参看的视频:
CNN思想
灵感
在处理图像问题时往往会遇到几个问题:
- 我们往往在观察图像时只注意一些特定的部位。
比如这只猫,我们想要知道这站图片是否有猫眼并不需要整张图片,而是只需要局部的某个区域。

比如可能只需要下面框框里的部分。

2. 对于某一特定区域它的位置是不固定的。
这个也很好理解,毕竟每张图片的猫的眼睛都不一定在图片中的同一位置。
3. 对于一个图片,我们可以对其进行下采样
也就是说我们可以做一些操作使图片缩小,从而减少输入的特征数。
大致过程
CNN大致的工作过程如下
- Convolution(卷积)
- pooling(池化)
- 重复1和2若干次
- 送入全连接网络中
卷积
单个channel
卷积可以解决上述的第一和第二个问题。
一张彩色位图中每一个点由RGB三种颜色构成,每种颜色都可以用一个二维矩阵来表示。
三种颜色就需要用三维的矩阵来表示了,假设图片宽m个像素,宽n个像素。那么一个彩色位图的信息就可以用3 x n x m的三维矩阵来表示。
而一个只有黑白颜色的位图只需要由一种颜色来构成,所以就要用1 x n x m的矩阵来表示。
这个彩色位图我们就说他有三个channel,因为用来表示像素信息的n x m矩阵有三个。
而黑白的我们说他有一个channel
比如一个6 x 6的黑白图片。
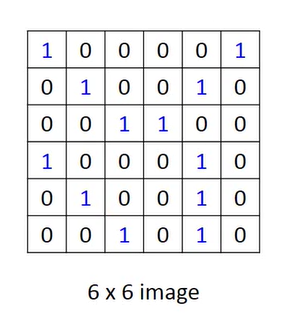
其中1就可以代表这里有黑色的块,0就代表这里是白色。
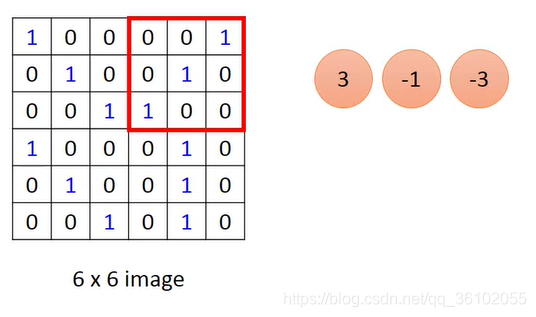
而卷积的操作就是先选定一个固定大小的窗口。
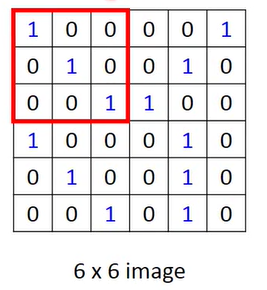
然后把这个窗口内的像素值都对应的乘以一个权重,就是下面这个矩阵,我们把它交做卷积核。
注意这个乘法就是下面这个矩阵中和上面窗口中对应位置的元素相乘。
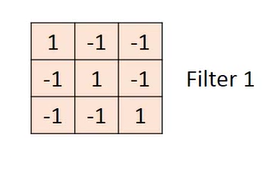
于是就可以得到一个值:3
然后移动窗口
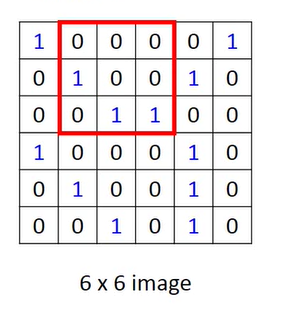
继续让窗口的元素的值和对应上述卷积核中的权重相乘。
这样不断移动窗口,进行乘积运算并且把得到的值都按照顺序摆放
于是就可以得到一个新的矩阵,这个矩阵就是通过卷积得来的。
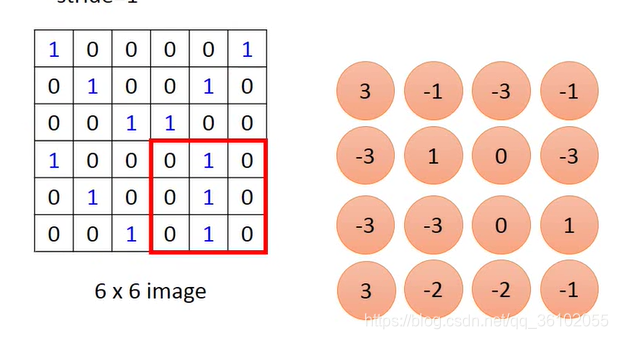
可以看到卷积核的大小决定了得到的矩阵的大小。
在移动的过程中,我们每次都移动一个像素点,我们也可以一次移动多个像素点,也就是调整步长stride为不同的值。
假设输入的像素矩阵是 m × n m\times n m×n的,卷积核是 a × b a\times b a×b的,并且步长stride是 s s s那么得到的输出矩阵大小就是 ( m − a s + 1 ) × ( n − b s + 1 ) (\frac{m - a}{s} + 1)\times (\frac{n - b}{s} + 1) (sm−a+1)×(sn−b+1)。
多个channel
对于多个channel的彩色位图,我们使用的卷积核自然不可能再是一个二维矩阵,而是一个由和channel数量一样多的二维卷积核堆积而成。
比如三个channel的RGB图,它的卷积核就可能是这样的
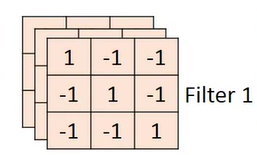
这样的得到的输出矩阵也是一个三维的矩阵。
得到输出后,沿着channel这个维度对得到的矩阵进行求和,于是就得到了最终的输出结果。
也就是对于一个卷积核来说它的最终输出的channel一定是1。
一个卷积核就可以做到扫描图片中的所有区域去检查是否出现某一个图案,卷积核中的权重是通过train得来的。
而对于一个图片我们需要检测特定的图案不止一种,于是我们就可以使用多个卷积核来探测不同的图案。
输出矩阵的形状
首先能决定输出形状的有几个参数:
- 输入的数据 N × c × m × n N\times c \times m \times n N×c×m×n
其中N表示样本数,c代表channel。 - 卷积核大小 a × b a\times b a×b,以及卷积核的个数A
- 步长stride,padding
其中padding就类似于一种填充,他会把输入的矩阵外层填充一层空白像素,使原来的 n × m n\times m n×m的矩阵变成 ( n + p a d d i n g ∗ 2 ) × ( m + p a d d i n g ∗ 2 ) (n + padding * 2) \times (m + padding * 2) (n+padding∗2)×(m+padding∗2)的矩阵。
有了上面的参数就可以得到输出矩阵形状 N × A × m ′ × n ′ N\times A \times m' \times n' N×A×m′×n′
其中
m ′ = m + p a d d i n g ∗ 2 − a s t r i d e + 1 n ′ = n + p a d d i n g ∗ 2 − b s t r i d e + 1 m'=\frac{m + padding * 2 - a}{stride} + 1\\n'=\frac{n+padding * 2 - b}{stride} + 1 m′=stridem+padding∗2−a+1n′=striden+padding∗2−b+1
可以看到,输出矩阵的channel数由卷积核的数目决定决定,而m和n则由多个因素决定。
池化
进行卷积之后,下一个操作就是池化。
池化也可以作为一种下采样,来降低特征的规模。
池化有很多种,比如maxpooling,averagepooling等
比如maxpooling,他会和卷积一样,滑动着取一些区域,然后取每个区域的最大值最为这个区域的采样。
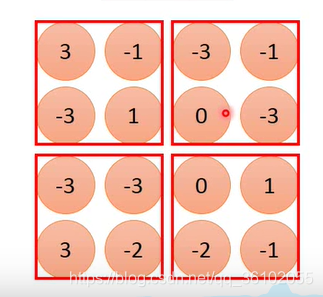
然后把它们堆叠在一起,得到输出
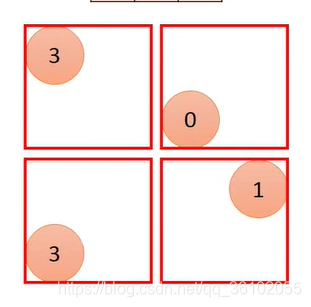
于是就得到了一个 2 × 2 2\times2 2×2大小的矩阵。
需要注意的是pooling过程中窗口也是和卷积中的一样在滑动的,所以输出矩阵的n和m的计算方法和上面卷积的一样。
在反复的卷积池化多次之后,就可以得到一个 N × c × n × m N\times c\times n\times m N×c×n×m的矩阵。我们把它拉直变成 N × ( c ∗ n ∗ m ) N\times(c * n *m) N×(c∗n∗m)的矩阵,然后扔给一个全连接网络就可以了。
仔细观察CNN整个过程,其实和普通的全连接网络相比,就是多加了一个通过卷积和池化提取特征的过程。
pytorch的CNN
这里使用pytorch来搭建一个简单的CNN网络,从而对Mnist数据集进行训练。
首先导入必要的包。
import torch
from torch import nn
from torchvision import transforms
from torchvision import datasets
然后把数据集导入
compose = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
batch_size = 600
mnist_train = datasets.MNIST('./datasets/mnist', download=True, train=True, transform=compose)
loader_train = torch.utils.data.DataLoader(dataset=mnist_train, shuffle=True, batch_size=batch_size, num_workers=4)
mnist_test = datasets.MNIST('./datasets/mnist', download=True, train=False, transform=compose)
loader_test = torch.utils.data.DataLoader(dataset=mnist_test, shuffle=True, batch_size=10000)
接着来构建网络架构,大概结构是,卷积两次,池化两次,接着放入一个320输入10输出的全连接层。
注意,卷积层实际上也是在做线性的运算,所以也要加上非线性激活函数
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cv1 = nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5) # 卷积层1
self.cv2 = nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5) # 卷积层2
self.maxpooling = nn.MaxPool2d(kernel_size=2) # 池化
self.liner = nn.Linear(320, 10)
def forward(self, x):
x = nn.functional.relu(self.cv1(x))
x = self.maxpooling(x)
x = nn.functional.relu(self.cv2(x))
x = self.maxpooling(x)
x = x.view(x.shape[0], -1)
x = self.liner(x)
return x
然后创建一个模型并且移到cuda里,创建一个优化器,规定一个损失函数
moudle = CNN().cuda()
optimizer = torch.optim.SGD(moudle.parameters(), lr=0.1, momentum=0.02)
loss_fun = nn.functional.cross_entropy
写一个函数用来计算测试集的acc
def test():
with torch.no_grad():
for batch in loader_test:
data, target = batch
data = data.cuda()
target = target.cuda()
acc = (torch.argmax(moudle(data), dim=1) == target).sum().item() / target.shape[0]
print(acc)
接下来就是梯度下降部分
if __name__ == '__main__':
for epoch in range(10):
for i, batch in enumerate(loader_train):
data, target = batch
target = torch.LongTensor(target)
data = data.cuda()
target = target.cuda()
y_hat = moudle(data)
loss = loss_fun(y_hat, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
test()
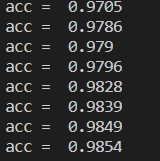
最终差不多有98.5%的准确率,在计算下去准确率就会下降,过拟合就会发生。