在研究大量的数据之中,哪几组数据比较接近的时候(如哪几个城市的消费习惯比较接近)可以选用这个多分类算法。笔者在观看清风的数模教程以后,总结如下要点:
k-means操作流程
- 选择分类数量k、设置算法的迭代次数
- 选定初始的k个聚类中心
- 将所有数据按照距离划分给这k个聚类中心
- 调整聚类中心的位置(调整为其下所属数据的中心)
- 重复上述3-4步直到中心位置不再变化或达到迭代次数为止
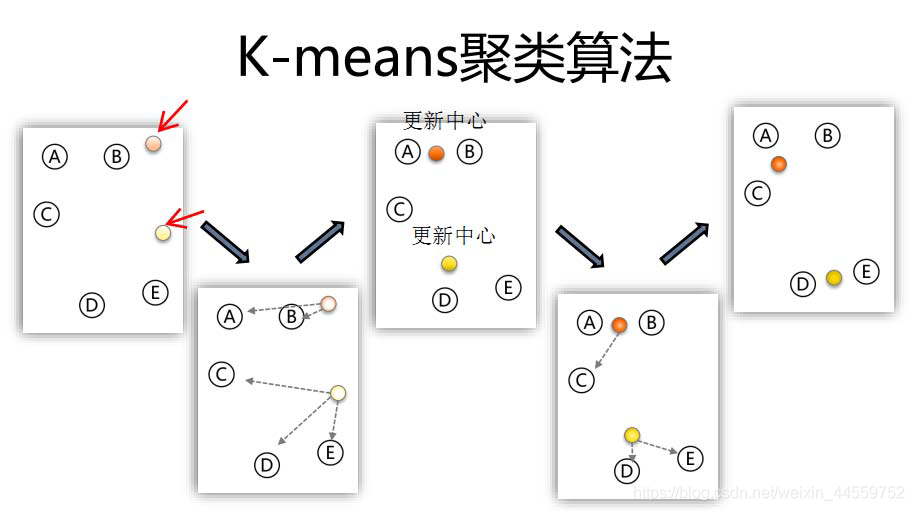
在实际建模论文中,算法流程描述推荐使用流程图的形式来简化冗余的复述、避免查重
k-means的优缺点
优点
- 简单、快速
- 高效处理大数据集
缺点
- 事先给定的类数k完全由用户指定,过于主观缺乏可靠标准
- 初值敏感
- 孤立点敏感
k-means++:k-means的改进算法
为了尽可能避免上述缺点,提出k-means++算法。
基本原则
选取初始聚类中心的时候,使其间距离尽可能地大
基本原则的实现
其改进的地方只在于聚类中心的选取,选取方法如下:
- 随机选择一个初始聚类中心
- 计算各个数据点到第一个中心的距离,以此作为权值来计算下一个聚类中心【轮盘法】
- 重复第二步,直到选出k个聚类中心为止
为什么能实现?
第二步选取下一个聚类中心的时候,当前数据点距离第一个中心的距离越大,权值就越大,这个数据点的附近就越有可能被选为第二个聚类中心。即:实现了第二个聚类中心距离第一个尽可能远!
均值聚类算法的两个讨论
-
我们希望将数据划分为k类,那这个k怎么确定?
一般根据题目判断,分为几类会比较好描述,就分几类。
比如“哪几个城市的消费习惯比较接近”这个问题,取k=2或3都比较合适。k=2时描述可以是:第一类城市消费水平较高,第二类消费水平较低。k=3时则将各个城市的消费水平分为高、中、低三档。
-
数据量纲不一致怎么办?
比如我们遇到了一组物什的性质描述数据,其中一个数据量纲是长度(m)一个为重量(t),二者差异太大/直接计算的数据没有意义怎么办?
使用公式 X i − X 平 均 X 标 准 差 \frac{X_i-X_{平均}}{X_{标准差}} X标准差Xi−X平均对数据进行标准化。再使用标准化以后的数据来聚类即可。