ES Restful API GET、POST、PUT、DELETE、HEAD含义:
1)GET:获取请求对象的当前状态。
2)POST:改变对象的当前状态。
3)PUT:创建一个对象。
4)DELETE:销毁对象。
5)HEAD:请求获取对象的基础信息。
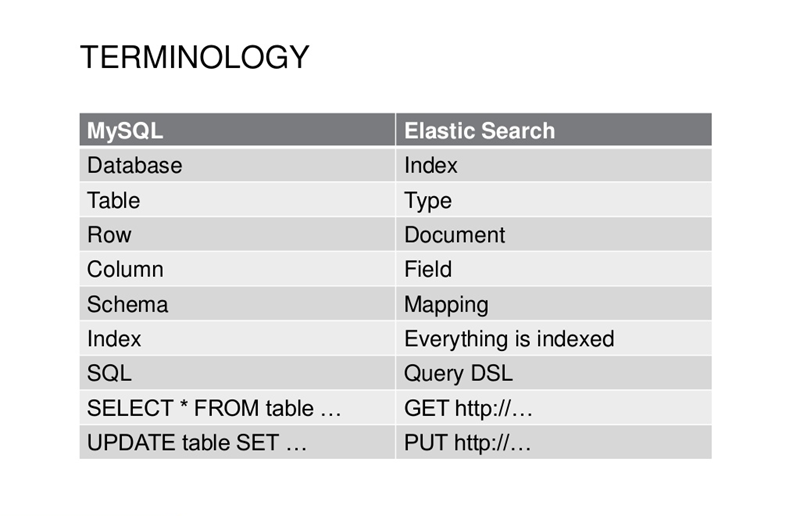
Mysql与Elasticsearch核心概念对比示意图
一.插入
1.PUT指定Id插入
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}2.POST自动生成ID插入
PUT /megacorp/employee
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}3.批量插入
curl -XPOST localhost:9200/_bulk --data-binary @data.json
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:03:00"}
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:04:00"}
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:05:00"}
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:06:00"}
{"index":{"_index":"meterdata","_type":"autoData"}}
{"Mfid ":1,"TData":172170,"TMoney":209,"HTime":"2016-05-17T08:07:00"}4.upsert插入
当文档存在时,执行脚本;当文档不存在时,upsert中的内容就会插入到对应的文档中
curl -XPOST 'localhost:9200/test/type1/1/_update' -d '{
"script" : {
"inline": "ctx._source.counter += count",
"params" : {
"count" : 4
}
},
"upsert" : {
"counter" : 1
}
}'二、更新
可以使用Script对所有的文档执行更新操作,也可以使用doc对部分文档执行更新,也可以使用upsert对不存在的文档执行添加操作。
1.全部更新
curl -XPUT localhost:9200/test/type1/1 -d '{
"counter" : 1,
"tags" : ["red"]
}'2.部分更新
curl -XPOST "localhost:9200/gengxin/update/1/_update?pretty" -d '
{
"doc": {"job": "奋斗者"}
}'
3.脚本更新
(1).更新部分字段
curl -XPOST 'localhost:9200/test/type1/1/_update' -d '{
"script" : {
"inline": "ctx._source.counter += count",
"params" : {
"count" : 4
}
}
}'(2).新加字段
curl -XPOST 'localhost:9200/test/type1/1/_update' -d '{
"script" : "ctx._source.name_of_new_field = \"value_of_new_field\""
}'(3).移除字段
curl -XPOST 'localhost:9200/test/type1/1/_update' -d '{
"script" : "ctx._source.remove(\"name_of_field\")"
}'curl -XPOST 'localhost:9200/test/type1/1/_update' -d '{
"script" : {
"inline": "ctx._source.tags.contains(tag) ? ctx.op = \"delete\" : ctx.op = \"none\"",
"params" : {
"tag" : "blue"
}
}
}'全部更新和部分更新区别?
全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的。
部分更新,只是修改某个字段。
参考:
http://www.cnblogs.com/shihuc/p/5978078.html
http://www.cnblogs.com/xing901022/p/5330778.html
三、删除
curl -XDELETE 'http://localhost:9200/twitter/tweet/1'路由
如果在索引的时候提供了路由,那么删除的时候,也需要指定相应的路由:
$ curl -XDELETE 'http://localhost:9200/twitter/tweet/1?routing=kimchy'上面的例子中,想要删除id为1的索引,会通过固定的路由查找文档。如果路由不正确,可能查不到相关的文档。对于某种情况,需要使用_routing参数,但是却没有任何的值,那么删除请求会广播到每个分片,执行删除操作。
ES删除总结
如果文档存在,es会返回200 ok的状态码,found属性值为true,_version属性的值+1。
如果文档不存在,es会返回404 Not Found的状态码,found属性值为false,但是_version属性的值依然会+1,这个就是内部管理的一部分,它保证了我们在多个节点间的不同操作的顺序都被正确标记了。
ES的删除操作,也是不会立即生效,跟更新操作类似。只是会被标记为已删除状态,ES后期会自动删除。
好比,你删除的操作一步一步累积,当达到它上限时,等你删除几十条数据后,ES我一次性删除,这样可以节省磁盘IO。
参考:
http://www.cnblogs.com/zlslch/p/6421648.html
http://www.cnblogs.com/xing901022/archive/2016/03/26/5321659.html
四、查询
1.query和filte
(1)查询上下文:查询操作不仅仅会进行查询,还会计算分值,用于确定相关度;
(2)过滤器上下文:查询操作仅判断是否满足查询条件,不会计算得分,查询的结果可以被缓存。
参考:http://www.cnblogs.com/xing901022/p/4975931.html
轻量级搜索,查询字符串(query string)
GET /megacorp/employee/_search?q=last_name:Smith2.Filter DSL
(1)term
代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇(如果为中文,默认当个字为一个索引,只能搜索到单个字)
POST /megacorp/employee/_search
{
"query": {
"term": {
"last_name": "Smith"
}
}
}(2)terms 过滤
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
POST /megacorp/employee/_search
{
"query": {
"terms": {
"last_name": ["Bob","Smith"]
}
}
}(3)range 过滤
允许我们按照指定范围查找一批数据
POST /megacorp/employee/_search
{
"query": {
"range": {
"age": {
"gt": 18
}
}
}
}(4)exists 和 missing 过滤
可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL条件.
POST /megacorp/employee/_search
{
"query": {
"exists": {
"field": "title"
}
}
}(5)Bool合并查询(Combining Queries)
使用bool过滤器来合并多个过滤器以实现and,or和not逻辑。should满足的匹配度更高。must语句都需要匹配,而所有的must_not语句都不能匹配。默认情况下,should语句一个都不要求匹配,只有一个特例:如果查询中没有must语句,那么至少要匹配一个should语句。minimum_should_match参数来控制should语句需要匹配的数量,该参数可以是一个绝对数值或者一个百分比。
GET /my_index/my_type/_search
{
"query": {
"bool": {
"must": { "match": { "title": "quick" }},
"must_not": { "match": { "title": "lazy" }},
"should": [
{ "match": { "title": "brown" }},
{ "match": { "title": "dog" }}
]
}
}
}
(6)过滤器(filter)
来实现sql中where的效果, 比如:搜索一个叫Smith,且年龄大于30的员工,可以这么检索.
POST /megacorp/employee/_search
{
"query" : {
"filtered" : {
"filter" : {
"range" : {
"age" : { "gt" : 30 }
}
},
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
}
}(7)聚合(aggregations)
它允许你在数据上生成复杂的分析统计,类似于sql中的group by
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}聚合也允许分级汇总。例如,让我们统计每种兴趣下职员的平均年龄
GET /megacorp/employee/_search
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}3.Query DSL
(1)match_all 查询
可以查询到所有文档,是没有查询条件下的默认语句。
POST /index/doc/_search
{
"query" : {
"match_all": {}
}
}(2)match查询
一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
POST /index/doc/_search
{
"query" : {
"match" : {
"title" : "中国杭州"
}
}
}match查询接受一个operator参数,该参数的默认值是"or"。可以将它改变为"and"来要求所有的词条都需要被匹配,来提高搜索精度。
POST /index/doc/_search
{
"query": {
"match": {
"title": {
"query": "中国 杭州",
"operator": "and"
}
}
}
}
控制精度(Controlling Precision),在下面拥有3个词条的例子中,75%会被向下舍入到66.6%,即3个词条中的2个。无论你输入的是什么,至少有2个词条被匹配时,该文档才会被算作最终结果中的一员。
GET /index/doc/_search
{
"query": {
"match": {
"title": {
"query": "中国杭州",
"minimum_should_match": "75%"
}
}
}
}
分值计算(Score Calculation)
bool查询通过将匹配的must和should语句的_score相加,然后除以must和should语句的总数来得到相关度分值_score。must_not语句不会影响分值;它们唯一的目的是将不需要的文档排除在外。
(3)multi_match查询
允许你做match查询的基础上同时搜索多个字段,在多个字段中同时查一个:
POST /index/doc/_search
{
"query" : {
"multi_match": {
"query": "中国",
"fields": [ "content", "title" ]
}
}
}(4)match_phrase短语搜索(phrases)
match_phrase与match的区别在于,前者会命中”rock“ “climbing”(有序)全部匹配到的数据,而后者会命中rock balabala climbing , 前者可用调节因子slop控制不匹配的数量。
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing",
"slop" : 1
}
}
}(5)bool 查询
与 bool 过滤相似,用于合并多个查询子句。不同的是,bool 过滤可以直接给出是否匹配成功, 而bool 查询要计算每一个查询子句的 _score (相关性分值)。
must:: 查询指定文档一定要被包含。
must_not:: 查询指定文档一定不要被包含。
should:: 查询指定文档,有则可以为文档相关性加分。
(6)wildcards 查询
使用标准的shell通配符查询
POST /index/doc/_search
{
"query": {
"wildcard": {
"content": "中*"
}
}
}(7)regexp查询
使用regexp查询能够让你写下更复杂的模式(中文只能匹配单个字开头)
POST /index/doc/_search
{
"query": {
"regexp": {
"content": "中.*"
}
}
}(8)prefix查询
以什么字符开头的,可以更简单地用 prefix
POST /index/doc/_search
{
"query": {
"prefix": {
"content": "中"
}
}
}参考:
http://blog.csdn.net/dm_vincent/article/details/41720193
http://www.cnblogs.com/ghj1976/p/5293250.html
4.Mapping
什么是mapping
ES的mapping非常类似于静态语言中的数据类型:声明一个变量为int类型的变量, 以后这个变量都只能存储int类型的数据。同样的, 一个number类型的mapping字段只能存储number类型的数据。
同语言的数据类型相比,mapping还有一些其他的含义,mapping不仅告诉ES一个field中是什么类型的值, 它还告诉ES如何索引数据以及数据是否能被搜索到。

剖析mapping
一个mapping由一个或多个analyzer组成, 一个analyzer又由一个或多个filter组成的。当ES索引文档的时候,它把字段中的内容传递给相应的analyzer,analyzer再传递给各自的filters。
filter的功能很容易理解:一个filter就是一个转换数据的方法, 输入一个字符串,这个方法返回另一个字符串,比如一个将字符串转为小写的方法就是一个filter很好的例子。
一个analyzer由一组顺序排列的filter组成,执行分析的过程就是按顺序一个filter一个filter依次调用, ES存储和索引最后得到的结果。
总结来说, mapping的作用就是执行一系列的指令将输入的数据转成可搜索的索引项。
默认analyzer
回到我们的例子, ES猜测description字段是string类型,于是默认创建一个string类型的mapping,它使用默认的全局analyzer, 默认的analyzer是标准analyzer, 这个标准analyzer有三个filter:token filter, lowercase filter和stop token filter。
(1)新增
PUSH /libray/books
{
"settings" : {
"number_of_shards" : 2,
"number_of_replicas" : 1
},
"mappings" : {
"books" : {
"properties" : {
"name" : {
"type": "string",
"index": "not_analyzed"
},
"year" : {
"type" : "integer"
},
"detail" : {
"type" : "string"
}
}
}
}
}(2)删除索引中所有映射
DELETE /libray/_mapping(3)删除指定映射索引
DELETE /libray/_mapping/books参考
http://m.blog.csdn.net/lilongsheng1125/article/details/53862629
5.查询补充
(1).source filter 限制返回字段
_source检索设置为false参数关闭检索
GET /_search
{
"_source": "obj.*, obj2.*",
"query" : {
"match_all" : {}
}
}
complete control
GET /_search
{
"_source": {
"includes": [ "obj1.*", "obj2.*" ],
"excludes": [ "*.description" ]
},
"query" : {
"term" : { "user" : "kimchy" }
}
}
(2)sort排序
POST /bank/_search
{
"query": {
"match_all" : {}
},
"sort" : [
{
"age" : "asc"
}
]
}
分类模式选项编辑
Elasticsearch支持按数组或多值字段进行排序。该mode选项控制选择哪个数组值来排序它所属的文档。该mode选项可以具有以下值:
|
|
选择最低的价值。 |
|
|
选择最高的价值。 |
|
|
使用所有值的总和作为排序值。仅适用于基于数字的数组字段。 |
|
|
使用所有值的平均值作为排序值。仅适用于基于数字的数组字段。 |
|
|
使用所有值的中位数作为排序值。仅适用于基于数字的数组字段。 |
(3)Post Filter 后置过滤器
用于过滤搜索结果和聚合的过滤器,post_filter元素是一个顶层元素,只会对搜索结果进行过滤。
GET /cars/transactions/_search?search_type=count
{
"query": {
"match": {
"make": "ford"
}
},
"post_filter": {
"term" : {
"color" : "green"
}
},
"aggs" : {
"all_colors": {
"terms" : { "field" : "color" }
}
}
}(4)explain
对每个命中的分数进行解释。
GET /bank/_search
{
"explain" : true,
"query": {
"bool" : {
"filter" : {
"term" : {
"age" : 39
}
}
}
}
}(5)version
为每个搜索命中返回一个版本。
GET /bank/_search
{
"version": true,
"query": {
"bool" : {
"filter" : {
"term" : {
"age" : 39
}
}
}
}
}(6)min_score
排除_score小于以下指定最小值的文档min_score
GET /_search
{
"min_score": 0.5,
"query" : {
"term" : { "user" : "kimchy" }
}
}
(7)inner_hits
返回父文档,也返回匹配has-child条件的子文档,相当于在父子之间join
例子:假设我们使用父文档存储邮件内容,子文档存储每个邮件拥有者的信息以及对于此用户这封邮件的状态。搜索某个账户的邮件列表时,我们希望搜索到邮件内容和邮件状态,可以设想假如没有Inner-hits,我们必须得分两次查询,因为邮件内容和邮件状态分别存放在父文档和子文档中。而有了Inner_hits属性后,我们可以使用一次查询完成。
curl -XGET 'http://localhost:9200/hermes/email/_search/?pretty=true' -d '{
"query": {
"has_child": {
"type": "email_owner",
"query": {
"bool": {
"must": [
{ "term": { "owner": "[email protected]" } },
{"term": {"labelId": "1"} }
]}
},
//注意此处
"inner_hits": {}
}
}
}'
(8)mget批量查询
如果一次性要查询多条数据的话,那么一定要用batch批量操作的api,尽可能减少网络开销次数,可能可以将性能提升数倍,甚至数十倍。
POST http://localhost:9200/bank/_mget
{
"docs" : [
{
"_type" : "accout",
"_id" : 1
},{
"_type" : "accout",
"_id" : 2
}]
}五、补充
强烈推荐:
Elasticsearch5.2核心知识篇 http://www.jianshu.com/nb/13767185
Elasticsearch5.2高手进阶篇 http://www.jianshu.com/nb/14337815
分词器
es 默认分词器原理:中文以单个字为单位进行分词,英文以空格或者标点为单位进行分词。
match与term http://blog.csdn.net/yangwenbo214/article/details/54142786
倒排索引
可参考 http://blog.csdn.net/wang_zhenwei/article/details/52831992
http://www.jianshu.com/p/ed7e1ebb2fb7
filters特性 http://www.cnblogs.com/bmaker/p/5480006.html
过滤查询以及聚合 http://blog.csdn.net/dm_vincent/article/details/42757519
_all http://blog.csdn.net/jiao_fuyou/article/details/49800969
Elasticsearch 字段数据类型 :
http://www.jianshu.com/p/ab99d2bcd63d