语义分割(FCN,UNET,DEEPLAB)
语义分割的目的是对图像中的每一个像素点进行分类,从而确定每个像素点所属的类别。(从像素级别进行分类)
1.FCN(Fully Convolustional Networks)
VGG和Resnet等CNN网络通过在网络最后加入全连接层,然后再经过softmax获得类别的概率信息,得到的一维概率信息可以对整张图片的类别进行识别。FCN提出将网络后边的全连接层全部换成卷积,从而得到二维的特征图(feature map),使用反卷积层对特征图进行上采样,恢复到与图像相同的尺寸,从而对每一个像素均产生一个预测结果,进而解决分割问题(FCN是在抽象的特征图中恢复每个像素的类别)。
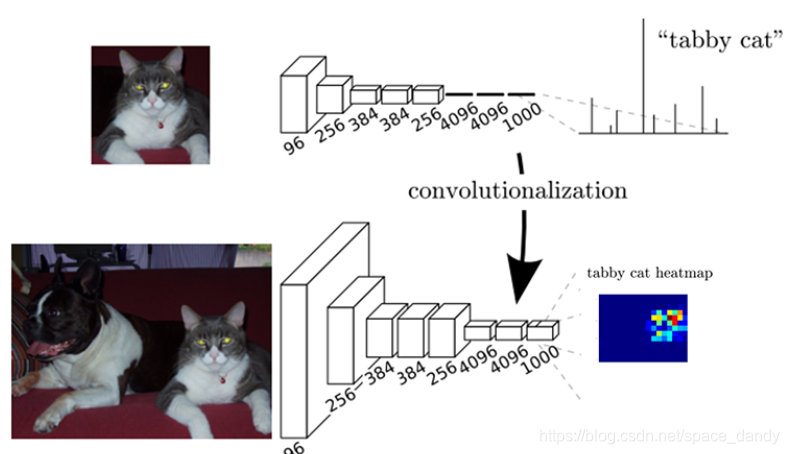
FCN的结构和操作流程如下:
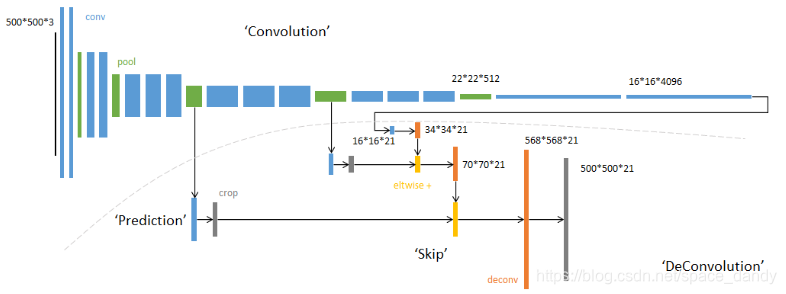
- 首先使用全卷积提取特征(虚线以上部分),图中的蓝色快为卷积块,绿色块为max pooling块。输入可以为任意尺寸的彩色图像,输出图像的尺寸与输入尺寸相同。
- 然后分别从卷积网络的不同阶段预测分类结果(虚线以下部分),原始图片经过多层卷积与池化操作后,得到的图像越来越下,分别率越来越低,图像最小时被称为Heatmap热图(即特征图)。使用反卷积操作对特征图进行上采样,直到恢复到与输入图像相同的尺寸,从而对每个像素产生预测。假设输入图像大小为nnc,类别数为C,那么恢复的图像大小为nnC,通过逐个像素地求其在C张图像的该像素的最大数值描述(概率)作为该像素的分类。也就说最后恢复的图像已经被分类完成。
关于上采样操作
上采样操作包括resize和反卷积两种。
resize主要通过双线性插值直接实现。
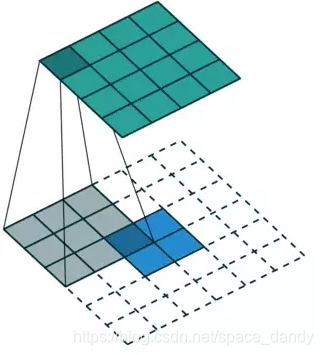
反卷积操作的原理与卷积原理类似,相当于把普通卷积反过来。如下图,卷积操作是利用33卷积核将44的原始输入卷积为22的特征图;反卷积是将22特征图恢复为4*4原始大小。相当于一个Encode-Decode过程。
关于跳级结构
(如网络结构图中虚线的下半部分)。使用逐数据相加的方法融合三个不同深度的预测结果:较浅的结果更为精细,较深的结果更为鲁棒。
2. Unet
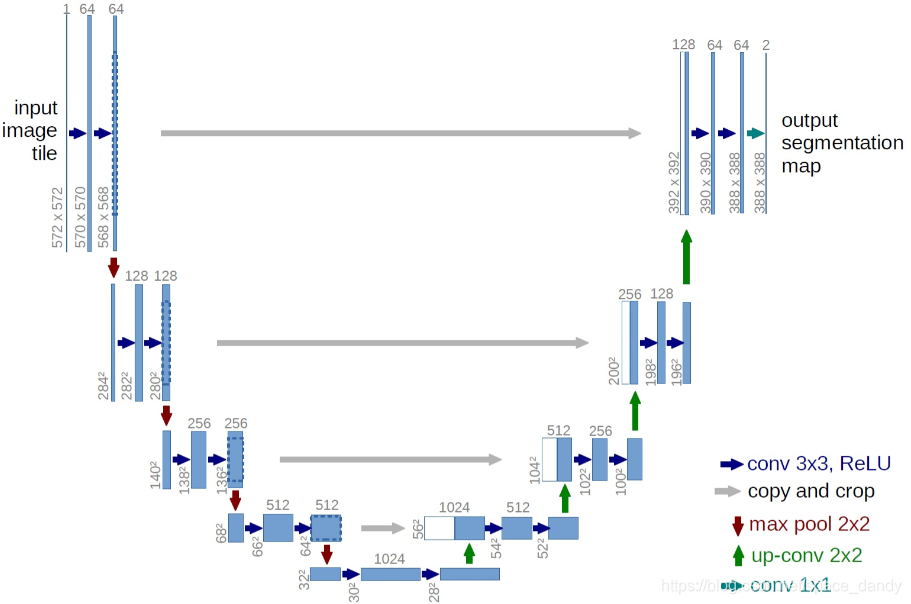
Unet结构如上图所示,形状类似于字母U。整体结构就是先下采样,再上采样,回归到与输入图像一样大小。具体为:
- 左半部分为编码Encoder部分,由两个33卷积层(Relu)和22的max pooling层(stirde=2)反复组成
- 右半部分为解码Decoder部分,由一个22的上采样卷积层和Concatenation(Crop对应的Encoder层输出的feature map与Decoder层的上采样结果相加)+2个33卷积层反复构成
- 最后一层通过1*1卷积将通道数变成期望的类别数
Unet共进行了4次上采样,并在同一个stage使用了skip connection,不是直接在高级语义特征上进行监督和loss反转,保证了最后回复的特征图融合了更多的low-level特征
Unet使用了与FCN不同的特征融合方式:FCN为特征对应点相加;Unet将特征在Channel维度上拼接在一起,形成了更厚的特征。
3.Deeplab
Deeplabv1
Deeplab结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法。由于DCNNs高级特征的平移不变形,DCNNs在语义分割任务中存在精准度不够的问题。Deeplab将DCNNs的响应和完全连接的条件随机场结合,并创新性地将空洞卷积应用到DCNN模型上。
DCNN在图像标记任务上存在两个技术障碍:一是信号下采样,DCNN中的重复最大池化和下采样带来分辨率下降,导致细节的丢失,Deeplab采用了空洞卷积扩展了感受野,从而获得更多的上下文信息;二是空间不敏感,分类器获取以对象为中心的决策需要空间变换的不变性,限制了DCNN的定位精度,Deeplab使用DenseCRF提高模型捕获细节的能力。
空洞卷积
传统CNN通过卷积和pooling,在降低图像尺寸的同时增大感受野(卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小)。但pooling操作缩小图像尺寸然后增加尺寸的过程中损失了一些信息,空洞卷积的提出使得可以不通过pooling操作来增大感受野

如上图所示,(a)为33普通卷积,(b)为33,空洞为1的卷积,仅有红点参与卷积操作,其余点略过;© 3*3,空洞为3的卷积。空洞卷积的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。
DenseCRF
卷积网络生成的结果尽可以表示粗糙的物体位置,无法很好的描述物体便捷,使用全连接的CRF可以很好的恢复物体边界。
对于每个像素i,其类别为xi,观测值为yi,将每个像素作为节点,像素与像素之间的关系作为边,额可以构成条件随机场,可以根据观测变量yi来推测i的类别标签xi。

CRF的能量函数为E(x),由医院势函数和二元势函数两部分组成

一元势函数表示观察到当前像素点为yi,其对应标签为xi的概率值

二元势函数用于刻画变量之间的相关关系以及其观测序列对其的影响

CRF属于一种后处理过程
Deeplabv2
与v1版本相比,空洞卷积方法进行了调整,提出了ASPP方法,将基础层由VGG16换成了ResNet
此处主要讲一些ASPP。ASPP(Atrous spatial pyramid pooling)根据何凯明提出的SPP思想产生,主要为了解决图像处理中的多尺度问题,金字塔思想。

Deeplabv3
v3版本主要对v2中的ASPP进行了改进,废除了CRF后也得到了较好的结果。

如上图,增加了并行空洞卷积,在同一层block使用不同的空洞卷积,实现多尺度。
Reference
[1]https://blog.csdn.net/xxiaozr/article/details/74159614
[2]https://blog.csdn.net/qq_36269513/article/details/80420363
[3]https://zhuanlan.zhihu.com/p/31428783
[4]https://zhuanlan.zhihu.com/p/90418337
[5]http://hellodfan.com/2018/01/22/%E8%AF%AD%E4%B9%89%E5%88%86%E5%89%B2%E8%AE%BA%E6%96%87-DeepLab%E7%B3%BB%E5%88%97/