1 List
数据结构

在版本3.2之前,Redis 列表list使用两种数据结构作为底层实现:
- 压缩列表ziplist
- 双向链表linkedlist
因为双向链表占用的内存比压缩列表要多, 所以当创建新的列表键时, 列表会优先考虑使用压缩列表, 并且在有需要的时候, 才从压缩列表实现转换到双向链表实现。 - 压缩列表转化成双向链表条件
-
创建新列表时 redis 默认使用 redis_encoding_ziplist 编码, 当以下任意一个条件被满足时, 列表会被转换成 redis_encoding_linkedlist 编码:
试图往列表新添加一个字符串值,且这个字符串的长度超过 server.list_max_ziplist_value (默认值为 64 )。
- ziplist 包含的节点超过 server.list_max_ziplist_entries (默认值为 512 )。
注意:这两个条件是可以修改的,在 redis.conf 中:
list-max-ziplist-value 64
list-max-ziplist-entries 512
命令使用可以查看帮忙,help @list

1.1 栈
可以用list实现栈的功能,同向命名,左边push,左边弹出;

或者右边push,右边弹出

1.2 队列
可以用list实现队列,反向命令,左边push,右边弹出

或者 右边push,左边弹出

1.3 数组

1.4 阻塞队列fifo
lpush + brpop

Rpush + blpop

2 hash
hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
2.1 简单命令使用,使用查看帮忙 ,help @hash


Hset
Hget

Hmset hmget hgetall

Hkeys hvals hlen

Hincrby hincrbyfloat 对数值操作

3 Set
在Redis中,Set类型是没有排序的字符集合,和List类型一样,可以在该类型的数据值上执行添加、删除或判断某一元素是否存在等操作。需要说明的是,这些操作的时间复杂度为O(1),即常量时间内完成次操作。Set可包含的最大元素数量是4294967295。和List类型不同的是,Set集合中不允许出现重复的元素。换句话说,如果多次添加相同元素,Set中将仅保留该元素的一份拷贝。和List类型相比,Set类型在功能上还存在着一个非常重要的特性,即在服务器端完成多个Sets之间的聚合计算操作,如unions、intersections和differences。由于这些操作均在服务端完成,因此效率极高,而且也节省了大量的网络IO开销。
3.1 基本操作
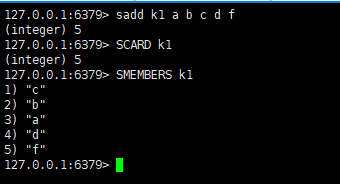
Sadd 添加一个元素到集合中(集合中的元素无序的并且唯一)
Scard 返回集合元素的数量
Smembers 查看集合中所有的元素

SRandMember
如果不填写返回个数,默认是1,如果填写的数字大于集合的size,那么返回集合的所有元素
如果填写的是负数,如果绝对值大于集合的size,那么返回值里会出现一个元素多次出现的情况。
如果key不存在,则返回nil

其他简单命令这里不一一例举。
3.2 聚合计算
SUNION:并集

SUNIONSTORE:求并集后存到一个新的集合(如果结果集存入到已有的集合,那么会覆盖以后的数据集合)

交集:
sinter/sinterstore

sdiff/sdiffstore差集
sdiff [set1] [set2]
功能:删除set1中在set2里也存在的元素,返回删除操作后的set1
sdiffstore [set1] [set2] [set3]
功能:将sdiff [set2] [set3] 的结果保存在set1中

3.3 随机事件,应用场景
sRandMember,sPop
这两个命令功能非常相似,都是从集合中返回一个元素值。不同的是,sRandMember不会从集合中删除返回的元素,但是sPop会删除。这两个命令可以分别实现不同的抽奖算法。

比如,集合中有100个元素,值从数字1到数字100.我们定义抽到的是数字1的话,即表示中奖。
使用sRandMember的话,不管之前抽过多少次,下次抽中的概率都是1%。而使用sPop的话,则每次抽中的概率都不一样。第一个人抽中概率是1%,当第一个人没抽中的话,第二个人抽中概率就是1/99,以此类推。
分两种情况
1 奖品数量多余抽奖人数,比如10件奖品,3个人
Sadd k1 tom baby xx

2 奖品数量少于抽奖人数,并且不可重复中奖,适用于一般公司年后
Sadd k1 tom baby xx
把所有人的名字放入set,每次取出一个,并且删除,保准公平性。

4 sorted set
Sorted Set有点像Set和Hash的结合体。
和Set一样,它里面的元素是唯一的,类型是String,所以它可以理解为就是一个Set。
但是Set里面的元素是无序的,而Sorted Set里面的元素都带有一个浮点值,叫做分数(score),所以这一点和Hash有点像,因为每个元素都映射到了一个值。
Sorted Set是有序的,规则如下:
如果A.score > B.score,那么A > B。
如果A.score == B.score,那么A和B的大小就通过比较字符串来决定了,而A和B的字符串是不会相等的,因为Sorted Set里面的值都是唯一的。
4.1 基本命令操作
ZADD
ZADD可以添加元素到Sorted Set,就和Set的SADD命令差不多
ZRANGE,ZREVRANGE
ZRANGE默认按分数由低到高把Sorted Set的元素显示出来
想按分数要从高到低显示,需要使用ZREVRANGE
也可以一同把分数显示出来,使用参数WITHSCORES


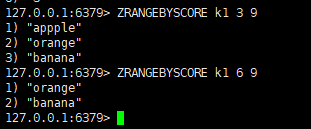
ZRANGEBYSCORE可以按范围显示Sorted Set,格式是zrangebyscore key 分数下限 分数上限
ZRANK,ZREVRANK
ZRANK命令可以获得元素的排名, ZREVRANK 反之
4.2 集合操作
这里不一一例举了
4.3 排序实现原理
skip List是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)(大多数情况下),因为其性能匹敌红黑树且实现较为简单,因此在很多著名项目都用跳表来代替红黑树,例如LevelDB、Reddis的底层存储结构就是用的SkipList。
目前常用的key-value数据结构有三种:Hash表、红黑树、SkipList,它们各自有着不同的优缺点:
Hash表:插入、查找最快,为O(1);如使用链表实现则可实现无锁;数据有序化需要显式的排序操作。
红黑树:插入、查找为O(logn),但常数项较小;无锁实现的复杂性很高,一般需要加锁;数据天然有序。
SkipList:插入、查找为O(logn),但常数项比红黑树要大;底层结构为链表,可无锁实现;数据天然有序。
一个跳表,应该具有以下特征:
1、一个跳表应该有几个层(level)组成;
通常是10-20层,leveldb中默认为12层。
2、跳表的第0层包含所有的元素;
且节点值是有序的。
3、每一层都是一个有序的链表;
层数越高应越稀疏,这样在高层次中能'跳过’许多的不符合条件的数据。
4、如果元素x出现在第i层,则所有比i小的层都包含x;
5、每个节点包含key及其对应的value和一个指向该节点第n层的下个节点的指针数组
x->next[level]表示第level层的x的下一个节点
skiplist的查询过程
查询的第一个比vx大的节点的前一个值,看是否相等。相等则存在,否则查找下一层,直到层数为0。
以已有数据13、22、75、80、99为例

从最高层(此处为2)开始
1、level2找到结点Node75小于80,且level2.Node75->next 大于80,则进入level1查找(此处已经跳过了13~75中间的结点(22),
2、level1.Node75 < 80 < level1.Node75->next,进入level0
3、level0.Node75->next 等于80,找到结点
skiplist的插入过程
假设插入一新键值key,值为84,level为当前层

1、从最高层开始找到每一层比84大的节点的前一个值,存入prev[level]。
prev[2] = leve2.Node75
prev[1] = leve1.Node75
prev[0] = level0.Node80
2、初始化一个新的节点84
3、为x随机选择一个高度h,这里选2
4、x->next[0..h-1] = prev[0..h-1]->next
5、prev[0..h-1]->next[0..h-1] = x
(步骤4、5为链表插入结点的操作)
skiplist删除操作
删除操作类似于插入操作,包含如下3步:1、查找到需要删除的结点 2、删除结点 3、调整指针