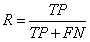以西瓜数据集为例,我们来详细解释一下什么是TP、TN、FP以及FN。
一、基础概念
- TP:被模型预测为正类的正样本
- TN:被模型预测为负类的负样本
- FP:被模型预测为正类的负样本
- FN:被模型预测为负类的正样本
二、通俗理解(以西瓜数据集为例)
以西瓜数据集为例,我们来通俗理解一下什么是TP、TN、FP、FN。
- TP:被模型预测为好瓜的好瓜(是真正的好瓜,而且也被模型预测为好瓜)
- TN:被模型预测为坏瓜的坏瓜(是真正的坏瓜,而且也被模型预测为坏瓜)
- FP:被模型预测为好瓜的坏瓜(瓜是真正的坏瓜,但是被模型预测为了好瓜)
- FN:被模型预测为坏瓜的好瓜(瓜是真正的好瓜,但是被模型预测为了坏瓜)
三、查准率、查全率
还是以西瓜数据集为例
(1)查准率、查全率代表的含义
- 查准率:模型挑出来的西瓜中有多少比例是好瓜
- 查全率:所有的好瓜中有多少比例是被模型挑出来的
(2)如何计算查准率、查全率
查准率用P来表示:
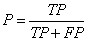
查全率用R来表示: