0. 前言
-
一句话总结:HVU通过更全面的标签(scene/environment, objects, actions, events, attributes, concepts)来描述视频信息。
-
这个数据集的名字直译是“全面的视频理解数据集”,意思就是探索视频理解领域能有哪些应用,不是单一任务的数据集。
-
官方资料:官网,论文(ECCV 2020),补充材料,Github
-
获取(数据有500+G):
-
之前数据集存在的问题:
- 视频相关数据集主要句现在人类行为或体育赛事上,这些其实只是视频相关任务中一个非常具体的问题。
- 其实,视频理解包含了很多方面的识别,比如场景/环境(a scene or an environment)、objects(物体)、actions(行为)、events(事件)、attributes(属性)、concepts(概念)。我们现在一般只关注行为。
- attribute类似于形容词、副词,形容其他scenes/actions/objects/events
- concept我也不知道该怎么翻译,
The concept category refers to any noun and label which present a grouping definition or related higher level in the taxonomy tree for labels of other categories.
1. 概况
- 论文中对数据集的描述:这句话我也翻译不好,还是看原文吧,关键字就是(hierarchically、 multi-label、multi-task)
HVU is organized hierarchically in a semantic taxonomy that focuses on multi-label and multi-task video understanding as a comprehensive problem that encompasses the recognition of multiple semantic aspects in the dynamic scene
- 主要关注三个任务
- 视频分类(Video classification)
- 视频描述(Video Captioning)
- 视频聚类(Video Clustering)
- 数据量:
- 视频数量:训练集/验证集/测试集分别有476k/31k/65k样本,共572k视频
- 标签:训练集、验证集、测试集分别有7.5M/600k/1.3M标签。
- 类别数量:共3142类,平均一类有2112个标注数据。细分分类:248 categories for scenes, 1678 for objects, 739 for actions, 69 for events, 117 for attributes and 291 for concepts。
- 这些类别太多了,放在文中不太合适,github上可以直接看到,参考这里
- 不同类样本之间的关系如下图与下表
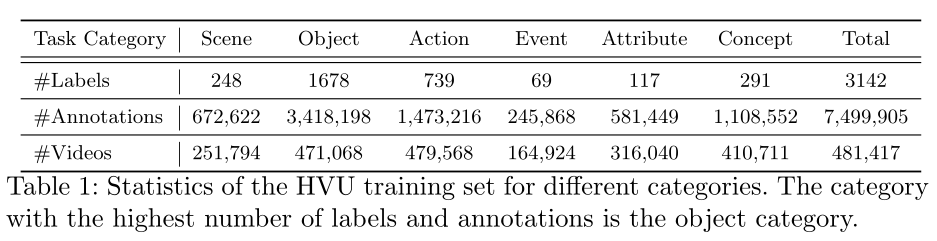
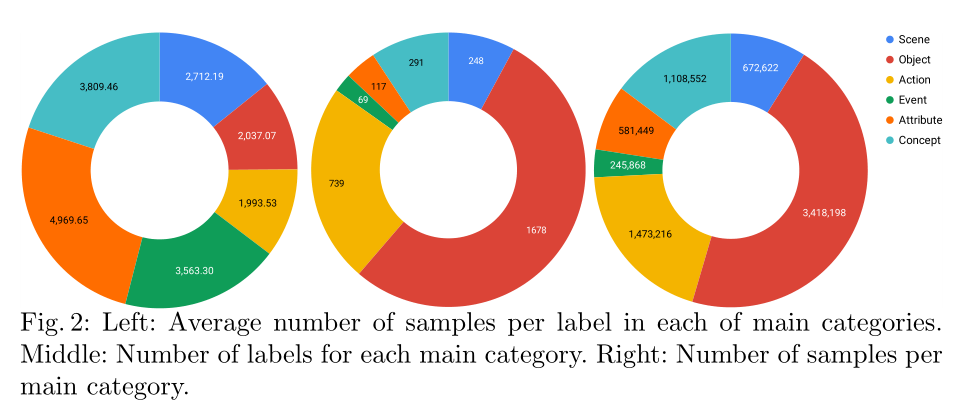
- 与其他常见视频理解数据集的对比
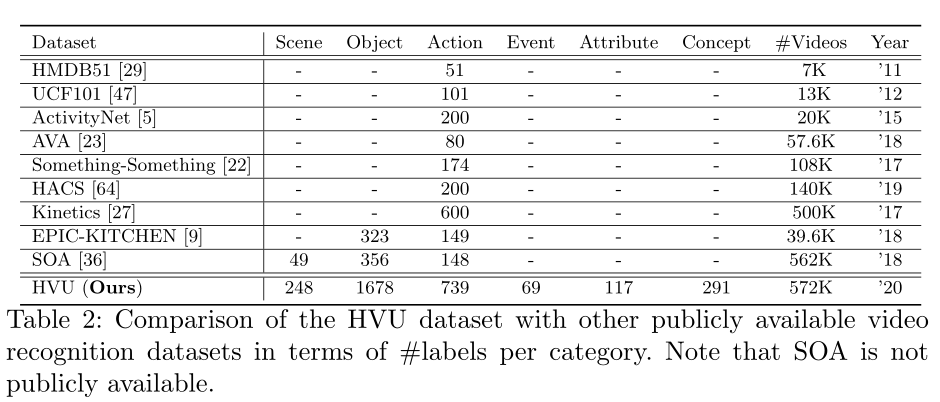
2. 详解
-
标签文件介绍
HVU_Tags_Categories_V1.0.csv:类别文件,分为两列(Tag和Category),前者表示具体类别名称,后者六选一 action/attributes/concept/event/object/scene。- 标签所在文件:
HVU_Train_V1.0.csv和HVU_Val_V1.0.csv- 一共有四列,分别是
Tags, youtube_id, time_start, time_end - 四列分别是标签(多个标签,每个标签之间通过
|分割),样本编号(即从youtube上下载时的youtube id)、起始时间( 应该是原始样本中的时间起点,即切割前的视频)、与截止时间(应该是原始样本中的时间点,即切割前的视频)。
- 一共有四列,分别是
-
数据采集以及标注过程
- 一般视频数据集构建分为两个步骤,数据采集以及数据标注。
- HVU的数据采集:主要使用已有的行为识别数据集作为数据源,例如YouTube-8M、Kinetics-600、HACS
- 使用已有数据集有很多好处,第一是不用考虑版权与隐私问题,第二是测试集与训练集不会重复。
- HVU的数据标注
- 行为识别数据集标注主要有两个问题,一是手工标注容易出错,毕竟标签多、标注者也很难关注到所有细节,二是标注费时费力。
- 为了缓解上面的问题,HVU先使用了Google Vision API以及Video Tagging API进行标注,每个视频30个tags,再进行人工验证。
- 论文中有补充材料,介绍了人工标注细节(Human Annotation Details)
-
Taxonomy:直译是“分类法”,总而言之,就是类别如何来的。
- 使用了Google以及Sensifai的API,所有获取的tags有大约8000个。
- 去除样本不均衡的标签(我也不知道啥意思,大概是样本很少的那些标签?)