KMP算法
引言
\quad \quad 上一篇讲了BF算法,但是其时间性能比较低?
- 在每趟匹配不成功时存在大量回溯,没有很好的利用部分匹配成功的结果。比如,匹配不成功时,主串必须回溯到下一个字符,模式串回溯到0,开始一一重新匹配。
- 那有没有可能主串不回溯,模式串移动呢?
- 就有了KMP算法
1、概述
\quad \quad KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。
改进思想:
- 利用已经部分匹配的结果加快模式串的滑动速度且主串S的指针i不必回溯!可提速到O(n+m)!
- 模式串T向右滑动到的新比较起点K仅与模式串T有关。
2、基本思想
- 见此文
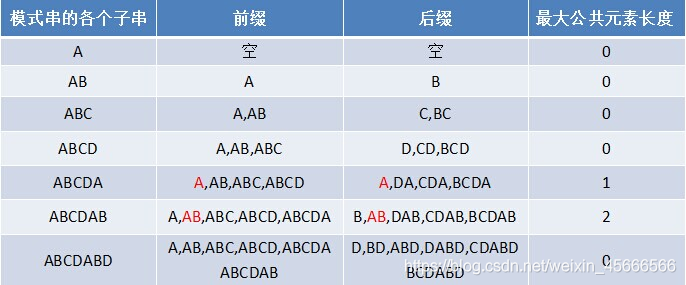
- 基本概念
最长前缀后缀(Longest Prefix Suffix)即 最长相等前后缀长度
3、KMP算法——next数组
1、作用:定义next[j]函数,表明当模式中第j个字符与主串中相应字符“失配”时,在模式中需重新和主串中该字符进行比较的字符的位置。
2、计算next[j]的方法 :
\quad \quad next数组的数值只与模式串本身有关。
- 当j=0时,next[j]=-1,表示不进行字符比较
- 当j>0时,next[j]的值为:模式串的位置从0到j-1构成的子串中所出现的首尾相同的字串的最大长度即最长相等前后缀长度。
- 当无首尾相同的子串时next[j]的值为0,表示从模式串头部开始进行字符比较。

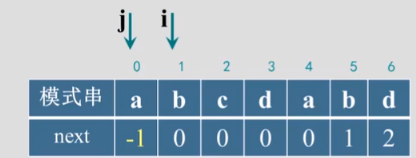
- 例子:模式串p= "abcabcmn"的next数组为next[0]=-1(前面没有字符串单独处理),next[1]=0;next[2]=0;next[3]=0;next[4]=1;next[5]=2;next[6]=3;next[7]=0。

3、伪代码
- 假设我们从左到右依次计算next数组,在某一时刻,已经得到了next[0]~next[i],现在要计算next[i+1],设j=next[i],由于知道了next[i],所以我们知道T[0,j-1]=T[i-j,i-1],现在比较T[j]和T[i],如果相等,由next数组的定义,可以直接得出next[i+1]=j+1。
- 具体做法如下:
1、初始化前缀指针j=-1,后缀指针i=0,next=[-1]*m,其中m为模式串的长度
2、当后缀指针i<模式串的长度,执行以下循环:
- 2.1 当j==-1或者T[i]==T[j]:指针i,j均向后移动一位,next[i]=j
- 2.2 否则,j=next[j]
4、python实现
def gen_next(T):
j=-1 #前缀指针
i=0 #后缀指针
m=len(T)
next=[-1]*m
#i表示p中的第几个元素,j表示当前元素前面子串中最长公共前缀长度后的字符索引
while i <m-1:
if j==-1 or T[i]==T[j]:
j+=1
i+=1
next[i]=j
else:
j=next[j]
return next
if __name__=="__main__":
s="abcdabd"
b=gen_next(s)
print(b)

4、KMP算法
- 当模式串中的某个字符跟文本串中的某个字符匹配失配时,模式串下一步应该跳到哪个位置。如模式串中在j 处的字符跟文本串在i 处的字符匹配失配时,下一步用next [j] 处的字符继续跟文本串i 处的字符匹配,相当于模式串向右移动 j - next[j] 位。
- KMP算法与BF算法的不同之处在于i,j的回溯之处。
1、伪代码
1、在主串S和模式串T中初始下标i=0和j=0
2、计算模式串T的next数组
3、循环直到S或T的所有字符均未比较完:
- 3.1 如果S[i]==T[j],继续比较S和T的下一个字符
- 3.2 否则,将j向右滑动到next[j]位置,即j=next[j]
- 3.3 如果j=-1,则将i和j分别加一,准备下一趟比较
4、如果T中所有字符均比较完,则匹配成功,返回匹配的起始下标;否则匹配失败,返回-1。
2、python实现
def gen_next(T):
j=-1 #前缀指针
i=0 #后缀指针
m=len(T)
next=[-1]*m
#i表示p中的第几个元素,j表示当前元素前面子串中最长公共前缀长度后的字符索引
while i <m-1:
if j==-1 or T[i]==T[j]:
j+=1
i+=1
next[i]=j
else:
j=next[j]
return next
def matching_KMP(S,T):
"""KMP串匹配,主函数"""
i,j=0,0
next=gen_next(T)
n,m=len(S),len(T)
while i<n and j<m:
if j==-1 or S[i]==T[j]:
i,j=i+1,j+1
else:
j=next[j]
if j==m:
return i-j
else:
return -1
if __name__=="__main__":
s="abcabaabcabac"
t="baab"
b=matching_KMP(s,t)
print(b)
- 时间复杂度: O ( n + m ) O(n+m) O(n+m)
- 时间复杂度: O ( m ) O(m) O(m)
5、KMP算法的改进
—nextval数组
KMP算法可改进之处,下面以一个例子说明:
- 主串s=“aaaaabaaaaac”
- 子串t=“aaaaac”
- 这个例子中当‘b’与‘c’不匹配时应该‘b’与’c’前一位的‘a’比,这显然是不匹配的。'c’前的’a’回溯后的字符依然是‘a’。
- 可想而知没有必要再将‘b’与‘a’比对了
- 因为回溯后的字符和原字符是相同的,原字符不匹配,回溯后的字符自然不可能匹配。但是KMP算法中依然会将‘b’与回溯到的‘a’进行比对。这就是我们可以改进的地方了。
- 我们改进后的next数组命名为:nextval数组。KMP算法的改进可以简述为: 如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next值。 这应该是最浅显的解释了。如字符串"ababaaab"的next数组以及nextval数组分别为:

1、nextval数组python实现
def next_val(T):
j=-1 #前缀指针
i=0 #后缀指针
m=len(T)
next_val=[-1]*m
#i表示p中的第几个元素,j表示当前元素前面子串中最长公共前缀长度后的字符索引
while i <m-1:
if j==-1 or T[i]==T[j]:
j+=1
i+=1
if T[i]!=T[j]:
next_val[i]=j
else:
next_val[i]=next_val[j]
else:
j=next_val[j]
return next_val
if __name__=="__main__":
t="ababaaab"
b=next_val(t)
print(b)
# 结果:[-1, 0, -1, 0, -1, 3, 1, 0]
2、KMP改进算法实现
- 只不过就是把之前的next数组换为next_val
def next_val(T):
j=-1 #前缀指针
i=0 #后缀指针
m=len(T)
next_val=[-1]*m
#i表示p中的第几个元素,j表示当前元素前面子串中最长公共前缀长度后的字符索引
while i <m-1:
if j==-1 or T[i]==T[j]:
j+=1
i+=1
if T[i]!=T[j]:
next_val[i]=j
else:
next_val[i]=next_val[j]
else:
j=next_val[j]
return next_val
def matching_KMP(S,T):
"""KMP串匹配,主函数"""
i,j=0,0
next=next_val(T)
n,m=len(S),len(T)
while i<n and j<m:
if j==-1 or S[i]==T[j]:
i,j=i+1,j+1
else:
j=next[j]
if j==m:
return i-j
else:
return -1
if __name__=="__main__":
s="abcabaabcabac"
t="baab"
b=matching_KMP(s,t)
print(b)