文本生成是自然语言理解的高级阶段,是实现类人智能的重要手段之一。Geek.AI在AAAI2018中推出了LeakGAN后,终于又推出了TexyGen这个开源文本生成框架。由于之前就想对leakgan深入地看一下,不过这回可以通过TexyGen这个框架来实现实现对近几年的所有文本生成模型的直接实现。
目前其支持的模型如下:
Implemented Models and Original Papers
SeqGAN - SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
MaliGAN - Maximum-Likelihood Augmented Discrete Generative Adversarial Networks
LeakGAN - Long Text Generation via Adversarial Training with Leaked Information
GSGAN - GANS for Sequences of Discrete Elements with the Gumbel-softmax Distribution
从SeqGAN, LeakGAN、TextGAN等全部涵盖在里面。GAN是实现无监督学习和样本生成的重要方法,而GAN与NLP的结合来实现文本生成也是很自然的切入点。GAN的成功激发了人们对文本离散数据对抗性训练研究的兴趣。例如,序列生成对抗网络SeqGAN是应用REINFORCE算法解决原始GAN目标函数的离散优化的早期尝试之一。自那以后,研究人员提出了许多改进SeqGAN的方法来进一步提升SeqGAN的性能,例如梯度消失(MaliGAN ,RankGAN ,LeakGAN 使用的自举再激活),以及生成长文本时的鲁棒性(LeakGAN)。
如SeqGAN的框架如下所示:

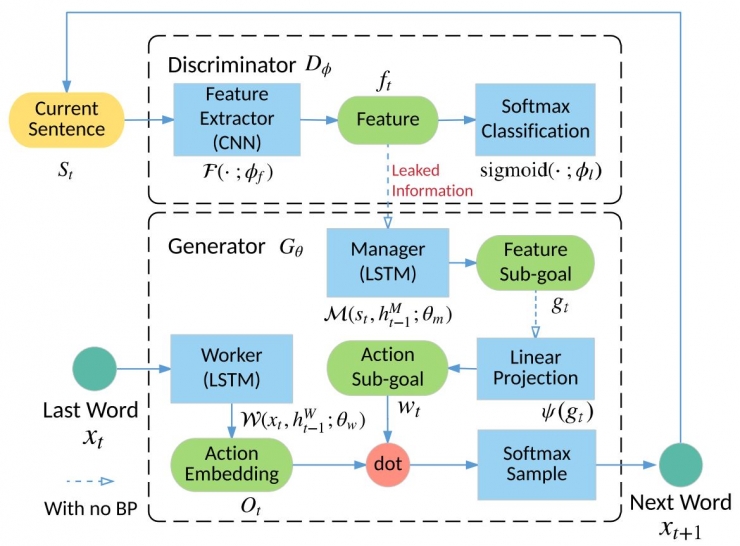
LeakGAN的原理框架如下所示:
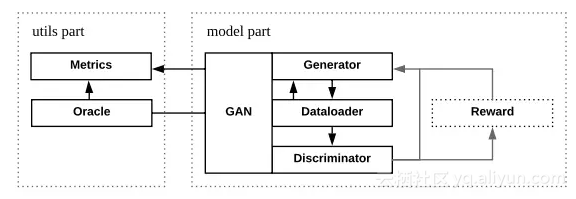
Texygen框架呢则实现将所有的GAN以派生的方式进行综合抽象。
此外,重要的是Texygen提供了一个多元化的文本评价指标体系,它包括了5个文本生成的评测指标,主要如下:
基于文档相似度的指标。生成的文档质量的最直观的评测指标是文档与自然语言或者训练数据集的类似程度:
BLEU:基于词袋(bag of words)模型的评测指标。以词和词组为基本单位。
EmbSim :使用模型输出的序列训练出的词向量的相互相似性特征定义的评测指标。以基本词元(token)为基本单位。
基于似然性(likelihood)的指标:
NLL-oracle:基于人造数据的似然度估计。衡量待评测语言模型的输出在构造出的人造数据模型衡量下的负对数似然。
NLL-test:基于测试数据的似然度估计。衡量构造出测试数据在待评测语言模型的衡量下的负对数似然。
基于多样性评价的指标:
Self-BLEU:基于词袋(bag of words)模型的评测指标。衡量一个模型的每一句输出与此模型其他输出的相似性。以词和词组为基本单位。
2、实践训练
此处只以leakgan的训练进行RUN。
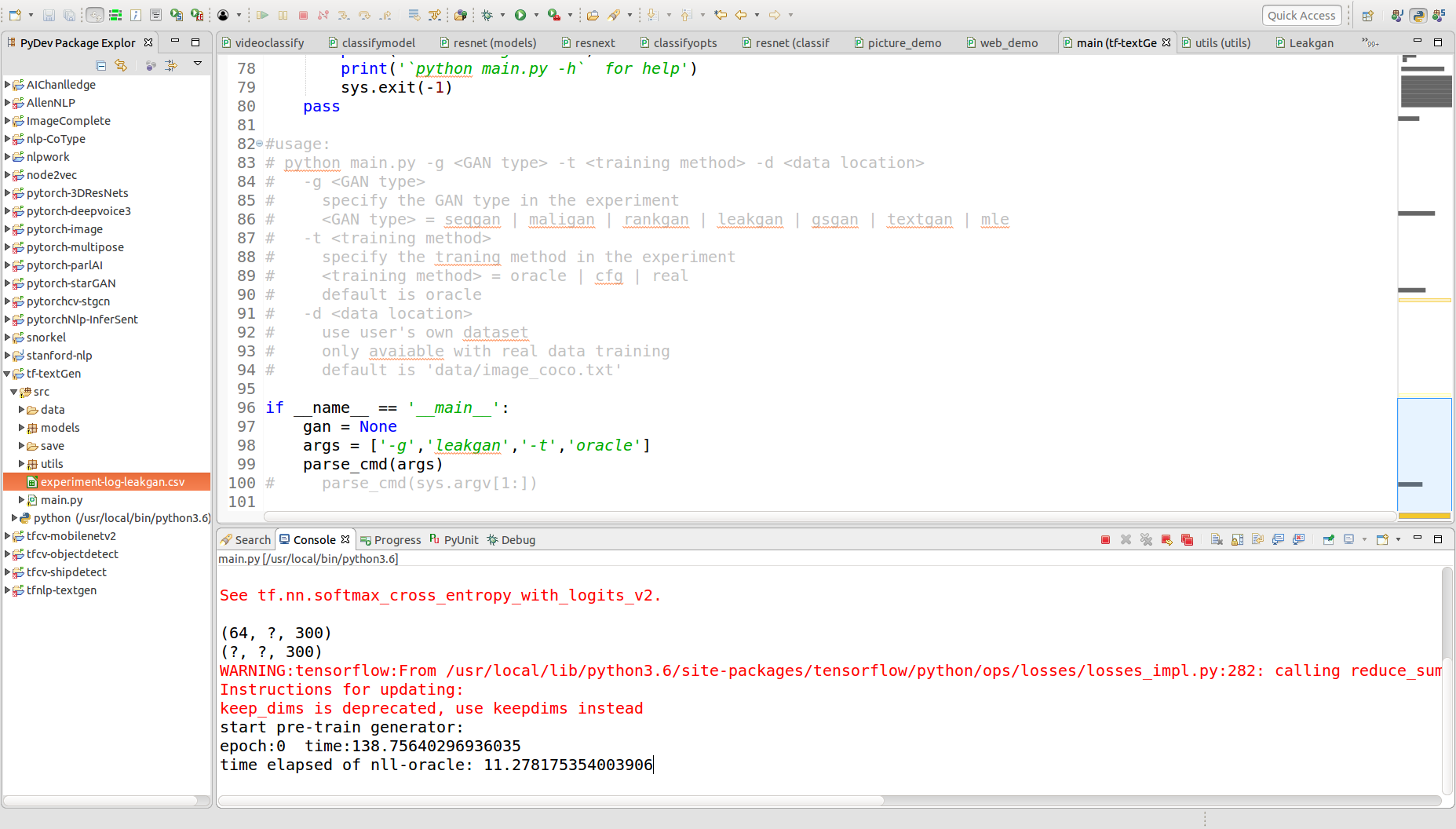
可以看出在每个epoch中,都会计算评测的数值。