说明如下。【示例1】使用 for 语句循环遍历字符串,然后把每个字符都转换为大写形式并输出:
s1 = "python" # 定义字符串
L = [] # 定义临时备用列表
for i in s1: # 迭代字符串
L.append(i.upper()) # 把每个字符转换为大写形式
print("".join(L)) # 输出大写字符串 PYTHON
使用 range() 函数,然后把字符串长度作为参数传入。【示例2】针对示例1,也可以按照以下方式遍历字符串。
s1 = "python" # 定义字符串
L = [] # 定义临时备用列表
for i in range(len(s1)): # 根据字符串长度遍历字符串下标数字,
# 从0开始,直到字符串长度
L.append(s1[i].upper()) # 把每个字符转换为大写形式
print("".join(L)) # 输出大写字符串 PYTHON
使用 enumerate()。enumerate() 函数将一个可迭代的对象组合为一个索引序列。【示例3】针对示例1,使用 enumerate() 函数将字符串转换为索引序列,然后再迭代操作。
s1 = "python" # 定义字符串
L = [] # 定义临时备用列表
for i, char in enumerate(s1): # 把字符串转换为索引序列,然后再遍历
L.append(char.upper()) # 把每个字符转换为大写形式
print("".join(L)) # 输出大写字符串 PYTHON
使用 iter()。使用 iter() 函数可以生成迭代器。语法格式如下:
iter(object[, sentinel])
参数 object 表示支持迭代的集合对象,sentinel 是一个可选参数,如果传递了第 2 个参数,则参数 object 必须是一个可调用的对象(如函数),此时,iter() 函数将创建一个迭代器对象,每次调用这个迭代器对象的 __next__() 方法时,都会调用 object。【示例4】针对示例1,使用 iter() 函数将字符串生成迭代器,然后再遍历操作。
s1 = "python" # 定义字符串
L = [] # 定义临时备用列表
for item in iter(s1): # 把字符串生成迭代器,然后再遍历
L.append(item.upper()) # 把每个字符转换为大写形式
print("".join(L)) # 输出大写字符串 PYTHON
逆序遍历。逆序遍历就是从右到左反向迭代对象。【示例5】本示例演示了 3 种逆序遍历字符串的方法。
s1 = "Python"
print("1. 通过下标逆序遍历:")
for i in s1[::-1]:
print(i, end="")
print("\n2. 通过下标逆序遍历:")
for i in range(len(s1) - 1, -1, -1):
print(s1[i], end="")
print("\n3. 通过reversed()逆序遍历:")
for i in reversed(s1):
print(i, end="")
案例1:判断两个字符串是否为变形词
假设给定两个字符串 str1、str2,判断这两个字符串中出现的字符是否一致,字符数量是否一致,当两个字符串的字符和数量一致时,则称这两个字符串为变形词。例如:
str1 = "python", str2="thpyon", 返回True
str2 = "python", str2="thonp", 返回False
示例代码如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:2.判断两个字符串是否为变形词.py
@time:2021/01/16
"""
def is_deformation(str1, str2): # 定义变形词函数
if str1 is None or str2 is None or len(str1) != len(str2): # 当条件不符合时
return False # 返回False
if len(str1) == 0 and len(str2) == 0: # 当两个字符串长度都为0时
return True # 返回True
dic = dict() # 定义一个空字典
for char in str1: # 循环遍历字符串str1
if char not in dic: # 判断字符是否在字典中
dic[char] = 1 # 不存在时,赋值为1
else:
dic[char] = dic[char] + 1 # 存在时字符的值累加
for char in str2: # 循环遍历字符串str2
if char not in dic: # 当str2的字符不在字典中时 返回False
return False
else:
dic[char] = dic[char] - 1 # 当str2和str1的字符种类一致时,字典中的字符值自减1
# 字符的值小于0,即字符串的字符数量不一致 返回False 否则返回True
if dic[char] < 0:
return False
return True
str1 = "python"
str2 = "thpyon"
str3 = "hello"
str4 = "helo"
# 输出:python thpyon is deformation: True
print(str1, str2, "is deformation:", is_deformation(str1, str2))
# 输出:hello helo is deformation: False
print(str3, str4, "is deformation:", is_deformation(str3, str4))
案例2:字节串的应用之计算md5
在计算 md5 值的过程中,有一步要使用 update 方法,而该方法只接受 bytes 类型数据。
import hashlib
string = "123456"
m = hashlib.md5() # 创建md5对象
str_bytes = string.encode(encoding='utf-8')
print(type(str_bytes)) # <class 'bytes'>
m.update(str_bytes) # update方法只接收bytes类型数据作为参数
str_md5 = m.hexdigest() # 得到散列后的字符串
print('MD5散列前为 :' + string) # MD5散列前为 :123456
print('MD5散列后为 :' + str_md5) # MD5散列后为 :e10adc3949ba59abbe56e057f20f883e
案例3:二进制读写文件。
使用二进制方式读写文件时,均要用到 bytes 类型,二进制写文件时,write()方法只接受 bytes 类型数据,因此需要先将字符串转成 bytes 类型数据;读取二进制文件时,read()方法返回的是 bytes 类型数据,使用 decode()方法可将 bytes 类型转成字符串。
f = open('data.txt', 'wb')
text = '二进制写文件'
text_bytes = text.encode('utf-8')
f.write(text_bytes)
f.close()
f = open('data.txt', 'rb')
data = f.read()
print(data, type(data))
str_data = data.decode('utf-8')
print(str_data)
f.close()
2. 字符串常见操作
在 Python 的开发过程中,为了实现某项功能,经常需要对某些字符串进行特殊处理,如拼接字符串、截取字符串、格式化字符串等。下面将对 Python 中常用的字符串操作方法进行介绍。
2.1 连接字符串
连接字符串就是将不同的字符串直接或者通过指定的分隔符组合到一起变成一个字符串。在 Python 中,主要有两种方法:拼接和合并,下面分别进行介绍。使用 + 运算符可以完成对多个字符串的拼接,+ 运算符可以连接多个字符串并产生一个字符串对象。例如,定义两个字符串:一个用于保存英文版的名言;另一个用于保存中文版的名言,然后使用 + 运算符连接,代码如下:
mot_en = "Remembrance is a form of meeting. Forgetfulness is a form of freedom."
mot_cn = "记忆是一种相遇。遗忘是一种自由。"
print(mot_en + "-" + mot_cn)
字符串不允许直接与其他类型的数据拼接,例如,使用下面的代码将字符串与数值拼接在一起,将产生下图所示的异常:

在解决该问题时,可以将整数转换为字符串,然后以拼接字符串的方式输出该内容。将整数转换为字符串,可以使用 str() 函数,修改后的代码如下:
str1 = "今年我刚满" # 定义字符串
age = 18 # 定义一个整数
str2 = "岁" # 定义字符串
print(str1 + str(age) + str2)
如果想要将一个字符串复制多次,则可以使用乘法实现。例如,将一个字符串 “Amo 很酷!” 复制5次并输出,代码如下:
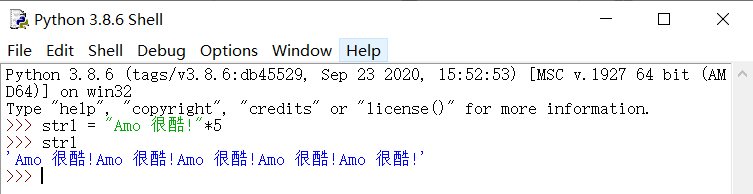
合并字符串与拼接字符串不同,它会将多个字符串采用固定的分隔符连接在一起。例如,字符串 Amo*Paul*Jason*Ben,就可以看作是通过分隔符 * 将 [“Amo”, "Paul’, “Jason”, “Ben”] 列表合并为一个字符串的结果。合并字符串可以使用字符串对象的 join() 方法实现,语法如下:
str_new = string.join(iterable)
参数说明:
- str_new:表示合并后生成的新字符串。
- string:字符串类型,用于指定合并时的分隔符。
- iterable:可迭代对象,该迭代对象中的所有元素(用字符串表示)将被合并为一个新的字符串。string 作为边界点分割出来。
示例代码如下:
list_friend = ["Amo", "Paul", "Jason", "Ben"] # 好友列表
str_friend = " @".join(list_friend) # 用空格+@符号进行连接
at = "@" + str_friend
print(f"您要@的好友:{at}")
程序运行结果如下图所示:

其他示例如下:

补充:在 Python 中,只要把两个字符串放在一起,中间有空白或者没有空白,两个字符串将自动连接为一个字符串。示例如下:
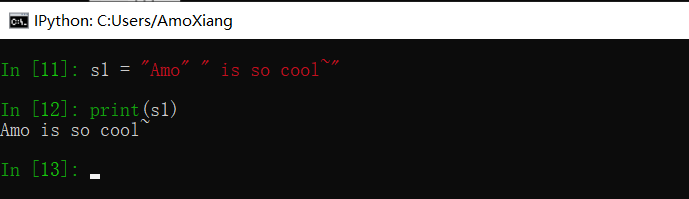
上述方法只能用在字符串字面值之间,不能够用在字符串变量之间。在 print() 函数中,如果两个字符串被逗号分隔,那么这两个字符串将被连续输出,但是字符串之间会多出一个空格。例如:
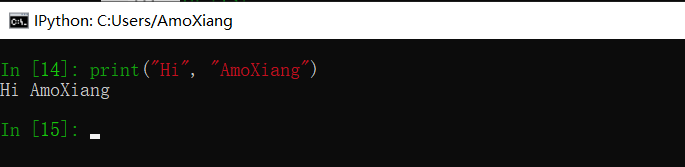
上述方法仅能用在 print() 函数内,如果用在其他场合,将被视为元组对象。
2.2 字符串的常用方法
2.2.1 字符串检索方法:count()、find()、rfind()、index()、rindex()
(1) count():count() 方法用于统计字符串里某个子字符串出现的次数。如果检索的子字符串不存在,则返回0;否则返回出现的次数,语法格式如下:
str.count(sub, start=0, end=len(string))
str 表示字符串。参数 sub 表示要检索的子字符串;start 表示字符串开始统计的位置,默认为第 1 个字符(索引值为 0);end 表示字符串中结束统计的位置,默认为字符串的最后一个位置。示例代码如下:

(2) find() 方法:该方法用于检索是否包含指定的子字符串。如果检索的字符串不存在,则返回 -1;否则返回首次出现该子字符串时的索引。语法如下:
str.find(sub, start=0, end=len(string))
str 表示原字符串。参数 sub 表示要检索的子字符串。start 可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。end 可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。使用 find() 方法检索 长 在字符串中的索引位置。示例代码如下:
my_str = "海水朝朝朝朝朝朝朝落,浮云长长长长长长长消"
sub = "长" # 要检索的字符串
print(my_str.find(sub)) # 在整个字符串中检索,输出:13
print(my_str.find(sub, 14)) # 从下标14位置开始检索,输出为:14
print(my_str.find(sub, 10, 13)) # 从下标10~13 范围开始检索,输出为-1,没有找到
检索范围包含起始点位置,但不包含中止点位置。Python 中的字符串对象还提供了 rfind() 方法,其作用与 find() 方法类似,只是从字符串的右边开始查找。把上面的 find() 方法改为 rfind() 方法,如下:
my_str = "海水朝朝朝朝朝朝朝落,浮云长长长长长长长消"
sub = "长" # 要检索的字符串
print(my_str.rfind(sub)) # 在整个字符串中检索,输出:19
print(my_str.rfind(sub, 14)) # 从下标14位置开始检索,输出为:19
print(my_str.rfind(sub, 10, 13)) # 从下标10~13 范围开始检索,输出为-1,没有找到
(3) index() 方法:index() 方法同 find() 方法类似,也是用于检索是否包含指定的子字符串。只不过如果使用 index() 方法,当指定的字符串不存在时会显示异常。语法如下:
str.index(sub, start=0, end=len(string))
str 表示原字符串。参数 sub 表示要检索的子字符串。start 可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。end 可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。使用 index() 方法检索 长 在字符串中的索引位置。示例代码如下:
my_str = "海水朝朝朝朝朝朝朝落,浮云长长长长长长长消"
sub = "长" # 要检索的字符串
print(my_str.index(sub)) # 在整个字符串中检索,输出:13
print(my_str.index(sub, 14)) # 从下标14位置开始检索,输出为:14
print(my_str.index(sub, 10, 13)) # 从下标10~13 范围开始检索,没有找到,抛出异常 ValueError
程序运行结果如下图所示:

Python 的字符串对象还提供了 rindex() 方法,其作用与 index() 方法类似,只是要从右边开始查找。总结:index() 方法和 find() 方法的功能和用法相同。rindex() 与 rfind() 方法的功能和用法相同。唯一区别是:当 index() 和 rindex() 方法搜索不到子字符串时,将抛出 ValueError 错误。
2.2.2 替换字符串方法:replace() 、expandtabs()、translate()、maketrans()
(1) replace() 方法:replace() 方法用于将一个字符串的子字符串替换为另一个字符串,并且返回被替换后的字符串。如果未找到要替换的字符串,则返回原字符串。语法如下:
str.replace(old, new, count)
str 表示原字符串。old 表示要替换的字符串。new 表示替换后的字符串。count 可选参数,表示替换次数,如果不指定,则全部替换。示例代码如下:
my_str = "hello world and amoxiang and amo and Python"
print(my_str)
# 结果:hello world And amoxiang And amo And Python
print(my_str.replace('and', 'And'))
# 结果:hello world And amoxiang And amo and Python
print(my_str.replace('and', 'And', 2))
print(my_str.replace('and', 'And', 10))
程序运行结果如下图所示:

注意:数据按照是否能直接修改分为 可变类型 和 不可变类型 两种。字符串类型的数据修改的时候不能改变原有字符串,属于不能直接修改数据的类型即是不可变类型。
(2) expandtabs() 方法:把字符串中的 Tab 符号( \t ) 转为空格,Tab (\t) 符号默认的空格数是8,语法格式如下:
str1.expandtabs(tabsize=8)
参数 tabsize 指定转换字符串中的 Tab 符号转为空格的字符数,默认值为8。使用方法如下:

expandtabs(8) 不是将 \t 直接替换为8个空格,而是根据 Tab 字符前面的字符数确定替换宽度。示例代码如下:
print(len("1\t".expandtabs(8))) # 输出为8,添加7个空格
print(len("12\t".expandtabs(8))) # 输出为8,添加6个空格
print(len("123\t".expandtabs(8))) # 输出为8,添加5个空格
print(len("1\t1".expandtabs(8))) # 输出为9,添加7个空格
print(len("12\t12".expandtabs(8))) # 输出为10,添加6个空格
print(len("123\t123".expandtabs(8))) # 输出为11,添加5个空格
print(len("123456781\t".expandtabs(8))) # 输出为16,添加7个空格
print(len("1234567812345678\t".expandtabs(8))) # 输出为24,添加8个空格
结果分析:使用 \t 前面字符的个数对 8 取余数,添加空格的数量 = 8 - 余数。
(3) translate() 和 maketrans() 方法:translate() 方法能够根据参数表翻译字符串中的字符。语法格式如下:
str.translate(table)
bytes.translate(table[, delete])
bytearray.translate(table[, delete])
str 表示字符串对象;bytes 表示字节串;bytearray 表示字节数组。参数 table 表示翻译表,翻译表通过 maketrans() 方法生成。translate() 方法返回翻译后的字符串,如果设置了 delete 参数,则将原来 bytes 中属于 delete 的字符删除,剩下的字符根据参数 table 进行映射。maketrans() 方法用于创建字符映射的转换表。语法格式如下:
str.maketrans(intab, outtab[, delchars])
bytes.maketrans(intab, outtab)
bytearray.maketrans(intab, outtab)
第1个参数是字符串,表示需要转换的字符。第2个参数也是字符串,表示要转换的目标,两个字符串的长度必须相同,为一一对应的关系。第3个参数为可选参数,表示要删除的字符组成的字符串。
【示例1】使用 str.maketrans() 方法生成一个大小写字母映射表,然后把字符串全部转换为小写。
a = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" # 大写字符集
b = "abcdefghijklmnopqrstuvwxyz" # 小写字符集
table = str.maketrans(a, b) # 创建映射表
s = "PYTHON"
print(s.translate(table)) # 输出:python
【示例2】针对示例1,可以设置要删除的字符,如 THON。
a = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" # 大写字符集
b = "abcdefghijklmnopqrstuvwxyz" # 小写字符集
de = "THON" # 删除字符集
t1 = str.maketrans(a, b) # 创建字符映射转换表
t2 = str.maketrans(a, b, de) # 创建字符映射转换表,并删除指定字符
s = "PYTHON" # 原始字符串
print(s.translate(t1)) # 输出:python
print(s.translate(t2)) # 输出:py
【示例3】可以把普通字符串转换为字节串,然后使用 translate() 方法先删除再转换。
a = b"ABCDEFGHIJKLMNOPQRSTUVWXYZ" # 大写字节型字符集
b = b"abcdefghijklmnopqrstuvwxyz" # 小写字节型字符集
de = b"THON" # 删除字节型字符集
t1 = bytes.maketrans(a, b) # 创建字节型字符映射转换表
s = b"PYTHON" # 原始字节串
s = s.translate(None, de) # 若table参数为None,则只删除不映射
s = s.translate(t1) # 执行映射转换
print(s) # 输出:b'py'
2.2.3 分割字符串方法:split()、splitlines()、partition()、rpartition()
(1) split() 方法:字符串对象的 split() 方法可以实现字符串分割,也就是把一个字符串按照指定的分隔符切分为字符串列表。在该列表的元素中,不包括分隔符。split() 方法的语法如下:
str.split(sep,maxsplit)
str 表示要进行分割的字符串。sep 用于指定分隔符,可以包含多个字符,默认为 None,即所有的空字符(包括空格、换行 \n、制表符 \t等)。maxsplit 可选参数,用于指定分割的次数,如果不指定或者为 -1,则分割次数没有限制,否则返回结果列表的元素个数最多为 maxsplit+1。方法返回值:分隔后的字符串列表。该列表的元素为以每个分隔符为界限进行分割后的字符串(不包括分隔符),当该分割符前面(或者与前一个分隔符之间)没有内容时,将返回一个空字符串元素。在 split() 方法中,如果不指定 sep 参数,那么也不能指定 maxsplit 参数。示例代码如下:

拓展1:演示 splitlines() 方法的基本使用。
str1 = "a\n\nb\rc\r\nd"
t1 = str1.splitlines() # 不包含换行符
t2 = str1.splitlines(True) # 包含换行符
print(t1) # 输出:['a', '', 'b', 'c', 'd']
print(t2) # 输出:['a\n', '\n', 'b\r', 'c\r\n', 'd']
splitlines() 方法实际上就是 split() 方法的特殊应用。即以行(\r、\r\n、\n) 为分隔符来分割字符串,返回一个包含各行字符串作为元素的列表。语法格式:
str.splitlines([keepends])
参数 keepends 默认为 False,如果为 False,则每行元素中不包含行标识符;如果为 True,则元素中保留标识符。
拓展2:使用 partition() 和 rpartition() 方法。使用 partition() 方法可以根据指定的分隔符将字符串进行分割。语法格式如下:
str.partition(sep)
参数 sep 表示分隔的子字符串(分隔符)。如果字符串中包含指定的分隔符,则返回一个包含3个元素的元组。第1个元素为分隔符左边的子字符串。第2个元素为分隔符本身,第3个元素为分隔符右边的子字符串。示例代码如下:
str1 = "https://blog.csdn.net/xw1680"
print(str1.partition(".")) # 输出:('https://blog', '.', 'csdn.net/xw1680')
print(str1.rpartition(".")) # 输出:('https://blog.csdn', '.', 'net/xw1680')
print(str1.partition("|")) # 输出:('https://blog.csdn.net/xw1680', '', '')
rpartition() 方法类似于 partition() 方法,只是该方法是从目标字符串的右边开始搜索分隔符。
2.2.4 大小写转换方法:capitalize()、title()、lower()、upper()、swapcase()
(1) capitalize() 方法:将字符串的第一个字母变成大写,其他字母变成小写。语法格式如下:
str.capitalize()
该方法没有参数,返回值为生成的新字符串。例如:
str1 = "I Love Amo" # 定义字符串
print(str1.capitalize()) # 输出:I love amo
(2) title() 方法:返回标题化的字符串,即字符串中每个单词首字母大写,其余字母均为小写。语法格式如下:
str.title()
该方法没有参数,返回值为生成的新字符串。例如:
str1 = "i love amo" # 定义字符串
print(str1.title()) # 输出:I Love Amo
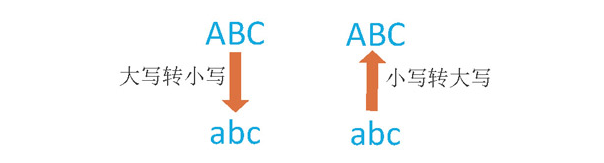
(3) 在 Python 中,字符串对象提供了 lower() 方法和 upper() 方法进行字母的大小写转换,即可用于将大写字母转换为小写字母,或者将小写字母转换为大写字母,示意如下图所示。
lower() 方法用于将字符串中的大写字母转换为小写字母。如果字符串中没有需要被转换的字符,则将原字符串返回;否则将返回一个新的字符串,将原字符串中每个需要进行小写转换的字母都转换成等价的小写字母。字符长度与原字符长度相同。lower() 方法的语法如下:
str.lower() # str 为要进行转换的字符串
upper() 方法用于将字符串中的小写字母转换为大写字母。如果字符串中没有需要被转换的字符,则将原字符串返回;否则返回一个新字符串,将原字符串中每个需要进行大写转换的字母都转换成等价的大写字母。新字符的长度与原字符的长度相同。upper() 方法的语法如下:
str.upper() # str 为要进行转换的字符串
两个方法都没有参数,lower() 方法返回为小写后生成的字符串。upper() 方法为大写后生成的字符串。示例代码如下:

(4) swapcase() 方法:将字符串的大小写字母进行转换。语法格式如下:
str.swapcase()
该方法没有参数,返回大小写字母转换后生成新的字符串。例如:
str1 = "I Love Amo" # 定义字符串
print(str1.swapcase()) # 输出:i lOVE aMO
2.2.5 字符串修剪方法:strip()、lstrip()、rstrip()
去除字符串中的空格和特殊字符。用户在输入数据时,可能会无意中输入多余的空格;或在一些情况下,字符串前后不允许出现空格和特殊字符,此时就需要去除字符串中的空格和特殊字符。例如,下图中 HELLO 这个字符串的前后都有一个空格。可以使用 Python 中的字符串提供的 strip() 方法去除字符串左右两边的空格和特殊字符;也可以使用字符串的 lstrip() 方法去除字符串左边的空格和特殊字符,再使用字符串的 rstrip() 方法去除字符串中右边的空格和特殊字符。

这里的特殊字符是指制表符 \t、回车符\r、换行符\n 等。
(1) strip() 方法用于去掉字符串左、右两侧的空格和特殊字符。语法格式如下:
str.strip([chars])
str 为要去除空格和特殊字符的字符串。chars 为可选参数,用于指定要去除的字符,可以指定多个。如果设置chars为 @. 则去除左、右两侧包括的 @ 或 .;如果不指定 chars 参数,默认将去除空格、制表符\t、回车符\r、换行符\n等。示例代码如下:
str1 = "https://blog.csdn.net/xw1680?\t\n\r"
print(f"原字符串str1: {str1}。")
print(f"字符串 : {str1.strip()}。")
str2 = "@厦门大学.@."
print(f"原字符串str2: {str2}。")
print(f"字符串 : {str2.strip('@.')}。")
程序运行结果如下图所示:

(2) lstrip() 方法用于去掉字符串左侧的空格和特殊字符。语法格式如下:
str.lstrip([chars])
str 为要去除空格和特殊字符的字符串。chars 为可选参数,用于指定要去除的字符,可以指定多个。如果设置chars为 @. 则去除左、右两侧包括的 @ 或 .;如果不指定 chars 参数,默认将去除空格、制表符\t、回车符\r、换行符\n等。示例代码如下:

(3) rstrip() 方法用于去掉字符串右侧的空格和特殊字符,语法格式如下:
str.rstrip([chars])
str 为要去除空格和特殊字符的字符串。chars 为可选参数,用于指定要去除的字符,可以指定多个。如果设置chars为 @. 则去除左、右两侧包括的 @ 或 .;如果不指定 chars 参数,默认将去除空格、制表符\t、回车符\r、换行符\n等。示例代码如下:

总结:无论是 strip() 方法,还是 lstrip() 和 rstrip() 方法,可以清除指定的字符串,字符串可以是一个字符或者多个字符,匹配时不是按照整体进行匹配,而是逐个进行匹配。
2.2.6 字符串填充方法:center()、ljust()、rjust()、zfill()
(1) center() 方法:使用 center() 方法可以设置字符串居中显示。语法格式如下:
str.center(width[, fillchar])
str 表示字符串对象。参数 width 表示字符串的总宽度,单位为字符;fillchar 表示填充字符,默认值为空格。center() 方法将根据 width 设置的宽度居中,然后使用 fillchar 参数填充空余区域,默认填充字符为空格。
【示例1】设置一个总宽度为20的字符串,然后定义子字符串 Python 居中显示,剩余空间填充为下划线。

(2) ljust() 和 rjust():ljust() 方法能够返回一个原字符串左对齐,并使用指定字符填充至指定长度的新字符串。rjust() 方法与 ljust() 方法操作相反,它返回一个原字符串右对齐,并使用指定字符填充至指定长度的新字符串。语法格式如下:
str.ljust(width[, fillchar])
str.rjust(width[, fillchar])
参数说明与 center() 相同。同样,如果指定的长度小于原字符串的长度,则返回原字符串。
【示例2】针对示例1,分别使用 ljust()和rjust() 方法设置字符串左对齐和右对齐显示,同时定义字符串总宽度为20个字符。

(3) zfill() 方法:zfill() 方法实际上是 rjust() 方法的特殊用法,它能够返回指定长度的字符串,原字符串右对齐,前面填充参数0。语法格式如下:
str.zfill(width)
参数 width 指定字符串的长度。
【示例3】设计随机生成一个 1~999 之间的整数,为了整齐显示随机数,本示例使用 zfill() 设置随机数总长度为3。

2.2.7 字符串检测方法:startswith()、endswith()、islower()、isupper()、istitle()、isdigit() 等
(1) endswith() 方法:用于判断字符串是否以指定的字串结尾,如果以指定后缀结尾,则返回 True;否则返回 False,语法格式如下:
str.endswith(suffix[, start=0[, end=len(str)]])
str 表示字符串对象。参数 suffix 可以是一个字符串或者一个元素;start 表示检索字符串中的开始位置,默认值为 0;end 表示检索字符中的结束位置,默认值为字符串的长度。
startswith() 方法用于判断字符串是否以指定的字串开头,用法与 endswith() 方法相同。
str.startswith(suffix[, start=0[, end=len(str)]])

(2) 其他方法说明如下:
检测字符串是否为小写、大写或者首字母大写格式:
| 方法名 | 功能 |
|---|---|
| islower() | 检测字符串是否为纯小写的格式。例如:“python”.islower()、“PYTHON”.islower() |
| isupper() | 检测字符串是否为纯大写的格式。 |
| istitle() | 检测字符串是否为标题化的格式。 |
示例代码如下:
str1 = "PYTHON"
str2 = "python"
print(str1.islower()) # False
print(str2.islower()) # True
print(str1.isupper()) # True
print(str2.isupper()) # False
print("Python".isupper()) # False
str3 = "i love python" # 定义字符串
str4 = str3.title()
print(str3.istitle()) # False
print(str4.istitle()) # True
拓展:Python 没有提供 iscapitalize() 方法,用来检测字符串首字母是否为大写格式。下面自定义 iscapitalize() 函数来完善字符串大小写格式。
# 检测函数 与capitalize()对应
def iscapitalize(s):
if len(s.strip()) > 0 and not s.isdigit(): # 非空或非数字字符串,则进一步检测
# 使用 capitalize()把字符串转换为首字母大写形式,然后比较,如果相等,则返回True,否则返回False
return s == s.capitalize()
else:
return False # 如果为空,或者数字,则直接返回False
print(iscapitalize("Python")) # True
print(iscapitalize(" ")) # False
print(iscapitalize("123")) # False
print(iscapitalize("python")) # False
print(iscapitalize("I Love Python")) # False
print(iscapitalize("Python 3.8.6")) # True
数字和字母检测
| 方法名 | 功能 |
|---|---|
| isdigit() | 如果字符串只包含数字,则返回 True;否则返回 False。 |
| isdecimal() | 如果字符串只包含十进制数字,则返回 True;否则返回 False。 |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True;否则返回 False。 |
| isalpha() | 如果字符串中至少有一个字符,并且所有字符都是字母,则返回 True;否则返回 False。 |
| isalnum() | 如果字符串中至少有一个字符,并且所有字符都是字母或者数字,则返回 True;否则返回 False。 |
示例代码如下:
n1 = "1" # Unicode数字
print(n1.isdigit()) # True
print(n1.isdecimal()) # True
print(n1.isnumeric()) # True
n2 = "1" # 全角数字(双字节)
print(n2.isdigit()) # True
print(n2.isdecimal()) # True
print(n2.isnumeric()) # True
n3 = b"1" # byte数字(单字节)
print(n3.isdigit()) # True
# print(n3.isdecimal()) # 报错:AttributeError: 'bytes' object has no attribute 'isdecimal'
# print(n3.isnumeric()) # 报错:AttributeError: 'bytes' object has no attribute 'isnumeric'
n4 = "IV" # 罗马数字
print(n4.isdigit()) # False
print(n4.isdecimal()) # False
print(n4.isnumeric()) # False
n5 = "四" # 汉字数字
print(n5.isdigit()) # False
print(n5.isdecimal()) # False
print(n5.isnumeric()) # True
特殊字符检测
特殊字符包括空白(空格、制表符、换行符)、可打印字符(制表符、换行符不是,而空格是),以及是否满足标识符定义规则。具体说明如下:
| 方法名 | 功能 |
|---|---|
| isspace() | 如果字符串中只包含空白,则返回 True;否则返回 False。 |
| isprintable() | 如果字符串中的所有字符都是可打印的字符,或者字符串为空,则返回 True;否则返回 False。 可打印字符(制表符、换行符不是,而空格是)。 |
| isidentifier() | 如果字符串是有效的 Python 标识符,则返回 True;否则返回 False。 |
示例代码如下:

3. 课后练习
3.1 说出下面切片截取字符串的结果
str1 = "0123456789"
print(str1[0:3])
print(str1[:])
print(str1[6:])
print(str1[:-3])
print(str1[2])
print(str1[-1])
print(str1[::-1])
print(str1[-3:-1])
print(str1[-3:])
print(str1[:-5:-3])
3.2 案例:模拟上传图片文件
通常在上传文件的时候对文件的格式有要求,如上传图片的文件时,格式可以为 .png/.jpg/.gif 等,只有符合该格式的文件才可以上传,通过对字符串操作,模拟上传图片文件,演示效果如下图所示:
