0、问题大纲
二、大数据基础原理
1、NameNode && DataNode
1、NameNode、DataNode与Secondary NameNode 作用(*2),SNN能接替NN吗?
2、HDFS HA架构?如何实现NameNode HA(*3)?如何实现HA的选举,如NameNode选举。
3、HDFS DataNode死了怎么办,NameNode发生了什么变化?
4、HDFS EditLog写入了,但NameNode元信息没保存在内存中,数据不一致怎么办?
2、HDFS 读写流程
1、HDFS介绍,特性,可存储的文件格式
2、HDFS读写流程(*3)
追问1:写入时,小文件过多会怎样 ?
追问2:写文件如何保证正确性?
追问3:零拷贝模式是什么?
3、Shuffle
1、Shuffle 过程
- 追问1:整个过程有几次排序?
- 追问2:combiner 与 reduce 区别是什么?
- 追问3:MapReduce 和 Spark 的 Shuffle区别有什么?
2、Map端和Reduce端如何对应,数量如何确定,Reduce端数量设置方法
3、以WordCount为例,说明MR的执行机制。
4、其他
1、ES和HDFS的区别
2、海量数据的Count问题(单机),如果把大文件hash成不同的小文件,此时小文件装不下某个Key对应的数据,该怎么办?
一、大数据基础原理
1、NameNode && DataNode
1、NameNode、DataNode与Secondary NameNode 作用(*2),SNN能接替NN吗?
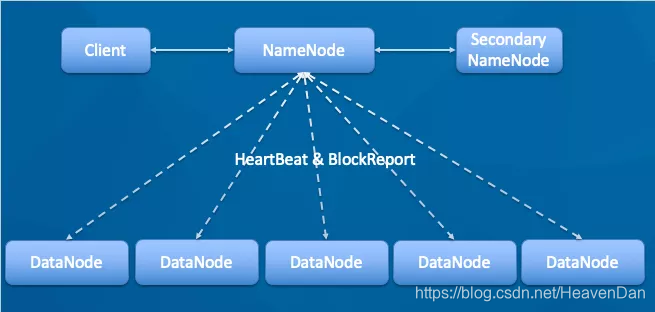
| 节点 | 作用 |
|---|---|
| NameNode | 管理整个文件系统的元数据,记录DataNode名称及存放路径 |
| DataNode | 管理用户的文件数据块,定期向NameNode发送所存储的块(block)的列表 |
| Secondary NameNode | 合并NameNode的edit logs到fsimage中 |
说明:
1、fsimage && edit logs
- fsimage :NameNode启动时,对整个文件系统的快照。
- edit logs:NameNode启动后,对文件系统的改动序列。
2、NameNode结构抽象图:

3、NameNode将信息持久化到磁盘:
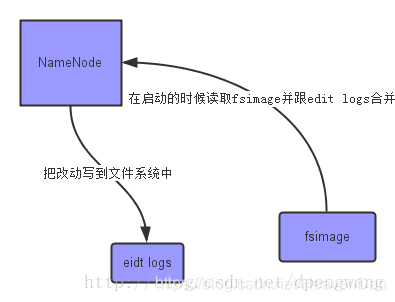
4、Secondary NameNode工作

NameNode运行很长时间后,edit logs会变得很大,上面的改动合并到fsimage会花费很长时间,所以设置助手节点–Secondary NameNode定时查询NameNode的edit logs,将改动合并到fsimage上,再拷贝回fsimage。所以在社区内被认为是检查节点,不是NameNode的备份。
2、HDFS HA架构?如何实现NameNode HA(*3)?如何实现HA的选举,如NameNode选举。
2.1、NameNode HA主体思路
-
1)NN竞争在ZooKeeper上注册,即create一个临时节点,写入成功的那个就是Active;
-
2)注册成功后,通过create后的watcher机制,FailoverController会发送命令给各个NN,并确定各自状态和职责;
-
3)Monitor Health会定时监控NN状态,有问题可能触发重新选举,即重复1-2;
-
4)FailoverController会与ZooKeeper保持心跳,注册的临时节点消失后,也会触发重新选举。
主要组件:
1、DFSZKFailoverController(继承自抽象类ZKFailoverController):ZKFC,
故障转移控制器,守护进程,负责总体故障转移和命令发布;
2、ActiveStandbyElector:实现Active、Standby选举;
3、HealthMonitor:健康监视器,实现NN状态的定时监控。

2.2、如何实现HA的选举,如NameNode选举
答:ZooKeeper提供了简单的机制来实现Acitve Node选举,如果当前Active失效,Standby将会获取一个特定的排他锁,那么获取锁的Node接下来将会成为Active。
补充:
1、NameNode选举具体过程:
Namenode(包括YARN ResourceManager) 的主备选举是通过ActiveStandbyElector 完成,主要利用了
Zookeeper 的写一致性和临时节点机制,具体过程如下:
Step 1. 创建锁节点
1)HealthMonitor 检测NameNode,状态正常就有资格参加 Zookeeper的主备选举。
2)没有发起过主备选举,ActiveStandbyElector 就会尝试在 Zookeeper 上创建一个临时节点。
其写一致性保证只有有一个创建成功,
3)成功的 ActiveStandbyElector 对应的 NameNode 就会成为主 NameNode,回调 ZKFailoverController 方法将其切换为 Active 状态。而失败的切换为standby。
Step 2. 注册 Watcher 监听。
不管创建临时节点是否成功,ActiveStandbyElector 随后向 Zookeeper 注册一个 Watcher 来监听这个节点的状态变化事件,主要关注这个节点的 NodeDeleted 事件
Step 3. 自动触发主备选举。
HealthMonitor 检测到 NameNode 的状态异常时, ZKFailoverController 会主动删除当前在 Zookeeper 上建立的临时节点,这样处于 Standby NameNode 注册的监听器就会收到这个节点的NodeDeleted 事件,收到后马上创建临时节点流程,创建成功就会被选举为Active NameNode。
当然,如果是 Active 状态的 NameNode 所在的机器整个宕掉的话,那么根据 Zookeeper 的临时节点特性,临时节点会自动被删除,从而也会自动进行一次主备切换。
2、防止脑裂(双主现象):
Zookeeper“假死”可能导致出现两个Active NameNode,都可以对外提供服务,无法保证数据一致性。
ActiveStandbyElector通过隔离(Fencing)机制防止脑裂现象。
当某NameNode竞选成功,成功创建ActiveStandbyElectorLock临时节点后会创建另一个名为ActiveBreadCrumb的持久节点,该节点保存了NameNode的地址信息,正常情况下删除ActiveStandbyElectorLock节点时会主动删除ActiveBreadCrumb。
但如果由于异常情况导致Zookeeper Session关闭,此时临时节点ActiveStandbyElectorLock会被删除,但持久节点ActiveBreadCrumb并不会删除,当有新的NameNode竞选成功后它会发现已经存在一个旧的NameNode遗留下来的ActiveBreadCrumb节点,此时会通知ZKFC。
3、HDFS DataNode死了怎么办,NameNode发生了什么变化?
- 剩余2个正常DataNode会发一个标识给NameNode,然后NameNode会从原pipeline删除故障节点;
- NameNode会通过新构建的pipeline给两个正常节点写数据;
- 下次HDFS使用该Block,会检测到备份数为2,然后会重新备份,让replication数达到3,将DataNode状态置为正常。
4、HDFS EditLog写入了,但NameNode元信息没保存在内存中,数据不一致怎么办?
Secondary NameNode会将Editlog改动信息更新到fsimage,NameNode启动时会首先把faimage文件加载到内存中形成文件系统镜像。
2、HDFS 读写流程
1、HDFS介绍,特性,可存储的文件格式
1)介绍:HDFS-Hadoop Distributed File System,分布式文件系统。
2)特性:
- 海量数据: HDFS可横向扩展,其存储的文件可以支持PB级别或更高级别的数据存储。
- 高容错性:数据保存多个副本,副本丢失后自动恢复。
- 廉价机器:设计时充分考虑可靠性、安全性及高可用性,对硬件要求低。
局限性:
- 延迟较高。HDFS为了处理大型数据集,高吞吐量的代价是较高延迟,10毫秒下访问无法做到。(hbase可以弥补)
- 大量小文件效率低。NameNode节点内存中存在整个文件系统元数据(150字节/个),因此文件数量收到限制。
- 不支持多用户写入 & 修改文件。不支持多用户对同一文件进行操作,而且写操作只能在文件末尾完成,即追加操作。
4)可存储文件格式:
- 行式存储:SequenceFile、MapFile、Avro Datafile
- 列式存储:Rcfile、Orcfile、Parquet
2、HDFS读写流程(*3)
读文件:
- 客户端调用 open 方法,打开一个文件。
- NN根据拓扑结构返回距Client最近的DN(block-location。
- 客户端直接访问 DN 读取 block 数据并计算校验和,整个数据流不经过 NN。
- 读取完一个 block 会读取下一个 block。
- 所有 block 读取完成,关闭文件。
写文件:
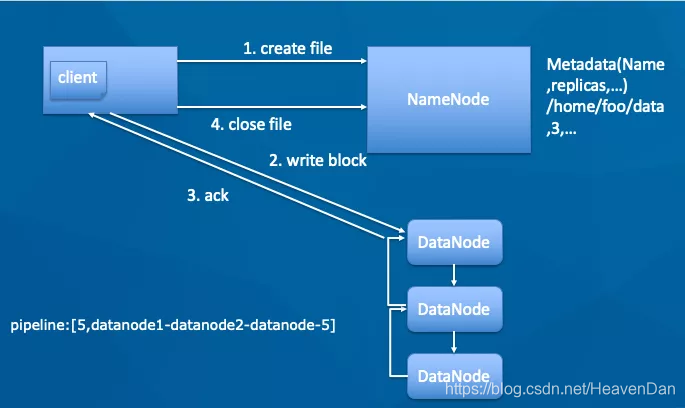
- client 调用 create 方法,NN会做创建新文件的各种校验。(校验:如文件是否已经存在,客户端是否有权限等)
- 若校验通过,client 开始写数据到 DN(DataNode)。文件会按照 block 大小进行切块,默认 128M(可配置),DataNode 构成 pipeline 管道,client 端向输出流对象中写数据,传输的时候是以比 block 更小的 packet 为单位进行传输,packet 又可拆分为多个 chunk,每个 chunk 都携带校验信息。
- 每个 DataNode 写完一个块后会返回确认信息。并不是每个 packet 写成功就返回一次确认。
- 写完数据,关闭文件。
补充:
1、写入详细过程可参考14。
2、DN发给NN完成信号的时机取决于集群是强一致性还是最终一致性
- 强一致性:所有DataNode写完后才向NameNode汇报;(HDFS一般情况)
- 最终一致性:任意一个DataNode写完后就能向NameNode汇报。
追问1:写入时,小文件过多会怎样 ?
- 通用方案:
- 1)Hadoop Archive:将小文件打包成HAR文件放入HDFS块中的文件存档工具,可以减少 NN 内存使用,仍允许对文件进行透明访问。
- 2)Sequence file:一系列二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
- 底层方案:
- 1)HDFS-8998:DN 划分小文件区专门存储,一个block满才使用下一个。
- 2)HDFS-8286:将元数据从 NN 从内存移到第三方k-v存储系统中。
- 3)HDFS-7240:Apache Hadoop Ozone,hadoop子项目,为扩展hdfs而生。
追问2:写文件如何保证正确性?
-
WAL-write ahead log,先写Log,再写内存。EditLog记录最新写操作。如果后续失败,操作被先写入EditLog,可根据其中记录恢复。
-
client 通过 NN 分配的 pipeline 向 DN 写入packet,这个packet便直接在 pipeline传给第2,3个。packet中每个chunk都携带校验信息。
追问3:零拷贝模式是什么?
答:零拷贝(zero-copy)"是一种系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”。
系统上下文切换减少为2次,可以提升一倍的性能
3、Shuffle
MapReduce计算模型主要由三阶段构成:Map、Shuffle、Reduce。
- Map:输入数据,做初步处理,输出形式的中间结果;
- Shuffle:按照partition、key对中间结果进行排序合并,输出到reduce的线程;
- Reduce:对相同key的输入进行最终处理,并将结果写入到文件。
1、Shuffle 过程
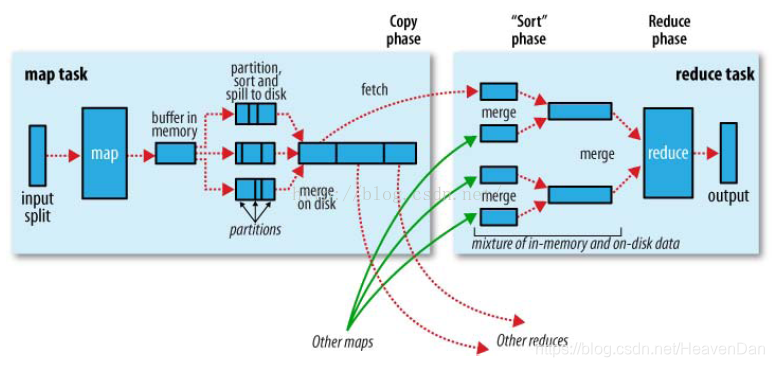

Map端:将map结果分区、排序、合并。
- 1)Partioner:Partitioner接口对key进行hash后,再以Reduce task数量取模后,到对应Reduce task位置。然后将数据(key/value、partition结果序列化后)写入到内存缓冲区,缓冲区的作用是批量收集map结果,减少磁盘IO。
- 2)Spill(溢写):sort & combiner:map task端输出数据达到设定阈值会启动溢写。写入前先按partition、后按key进行排序。combiner是个reduce过程,可以减少map和reduce任务间传输的中间数据,减少partition索引记录。
- 3)merge on disk:数据很大会产生多个溢写文件,map task任务处理完,会对所有中间数据文件做一次合并排序操作,最终1个map task只生成一个中间数据文件
Reduce端:从map端拉取结果不断merge,生成最终结果。:
- copy:通过Fetcher线程求获取map task output 拷贝到本地。这些数据首先保存在内存缓冲区,使用率达到阈值就写到磁盘。
- merge & sort:将来自各个map的数据merge成有序的更大文件。一边merge一边sort,过程重叠而非完全分开。
- reduce:merge最后会生成一个文件,大多数存在磁盘中。当reducer输入文件已定,整个shuffle阶段才结束。 (然后是Reducer执行,把结果放到HDFS上。)
小结:Map端做些数据的局部处理和打散工作,Reduce做些数据的汇总工作。
追问1:整个过程有几次排序?
答:3次。
- 1)快速排序。在map阶段,由环形缓冲区溢出到磁盘上时,落地磁盘的文件会按照key进行分区和排序,属于分区内有序。
- 2)归并排序。map阶段,对溢出的文件进行combiner合并过程中,需要对溢出的小文件进行归档排序、合并。
由于溢写文件已经经过第一次排序,所有合并文件只需再做一次排序即可使输出文件整体有序。
3)归并排序。reduce阶段,需要将map task输出文件copy到reduce task中合并。
经过第二次排序,只需再做一次排序即可使输出文件整体有序。
追问2:combiner 与 reduce 区别是什么?
答:combiner发生在map端,处理一个任务中的文件数据,不能跨map任务;reduce可以接收多个map任务进行处理。
追问3:MapReduce 和 Spark 的 Shuffle区别有什么?
- 1)Hadoop的有一个Map完成,Reduce便可以去fetch数据了,不必等到所有Map任务完成,而Spark的必须等到父stage完成,也就是父stage的map操作全部完成才能去fetch数据。
- 2)Hadoop的Shuffle是sort-base的,那么不管是Map的输出,还是Reduce的输出,都是partion内有序的,而spark不要求这一点。
- 3)Hadoop的Reduce要等到fetch完全部数据,才将数据传入reduce函数进行聚合,而spark是一边fetch一边聚合。
……
2、Map端和Reduce端如何对应,数量如何确定,Reduce端数量设置方法
- 1) Map数量:通常由 Hadoop 集群的数据块大小(输入文件的总块数)确定的,正常的 Map 数量的并行规模大致是每一个 Node 是10~100个。
- 2)Reduce数量:正常是0.95或1.75*(节点数*CPU数量)。
Reducer:可通过job.setNumReduceTasks手动设置决定
- 3)数量对应:Partition:由PartitionerClass确定,默认使用的HashPartitioner中使用hash值与reducerNum的余数,即由reducerNum决定,等于Reducer(分区数)数目。
if 自定义reducerNum<Reducer,then 报错;
else(>) 产生无任务的reduecer但不会影响结果
3、以WordCount为例,说明MR的执行机制。
……
4、其他
1、ES和HDFS的区别
ES:分布式搜索引擎,存储JSON格式,有RESTful操作接口,支持全文检索,底层是倒排索引。
HDFS:配合附着上面的工具,更擅长需要大量复杂处理和分析海量数据。
……
2、海量数据的Count问题(单机),如果把大文件hash成不同的小文件,此时小文件装不下某个Key对应的数据,该怎么办?
……
二、参考
1、Hadoop中的Namenode、Datanode和Secondary Namenode
2、HDFS详解一:namenode、datanode工作原理
3、Secondary NameNode 的作用
4、Hadoop写文件时datanode发生故障的处理过程
5、HDFS NameNode HA 实现综述
6、大数据之Hadoop HDFS-HA架构
7、HDFS NameNode的高可用 面试版
8、Hadoop之HDFS简介
9、HDFS主要特性和体系结构
10、刚哥谈架构 (七)- 大数据的文件存储
11、4.初识Hadoop文件格式
12、Hadoop 小文件处理- 一剑风徽- 博客园
13、[Hadoop]大量小文件问题及解决方案
14、HDFS写文件流程(详细必看)
15、零复制
16、原来 8 张图,就可以搞懂「零拷贝」了
17、深入剖析Linux IO原理和几种零拷贝机制的实现
18、Hadoop中Shuffle过程
19、MapReduce shuffle过程详解
20、hadoop中shuffle过程详解
21、Spark详解04Shuffle 过程Shuffle 过程
22、MapReduce程序中的经过几次排序?三次
23、MapReduce 的 shuffle 过程中经历了几次 sort ?
24、剖析Hadoop和Spark的Shuffle过程差异
25、Spark专题(二):Hadoop Shuffle VS Spark Shuffle
26、MapReduce Shuffle 和 Spark Shuffle 区别看这篇就够了
26、Mapreduce中Mapper、Partition、Reducer数目的确定与关系
27、MapReduce 中 map 和 reduce 数量之间的关系
28、MongoDB、ElasticSearch、Redis、HBase这四种热门数据库的优缺点及应用场景
29、聊聊MySQL、HBase、ES的特点和区别
30、Elasticsearch、MongoDB和Hadoop比较
31、以wordcount为例详细描述mr执行过程