https://blog.csdn.net/qq_43701760/article/details/93749006
安装环境:
centos7:
jdk:1.8
mysql:5.7
| IP地址 | 从属 | 安装服务 |
|---|---|---|
| 192.168.248.100 | 主 | server 、agent 、jdk 、MySQL |
| 192.168.248.101 | 从 | agent、jdk |
| 192.168.248.102 | 从 | agent、jdk |
| 192.168.248.104 | 从 | agent、jdk |
| 192.168.248.17 | yum源 | jdk 、cm和cdh离线安装包、httpd |
安装clouder manager的前置工作(非常重要)
*****说明:第一步到第六步现在一台机器上操作就可以,然后克隆机器即可
第一步:关闭防火墙
关闭防护墙
systemctl stop firewalld.service
禁止开机启动
systemctl disable firewalld.service
第二步:关闭selinux
```javascript
修改/etc/selinux/config文件中的selinux=disabled(重新启动后生效)
第三步:安装jdk(注意安装目录一定是/usr/java/下
从cloudermanager的官网上下载jdk的安装包oracle-j2sdk1.8.rpm
把jdk的安装包上传到集群上
yum install oracle-j2sdk1.8.rpm
第四步:安装前置包 ,也是执行shell脚本(pre_package.sh)
#!/usr/bin/bash
#这个脚本主要用来初始化新节点,需要完成以下工作
#1. 磁盘格式化,挂载,以及相关RPM包的安装,参数的设置
#2. 安装python3.6.8
#3. mysql jdbc 包放到/usr/share/java目录
#4. python3.6.8的包需要访问/root目录下
#5. 需要开通MySQL白名单
#6. 需要拷贝其他节点的用户
#hostname=$1
#hostnamectl set-hostname ${
hostname}
#echo "HOSTNAME=${hostname}" >> /etc/sysconfig/network
## mount disk ######
#mkfs.ext4 /dev/vdb
#echo "/dev/vdb /data01 ext4 noatime,defaults 0 0" >> /etc/fstab
#mkdir /data01
#mkfs.ext4 /dev/vdc
#echo "/dev/vdc /data02 ext4 noatime,defaults 0 0" >> /etc/fstab
#mkdir /data02
#mount -a
########
## add config #####
echo "* soft nproc 10240" >> /etc/security/limits.conf
echo "* hard nproc 16384" >> /etc/security/limits.conf
echo "* soft stack 10240" >> /etc/security/limits.conf
echo "* - memlock unlimited" >> /etc/security/limits.conf
echo "vm.swappiness = 0" >> /etc/sysctl.conf
echo "fs.file-max = 800000" >> /etc/sysctl.conf
echo "net.core.somaxconn=32768" >> /etc/sysctl.conf
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
###### uninstall supervisor(this package will confilct with Cloudera agent #########
rpm -e --nodeps supervisor-3.1.4-1.el7.noarch
#### install lzo #################
yum install -u lzo*
#### install perl #################
yum install -y perl*
wget http://www.cpan.org/src/5.0/perl-5.16.1.tar.gz
tar -zxvf perl-5.16.1.tar.gz
cd perl-5.16.1
./Configure -des -Dprefix=/usr/local/perl
make && make install
### install pyycopg2 for python ##########
yum install -y bzip2-devel zlib zlib-devel openssl openssl-devel libffi-devel python-devel
yum install -y gcc "development tools" ncurses-devel sqlite-devel readline-devel
yum install -y tk-devel gdbm-devel db4-devel libpcap-devel xz-devel expat-devel postgresql-devel
pip install psycopg2
### start nscd service #####
systemctl start nscd
### install rngd #############
yum install -y rng-tools
cp /usr/lib/systemd/system/rngd.service /etc/systemd/system/
sed -i -e 's/ExecStart=\/sbin\/rngd -f/ExecStart=\/sbin\/rngd -f -r \/dev\/urandom/' /etc/systemd/system/rngd.service
systemctl daemon-reload
systemctl start rngd
systemctl enable rngd
##### install kerberos client#############
yum install krb5-libs krb5-workstation -y
##### install python3.6.8 ###############
#cd /root/Python-3.6.8
#./configure
#make&&make install
#### pip3 module setup ##############
#pip3 install py4j==0.10.8.1 && pip3 install elasticsearch==7.0.2 && pip3 install numpy==1.15.4 && pip3 install pandas==0.24.2 && pip3 install scikit-learn==0.19.1 && pip3 install scrapy==1.0.0 && pip3 install scipy==1.0.0
#### mkdir /usr/share/java ###########
#mkdir /usr/share/java
#cp /root/mysql-connector-java.jar /usr/share/java
#cp /root/ojdbc6.jar /usr/share/java
第五步:修改主机名称,禁用ipv6
修改/etc/sysconfig/network文件:(CDH 要求使用 IPv4,IPv6 不支持)
NETWORKING=yes
HOSTNAME=cdh1
NETWORKING_IPV6=no
IPV6INIT=no
第六步:修改主机名和IP地址的映射关系
修改/etc/hosts文件
192.168.248.100 cdh1
192.168.248.101 cdh2
192.168.248.102 cdh3
192.168.248.104 cdh4
192.168.248.17 hdfs4
其中HOSTNAME与主机名一致(看第五步的主机名)
第七步:安装免密登录
命令:ssh-keygen -t rsa
然后一直回车即可
[root@hadoop1 etc]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
78:49:9b:18:94:3f:71:1e:d9:0e:27:49:92:d8:e2:e7 root@hadoop1
The key's randomart image is:
+--[ RSA 2048]----+
| .+.o.+ |
| .+ +.B o |
| ..o.+ * |
| .=++. . |
| ooS. |
| .E |
| |
| |
| |
+-----------------+
把密钥拷贝到其它的机器上
ssh-copy-id root@cdh2
然后输入yes,再输入你机器的密码即可配置成功
The authenticity of host 'cdh2 (192.168.234.101)' can't be established.
ECDSA key fingerprint is ca:4e:1e:9b:bf:dd:40:b3:51:21:41:e6:09:c4:7f:4e.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@cdh2'"
and check to make sure that only the key(s) you wanted were added.
测试,在cdh1上,直接登录cdh2
ssh cdh2
第八步:在主节点上(248.100)安装MySQL
可以参考我写的MySQL离线安装教程,后续改成shell脚本自动安装的方式
https://blog.csdn.net/qq_38220334/article/details/104891684
第九步:在主节点上上传MySQL的驱动jar包
注意:1.驱动jar包的位置一定是这个路径下/usr/share/java
2.驱动jar包的名字一定是mysql-connector-java.jar,如果不是修改一下名字即可,实际安装的时候遇到的问题是:名字不是这个,启动cloudermanager的时候,在 /var/log/cloudera-scm-server/cloudera-scm-server.log路径下看不到日志输出
第十步:配置yum源,在248.17机器上(这台机器的作用就是yum源,不做其他的用处)
安装httpd服务
yum install httpd
启动httpd
service httpd restart
设置为开机自启动
systemctl enable httpd.service
怎么知道httpd是否安装成功了
1.ps -ef|grep httpd
2.在/var/www/html路径下自己新建一个html页面,然后用你的IP地址加html名称访问浏览器即可
例如:192.168.248.14:wzx.html
在html下面新建cloudera-repo的文件夹,在创建两个子目录cdh6和cm6

进入cm6中,在官网上下载allkey.asc的文件和repodata和RPMS目录下的所有文件

repodata下的所有文件
 RPMS下的文件
RPMS下的文件

进入cdh6中
 注意:官网的文件下载地址可以参考这一个
注意:官网的文件下载地址可以参考这一个
https://archive.cloudera.com/cdh6/6.2.0/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel.sha1
大文件可以提前下载好,小文件可以采用下面的方式直接下载
wget https://archive.cloudera.com/cdh6/6.2.0/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373-el7.parcel.sha1
然后用IP地址加上这些目录可以如下访问即可,这样yum源就配置好了

然后把yum源配置到其他机器上
在/etc/yum.repos.d/下把文件cloudera-manager.repo上传上去
配置成如下,其实就是把cm6中的包引入到其他机器上,这个文件下载不方便的话,直接自己编辑一个就可以,内容就参考我这个就可以
[cloudera-manager]
name = Cloudera Manager, Version
baseurl = http://192.168.248.17/cloudera-repos/cm6/
gpgcheck = 0 #(1是检查,0是跳过检查,用0就可以)
如果是1的话,你的jdk会安装的不成功,显示jdk not installed
前置工作就可以了,接下来就是安装cloudera-manager了,server只在248.11上安装就可以了
yum install cloudera-manager-daemons cloudera-manager-agent cloudera-manager-server
安装成功后,首先初始化数据库
1.创建scm的数据库
create database scm;
#scm是你创建的数据库名称,root是你的用户
2.执行命令/opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm root
其实在这个目录下可以看到上面命令的执行结果
cd /etc/cloudera-scm-server/
启动:systemctl start cloudera-scm-server
注意:执行完启动命令时,当前的窗口是没有任何反应的,需要去看日志
tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log
安装CDH的前置工作:
地址就是你的IP地址加上默认的端口号7180,登录名称和密码都是admin

第二步:这个最好选择第二项,功能相对多些

这里填写你的集群的名称,根据公司名称结合业务最好

这里填写其他机器的IP地址,yum源的地址先不用写

点击搜索,显示下面的4台机器,但是目前还是不被管理的

点击这里,发现安装server的机器已经被管理了

这里选择自定义存储,把cm的地址写上

然后选择更多选项,填写parcel包的地址
把这些都删除即可,走我们本地的parcel包地址,在浏览器中输入这个地址,可以看到我么的http服务的目录情况
http://192.168.248.17/cloudera-repos/cdh6/6.2.0/parcel/

这是我本地parcel包的地址

配置到上面的parcel包中的地址中

然后在CDH版本下面把cdh的版本勾选上

填写root用户的密码

然后就是给其他四台机器安装agent,其实就是分发agent到其他的机器,第一台机器为什么这么快呢,原因就是第一台机器安装server的时候,其实已经安装了agent
 如下图所示,成功安装agent
如下图所示,成功安装agent

点击详细信息可以看到详细的安装目录
然后就是等待分发的时间了
 其实分发agent的时候,其实就是把yum源上的安装包分发到各个机器上的这个目录下
其实分发agent的时候,其实就是把yum源上的安装包分发到各个机器上的这个目录下
,可以看到yum源上的文件已经到其它机器上了

检查网络和主机

然后选择这个继续安装

跳转到下面的页面后不用做操作了,直接回主页面
http://192.168.248.100:7180/cmf/home

点击所有主机,显示成这样,OK了
下面的好多的图标都是问号,那是因为这些机器还没有添加到监控中

下面开始添加到监控中,添加cloudermanager service

选择一台好的机器添加这些服务

添加两个数据库用于存储监控信息

然后去数据库中创建这两个库
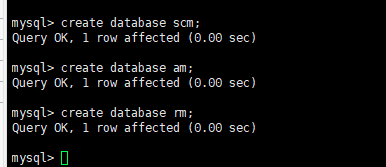
点击测试连接,显示成下面则测试通过

点击下一步:
 把图框中的路径改成自己的数据存储路径,空间大一些的,别用他默认的路径
把图框中的路径改成自己的数据存储路径,空间大一些的,别用他默认的路径

点击下一步,显示成如下,成功了

点击完成,显示下面,安装成功,原来的问号也变成绿色的勾了,非常nice
 –
–

注意:安装服务是有先后顺序的
1.ZK
2.HDFS
3.YARN
4.HIVE
5.IMPALA
6.OZ
7.HUE HUE依赖于OZ
然后就是开始添加服务了,安装是有先后顺序的,首先是安装zookeeper,安装zk应该是安装奇数个,它有投票选举机制,首先选择添加服务
 选择zookeeper,选择后三台机器安装
选择zookeeper,选择后三台机器安装
 同样的,这里也改成自己的目录结构,不用它默认的目录
同样的,这里也改成自己的目录结构,不用它默认的目录

安装HDFS,简单的步骤都省略掉了,所有的机器上都安装HDFS
 存储数据的目录都改成自己的目录
存储数据的目录都改成自己的目录
 安装,下图所示
安装,下图所示
 此时的HDFS是只有一个namenode,达不到高可用
此时的HDFS是只有一个namenode,达不到高可用

下面是配置高可用
 我的配置如下;JournalNode也是奇数个
我的配置如下;JournalNode也是奇数个

定义日志的目录,默认是没有目录的
 定义新的目录
定义新的目录
 开始配置,注意一下namenode的目录这块,高可用在集群已经有数据的情况下配置也是可以的,不会对源数据进行格式化
开始配置,注意一下namenode的目录这块,高可用在集群已经有数据的情况下配置也是可以的,不会对源数据进行格式化
 –
–
 配置完后,显示如下;
配置完后,显示如下;

hdfs的参数调整,这个参数调整为4G就可以了,点击配置,点击资源管理
 –修改namenode的值为
–修改namenode的值为
 保存时,报错如下;
保存时,报错如下;

原因:
集群配置
 –
–

安装yarn,有一个规则,namenode在哪里resourcemanager就安装在哪里,datanode在哪里nodemanager就安装在哪里
 –配置自己的数据目录
–配置自己的数据目录
 –
–

配置yarn的高可用
跟配置hdfs高可用类似,找一台机器当备用的即可

安装hive:
 –
–
测试连接MySQL报错
 –报错原因,没有把MySQL的jar包拷贝到相应的机器上
–报错原因,没有把MySQL的jar包拷贝到相应的机器上
把jar包拷贝到相应的机器上,发现测试连接可以了

 安装impala
安装impala
 –
–

配置多级目录查询
首先是配置yarn,点击配置,点击高级
mapreduce.input.fileinputformat.input.dir.recursive
true

修改hive的配置
hive.mapred.supports.subdirectories
true
 配置资源管理
配置资源管理

合并小文件,这这几项勾选上

安装OZ

– –
–
 –
–

安装hue
 –
–
 –
–

打开Session Stickly
invalid query handler
随便打开刚才配置的机器的一台IP地址+端口号8888,这里有一个地方注意一下,hdfs用户在hdfs上是最高级的用户,涉及到好多权限方面的东西,用户设置为hdfs好些,看个人
 非常nice,成功
非常nice,成功

安装hbase
安装如下,机器的分布如下图所示
 下一步
下一步
编制索引是和solr一起用的,先勾选上

安装solr

安装 Key-Value Store Indexer
根据自己的需求安装,我是安装到了第三台和第四台机器上
sqoop工具是不需要安装的,直接用就可以了
sqoop工具的使用.一层一层的使用help就可以了,很好用
sqoop
sqoop help
sqoop import-all-tables help
sqoop import-all-tables --connect jdbc:mysql://192.168.248.100:3306/hue --username root --password 123456 --hive-database hue --hive-overwrite --hive-import -m 1
报错
[root@cdh1 ~]# sqoop import-all-tables --connect jdbc:mysql://192.168.248.100:3306/hue --username root --password 123456 --hive-database hue --hive-overwrite --hive-import -m 1
Warning: /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
21/01/24 18:01:56 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7-cdh6.2.0
21/01/24 18:01:56 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
21/01/24 18:01:56 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override
21/01/24 18:01:56 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc.
21/01/24 18:01:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
21/01/24 18:01:57 INFO tool.CodeGenTool: Beginning code generation
21/01/24 18:01:57 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `auth_group` AS t LIMIT 1
21/01/24 18:01:57 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `auth_group` AS t LIMIT 1
21/01/24 18:01:57 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce
21/01/24 18:02:01 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/11a5558e8635ad1be6dbccca1313397c/auth_group.jar
21/01/24 18:02:01 WARN manager.MySQLManager: It looks like you are importing from mysql.
21/01/24 18:02:01 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
21/01/24 18:02:01 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
21/01/24 18:02:01 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
21/01/24 18:02:01 INFO mapreduce.ImportJobBase: Beginning import of auth_group
21/01/24 18:02:01 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
21/01/24 18:02:02 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
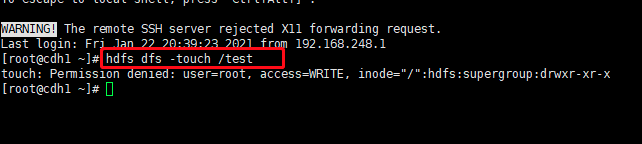
21/01/24 18:02:03 ERROR tool.ImportAllTablesTool: Encountered IOException running import job: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1855)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1839)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1798)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:60)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3101)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1123)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:696)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
解决:export HADOOP_USER_NAME=hdfs
sqoop有一个缺陷,就是原始表中有三个字段,目标表中有三个字段,当原始表中增加一个字段时,这时候目标表中还是3个字段
/tmp/scm_prepare_node.qpevfxaF
http://192.168.248.14/cloudera-repos/cm6/allkeys.asc
解释一下复制因子3份,不是namenode把数据同时传给3个datanode,而是namenode传给一个datanode,这个datanode再传给其他的datanode



安装jdk
[root@cdh1 ~]# yum install oracle-j2sdk1.8.rpm
已加载插件:fastestmirror, langpacks
正在检查 oracle-j2sdk1.8.rpm: oracle-j2sdk1.8-1.8.0+update181-1.x86_64
oracle-j2sdk1.8.rpm 将被安装
正在解决依赖关系
--> 正在检查事务
---> 软件包 oracle-j2sdk1.8.x86_64.0.1.8.0+update181-1 将被 安装
--> 解决依赖关系完成
base/7/x86_64 | 3.6 kB 00:00:00
extras/7/x86_64 | 2.9 kB 00:00:00
updates/7/x86_64 | 2.9 kB 00:00:00
依赖关系解决
===========================================================================================================
Package 架构 版本 源 大小
===========================================================================================================
正在安装:
oracle-j2sdk1.8 x86_64 1.8.0+update181-1 /oracle-j2sdk1.8 364 M
事务概要
===========================================================================================================
安装 1 软件包
总计:364 M
安装大小:364 M
Is this ok [y/d/N]: y
Downloading packages:
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
正在安装 : oracle-j2sdk1.8-1.8.0+update181-1.x86_64 1/1
验证中 : oracle-j2sdk1.8-1.8.0+update181-1.x86_64 1/1
已安装:
oracle-j2sdk1.8.x86_64 0:1.8.0+update181-1
完毕!
[root@cdh1 /]# hdfs
Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
OPTIONS is none or any of:
--buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--daemon (start|status|stop) operate on a daemon
--debug turn on shell script debug mode
--help usage information
--hostnames list[,of,host,names] hosts to use in worker mode
--hosts filename list of hosts to use in worker mode
--loglevel level set the log4j level for this command
--workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
debug run a Debug Admin to execute HDFS debug commands
dfsadmin run a DFS admin client
dfsrouteradmin manage Router-based federation
ec run a HDFS ErasureCoding CLI
fsck run a DFS filesystem checking utility
haadmin run a DFS HA admin client
jmxget get JMX exported values from NameNode or DataNode.
oev apply the offline edits viewer to an edits file
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to a legacy fsimage
storagepolicies list/get/set block storage policies
Client Commands:
classpath prints the class path needed to get the hadoop jar and the required libraries
dfs run a filesystem command on the file system
envvars display computed Hadoop environment variables
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
lsSnapshottableDir list all snapshottable dirs owned by the current user
snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot
version print the version
Daemon Commands:
balancer run a cluster balancing utility
datanode run a DFS datanode
dfsrouter run the DFS router
diskbalancer Distributes data evenly among disks on a given node
httpfs run HttpFS server, the HDFS HTTP Gateway
journalnode run the DFS journalnode
mover run a utility to move block replicas across storage types
namenode run the DFS namenode
nfs3 run an NFS version 3 gateway
portmap run a portmap service
secondarynamenode run the DFS secondary namenode
zkfc run the ZK Failover Controller daemon
SUBCOMMAND may print help when invoked w/o parameters or with -h.
[root@cdh1 /]# hdfs haadmin
Usage: haadmin [-ns <nameserviceId>]
[-transitionToActive [--forceactive] <serviceId>]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-getAllServiceState]
[-checkHealth <serviceId>]
[-help <command>]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
[root@cdh1 /]# hdfs haadmin -getAllServiceState
cdh1:8022 Failed to connect: Access denied for user root. Superuser privilege is required
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkSuperuserPrivilege(FSPermissionChecker.java:131)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkSuperuserPrivilege(FSNamesystem.java:4662)
at org.apache.hadoop.hdfs.server.namenode.NameNode.getServiceStatus(NameNode.java:1770)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getServiceStatus(NameNodeRpcServer.java:1715)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolServerSideTranslatorPB.getServiceStatus(HAServiceProtocolServerSideTranslatorPB.java:131)
at org.apache.hadoop.ha.proto.HAServiceProtocolProtos$HAServiceProtocolService$2.callBlockingMethod(HAServiceProtocolProtos.java:4464)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
cdh2:8022 Failed to connect: Access denied for user root. Superuser privilege is required
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkSuperuserPrivilege(FSPermissionChecker.java:131)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkSuperuserPrivilege(FSNamesystem.java:4662)
at org.apache.hadoop.hdfs.server.namenode.NameNode.getServiceStatus(NameNode.java:1770)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getServiceStatus(NameNodeRpcServer.java:1715)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolServerSideTranslatorPB.getServiceStatus(HAServiceProtocolServerSideTranslatorPB.java:131)
at org.apache.hadoop.ha.proto.HAServiceProtocolProtos$HAServiceProtocolService$2.callBlockingMethod(HAServiceProtocolProtos.java:4464)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
[root@cdh1 /]# hdfs haadmin -getAllServiceState
cdh1:8022 Failed to connect: Access denied for user root. Superuser privilege is required
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkSuperuserPrivilege(FSPermissionChecker.java:131)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkSuperuserPrivilege(FSNamesystem.java:4662)
at org.apache.hadoop.hdfs.server.namenode.NameNode.getServiceStatus(NameNode.java:1770)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getServiceStatus(NameNodeRpcServer.java:1715)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolServerSideTranslatorPB.getServiceStatus(HAServiceProtocolServerSideTranslatorPB.java:131)
at org.apache.hadoop.ha.proto.HAServiceProtocolProtos$HAServiceProtocolService$2.callBlockingMethod(HAServiceProtocolProtos.java:4464)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
cdh2:8022 Failed to connect: Access denied for user root. Superuser privilege is required
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkSuperuserPrivilege(FSPermissionChecker.java:131)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkSuperuserPrivilege(FSNamesystem.java:4662)
at org.apache.hadoop.hdfs.server.namenode.NameNode.getServiceStatus(NameNode.java:1770)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getServiceStatus(NameNodeRpcServer.java:1715)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolServerSideTranslatorPB.getServiceStatus(HAServiceProtocolServerSideTranslatorPB.java:131)
at org.apache.hadoop.ha.proto.HAServiceProtocolProtos$HAServiceProtocolService$2.callBlockingMethod(HAServiceProtocolProtos.java:4464)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
[root@cdh1 /]# export HADOOP_USER_NAME=hdfs
[root@cdh1 /]# hdfs haadmin -getAllServiceState
cdh1:8022 active
cdh2:8022 standby
[root@cdh1 /]#
这个id是怎么玩的?需要去Hadoop的配置文件中去查找
[root@cdh1 /]# hdfs haadmin
Usage: haadmin [-ns <nameserviceId>]
[-transitionToActive [--forceactive] <serviceId>]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-getAllServiceState]
[-checkHealth <serviceId>]
[-help <command>]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
