目录
一、数据库概述
数据库(DataBase,DB):是指长期保存在计算机的存储设备上,按照一定规则阻止起来,可以被各种用户或应用共享的数据集合。(文件系统)
数据库管理系统(DataBaseManagement System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中的数据。
数据库管理系统是一个软件,可以创建和操作数据库,而数据库中一般会创建多个表,表则是用于保存程序中需要的数据。三者的关系如下图所示,

数据是以记录的形式存储在表中的,具体存储格式如下图所示,

其中列名id、name、age等代表字段,每一行代表的是一条记录,也就是对象的数据。
二、数据库的安装与配置
我们安装的DBMS为mysql,安装教程参考链接:https://blog.csdn.net/weixin_39478524/article/details/114365222
打开cmd,登录sql指令为,
mysql -u root -p password(password为设置的密码)如果忘记了密码也可以修改密码,
- 运行(win+R)输入:services.msc,停止mysql服务;或者cmd --> net stop mysql
- 在cmd下 输入:mysqld --skip-grant-tables,启动服务器,光标不动(不要关闭该窗口)
- 新打开cmd输入:mysql -u root -p 不需要密码,接着依次输入use mysql; update user set password=password('重置的密码') WHERE User='root';
- 关闭两个cmd窗口,在任务管理器结束mysqld进程
- 在服务管理页面,重启mysql服务
三、sql概述
sql(结构化查询语言)是用于定义和操作数据,维护数据的完整性和安全性,以及进行各种数据库的管理等,
结构化查询语言SQL主要具有以下优点:
- 通用性强:不是某个特定数据库供应商专有的语言。几乎所有重要的数据库管理系统都支持SQL。
- 简单易学:该语言的语句都是由描述性很强的英语单词组成,且这些单词的数目不多。
- 高度非过程化:即用SQL操作数据库,只需指出“做什么”,无须指明“怎么做”,存取路径的选择和操作的执行由DBMS自动完成。
四、sql分类
sql主要分为四类:
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等。
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据)。
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别。
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)。
注意:sql语句以分号";"结尾
4.1 DDL
数据定义语言(DDL)用于操作数据库、表和列等,使用到的关键字一般有CREATE、ALTER、DROP
4.1.1操作数据库
首先我们创建一个数据库,
create database mydb1;--创建名为mydb1数据库
Create database mydb2 character set gbk;--创建名为mydb2数据库,并指定字符集为gbk
Create database mydb3 character set gbk COLLATE gbk_chinese_ci;--创建名为mydb3数据库,指定字符集为gbk,并带校对规则然后查询创建的数据库,
show create database mydb1;--显示创建的数据库mydb1修改创建的数据库使用的字符集,
alter database mydb2 character set utf8;//修改mydb2数据库字符集为utf8删除数据库,
drop database mydb3;//删除数据库mydb3还可以查看当前使用的数据库和切换数据库,
select database();//查看当前使用的数据库
use mydb2;//切换数据库为mydb24.1.2操作数据表
首先我们用create语句创建一个数据表,
create table 表名(
字段1 字段类型,
字段2 字段类型,
...
字段n 字段类型
);
在数据库中常用的数据类型如下:
- int:整型
- double:浮点型;例如double(5,2)表示浮点数最多5位,其中必须有2位小数,即最大值为999.99
- char:固定长度字符串类型;char(10)代表十个字符长度的字符串,不足的用空字符代替,例如'abc '
- varchar:可变长度字符串类型;varchar(10)代表十个字符长度的字符串,可以不足规定长度,例如'abc'
- text:文本字符串类型,一般存大数据的文本
- blob:字节类型,二进制大对象,一般用于存储图片视频音频文件
- date:日期类型,格式为:yyyy-MM-dd
- time:时间类型,格式为:hh:mm:ss
- timestamp:时间戳类型yyyy-MM-dd hh:mm:ss,会自动赋值
- datetime:日期时间类型yyyy-MM-dd hh:mm:ss
比如我们创建一个员工表:
create table employee(
id int,
name varchar(50),
gender varchar(10),
birthday date,
entry_date date,
job varchar(100),
salary double,
resume varchar(200)
);然后我们通过show命令查看数据库中的所有表,
show tables;//查看数据库中的所有表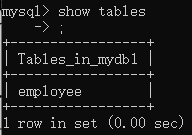
我们还可以查看、修改和删除表的字段信息,
DESC employee;//查看表的字段信息
ALTER TABLE employee ADD image blob;//添加一个image列,类型为blob
ALTER TABLE employee MODIFY job varchar(60);//修改job列字符最大长度为60
ALTER TABLE employee DROP image;//删除image列
RENAME TABLE employee TO user;//修改表名
SHOW CREATE TABLE user;//查看表格的创建细节
ALTER TABLE user CHARACTER SET gbk;//修改表的字符集为gbk
ALTER TABLE user CHANGE name username varchar(100);//列名name修改为username
DROP TABLE user;//删除表4.2 DML
数据操作语言(DML)一般用于操作表中的数据,对表中的数据进行增删改查,常用的关键字为INSERT、UPDATE、DELETE等
注意:(1)在mysql中,字符串类型和日期类型都要用单引号括起来:'DML'、'2021-03-05'。(2)空值用null表示
4.2.1插入操作:INSERT
插入操作可以向表中插入数据,格式如下:
INSERT INTO 表名(列名1,列名2,...) VALUES(列值1,列值2,...);//插入单条数据
INSERT INTO 表名 VALUES(数据1的属性列表值),(数据2的属性列表值),...;//插入多条数据需要注意的是:
- 列名与列值的类型、个数、顺序要一一对应
- 可以把列名当做java中的形参,把列值当做实参
- 值不要超出列定义的长度
-
如果插入空值,请使用null
-
插入的日期和字符一样,都使用引号括起来
我们测试一下向employee表中插入一条数据,
INSERT INTO employee(id,name,gender,birthday,entry_date,job,salary,resume) VALUES(12345,'TESTNAME','MALE','2021-03-04','2021-03-05','CODER','300','BLABLA');使用SELECT语句查询表中的数据,
SELECT * FROM employee;
4.2.2修改操作:UPDATE
修改操作是用于修改表格中的数据,语法格式为:
UPDATE 表名 SET 列名1=列值1,列名2=列值2,... WHERE 列名=值//修改列名=值的所有数据比如我们将姓名为TESTNAME的员工salary修改为1000元,job改为老板,
UPDATE employee SET salary=1000,job='boss' WHERE name='TESTNAME';然后查看一下修改后的数据,

4.2.3删除操作
删除操作用于删除表格中的数据,语法格式为:
DELETE FROM 表名 WHERE 列名=值;//删除列名=值的所有数据
DELETE FROM 表名;//删除表名中的所有数据
TRUNCATE TABLE 表名;//先把表删除,再重新创建一个新表,删除的数据不可以找回我们测试一下删除job为boss的数据,
DELETE FROM employee WHERE job='boss';
4.3 DQL操作
数据查询语言(DQL)一般用于查询数据,常用关键字为SELECT,
执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端,返回的结果集是一张虚拟表,
查询的基本格式为:
SELECT 列名 FROM 表名
WHERE ...
GROUP BY ...
HAVING ...
ORDER BY ...
LIMIT ...
查询语句书写顺序为:select - from - where - group by - having - order by - limit
查询语句执行顺序为:from - where - group by - having - select - order by - limit
下面我们一一进行介绍:
4.3.1基础查询
- SELECT selection_list:要查询显示的列名称
- 例:select name from employee,显示employee表中的name列数据值
- 例:select * from employee,显示employee表中所有列的数据值
- FROM table_list:要查询的表名称
- select * from employee,user,显示employee表和user表中的所有数据值
- 注意:查询时是将每个表中的x条记录与另一个表y条记录组成结果,组成的结果的记录条数为x*y(笛卡尔积)
- 如果employee有m条记录,user有n条记录,最后多表查询结果为m*n条记录
4.3.2条件查询
条件查询主要用到了where关键字,后面跟的是条件判断语句,
- WHERE condition:行条件
- 基于值:
- where 字段 = 值:查找出对应字段等于对应值的记录。(相似的,=可以替换为<、<=、>、>=、!=)例如:where name='lilei'
- where 字段 like 值:功能与 = 相似 ,但可以使用模糊匹配来查找结果。例如:where name like 'li%',查找姓为li的所有名字
- 基于值的范围:
- where 字段 in 范围:查找出对应字段的值在所指定范围的记录。例如:where age in (18,19,20)
- where 字段 not in 范围:查找出对应字段的值不在所指定范围的记录。例如:where age not in (18,19,20)
- where 字段 between x and y:查找出对应字段的值在闭区间[x,y]范围的记录。例如:where age between 18 and 20
- 复合条件:
- where 条件1 or 条件2…:查找出符合条件1或符合条件2的记录
- where 条件1 and 条件2…:查找出符合条件1并且符合条件2的记录
- where not 条件1:查找出不符合条件1的所有记录
- &&的功能与and相同,||与or功能类似,!与not 功能类似
- 基于值:
- HAVING condition:行条件
- having和where的功能类似,用于对查询结果的过滤。
- having的条件判断只能用于数据在内存中的情况,如果没有select该字段数据,就无法使用having进行条件判断
- 例:select name,gender from employee having gender='MALE';//可以,因为gender字段被select到内存中存储了
4.3.3模糊查询
模糊查询需要使用关键字LIKE,主要用到了以下几个通配符,
- “_”:任意一个字符
- select * from employee where name like '_____';//查找名字字符为5个的职员信息
- “%”:任意0~n个字符
- select * from employee where name like 'z%';//查询名字字符以z开头的职员信息
- [charlist]:字符列中的任何单一字符
- select * from user where address like '[BS]%';//查询居住城市以B或者S开头的用户信息
-
[^charlist]或者[!charlist]:不在字符列中的任何单一字符
-
select * from user where address like '[!BS]%';//查询居住城市不以B或者S开头的用户信息
-
4.3.4字段控制查询
- DISTINCT:当查询得到的数据有重复记录时,我们可以用DISTINCT去除重复记录
- select distinct salary from employee;//查询员工的工资段
- IFNULL:如果查询的数据为null,我们对null数据进行运算结果也会得到null,这时可以用IFNULL判断是否为空,是则替换为0
- select salary+IFNULL(bonus,0) from employee where name='zhangsan';//查询张三员工的工资加奖金有多少,奖金若为null就赋值0
- AS:给查询的数据起别名可以用AS关键字
- select salary+IFNULL(bonus,0) as total from employee where name='zhangsan';//查询张三员工的总共工资有多少,以列名为total显示
4.3.5排序查询
order by是用来写在where之后,给多个字段来排序的一个DQL查询语句。asc为升序(默认方式可省略),desc降序。
- ORDER BY sorting_columns:对结果某列按顺序排列
- 其语法为:select 字段列表 from 表名 where 条件 order by 字段名1 asc/desc,字段名2 asc/desc,...
- 写在前面的字段,优先级最高,往后依次递减。排序的时候优先看前面的规则,相同时看后面的规则。
- select from employee order by salary DESC,
- 其语法为:select 字段列表 from 表名 where 条件 order by 字段名1 asc/desc,字段名2 asc/desc,...
4.3.6分组查询与聚合函数
分组查询是按照某个属性的类别来查询数据,用到的关键字为GROUP BY
- select * from employee group by job;//根据工种不同分类显示员工信息
分组查询一般会结合聚合函数一起使用,聚合函数可以统计信息,SQL常见的聚合函数如下:
- count(x):统计每组的记录数
- select gender,count(gender) from user group by gender;//统计每个性别分别有多少人
- max(x):统计最大值,x是字段名
- select name,max(salary) from employee group by gender;//统计男女生中工资最高的分别是谁
- min(x):统计最小值,x是字段名
- select name,min(salary) from employee group by gender;//统计男女生中工资最低的分别是谁
- avg(x):统计平均值,x是字段名
- select gender,avg(salary) from employee group by gender;//统计男女的平均工资分别为多少
- sum(x):统计总和,x是字段名
- select gender,sum(salary) from employee group by gender;//统计男女的总共工资为多少
4.3.7LIMIT
LIMIT用来限定查询结果的起始行,以及总行数
- LIMIT offset_start, row_count:结果限定
- select * from employee limit 0,5;//查询从第一行开始(起始下标为0)的5行信息
- select * from employee limit 3,10;//查询从第四行开始的10行信息
五、数据的完整性
数据的完整性是保证用户输入的数据保存到数据库中是正确的,
我们一般会在创建表时给表中添加约束,完整性的分类一般包括:实体完整性、域完整性和引用完整性。
5.1实体完整性
实体:指的是表中的一行记录,每一行记录代表的是一个实体。
实体完整性的作用在于保证每一行数据不重复,实体约束类型包括:
- 主键约束(primary key)
- 唯一约束(unique)
- 自动增长列(auto_increment)
5.1.1主键约束
主键是用来唯一确定表中每一行数据的标识符,
每个表中都要有一个主键,其特点为数据唯一、不允许重复,且不能为空null,
创建主键需要用到关键字primary key,一般有三种创建方式:
--第一种
CREATE TABLE student(
id int primary key,
name varchar(50)
);
--第二种,可以创建联合主键
CREATE TABLE student(
id int,
name varchar(50),
primary key(id)
);
CREATE TABLE student(
classid int,
stuid int,
name varchar(50),
primary key(classid,stuid) --创建联合主键classid和stuid
);
--第三种
CREATE TABLE student(
id int,
name varchar(50)
);
ALTER TABLE student ADD PRIMARY KEY (id);
5.1.2唯一约束
唯一约束是指所有记录中字段的值不能重复出现,用关键字unique实现,
CREATE TABLE student(
Id int primary key,
Name varchar(50) unique --Name不允许重复出现
);
5.1.3自动增长列
自动增长列一般用于主键,并且主键列类型只能是整数类型,使用到的关键字为auto_increment,
设置自动增长列后不用手动设置该列的数据,会根据前面的数据进行自动增长,
CREATE TABLE student(
Id int primary key auto_increment,
Name varchar(50)
);
INSERT INTO student(name) values(‘tom’);--设置自动增长列后可以直接设置Name不给ID值,ID值会自动增长生成
5.2域完整性
域完整性是针对某一具体关系数据库的约束条件,保证表中的某些列不能输入无效的值,
域完整性指列的值域的完整性,如数据类型、格式、值域范围、是否允许空值等,
完整性约束包括:非空约束(not null)、默认值约束(default)和check约束,
其中check约束在mysql中并不支持,其约束格式为check(sex='MALE' or sex='FEMALE')
5.2.1非空约束
非空约束就是不允许数据给空值null,要求用户必须输入有效值,
非空约束的设置格式如下:
CREATE TABLE student(
Id int pirmary key,
Name varchar(50) not null,
Sex varchar(10)
);
INSERT INTO student values(1,’tom’,null);--不能给非空约束的Name字段赋值null,可以给sex字段赋值为null,因为sex字段没有非空约束5.2.2默认值约束
默认值约束就是给当前字段设置一个默认值,
如果在插入一条新纪录时没有给该字段赋值,那么系统就会自动为这个字段赋值为默认值,
设置默认值约束的格式如下:
CREATE TABLE student(
Id int pirmary key,
Name varchar(50) not null,
Sex varchar(10) default ‘男’
);
insert into student1 values(1,'tom','女');
insert into student1 values(2,'jerry',default);
5.3引用完整性(参照完整性)
外键:如果字段X在表A中是主关键字,在表B中不是主关键字,那么我们称字段X为表B的外键,
在mysql中,外键约束经常与主键约束一起使用。对于两个具有关联关系的表而言,相关联字段中主键所在的表就是主表(父表),外键所在的表就是从表(子表),
外键用来建立主表和从表的关联关系,为两个表的数据建立链接,约束两个表中数据的一致性和完整性。
--第一种添加外键方式
CREATE TABLE student(
sid int pirmary key,
name varchar(50) not null,
sex varchar(10) default ‘男’
);
CREATE TABLE score(
id int,
score int,
sid int , -- 外键列的数据类型一定要与主键的类型一致
CONSTRAINT fk_score_sid foreign key (sid) references student(id)
);
--第二种添加外键方式。
ALTER TABLE score1 ADD CONSTRAINT fk_stu_score FOREIGN KEY(sid) REFERENCES stu(id);
如果表已经存在了,可以修改表添加外键约束或者删除外键约束,
ALTER TABLE 表名 ADD CONSTRAINT 外键约束名 FOREIGN KEY(列名) REFERENCES 主表名(列名);--添加外键约束
ALTER TABLE 表名 DROP FOREIGN KEY 外键约束名;--删除外键约束- 外键约束对子表如此检查处理:
- 在子表上进行INSERT、UPDATE操作的限制是,要和主表中的主键值匹配,或为NULL, 否则不允许。
- 外键约束对父表如此检查处理:
- 在父表_上进行UPDATE、DELETE操作的限制,取决于在定义子表的外键时指定的ON UPDATE、ON DELETE子句
- ON DELETE各选项的作用:
- No ACTION或RESTRICT:删除主表记录时,如果子表中有和主表匹配的记录,则不允许(产生一个错误提示),此为默认操作。
- CASCADE (级联):删除主表记录时,也将删除子表中的匹配记录。
- SET NULL:删除主表记录时,将子表中的匹配记录的外键值改为NULL。
- SET DEFAULT:删除主表记录时,将子表中的匹配记录的外键值改为默认值。
- ON UPDATE各选项作用:
- No ACTION或RESTRICT:更新主表记录时,如果子表中有和主表匹配的记录,则不允许(产生一个错误提示),此为默认操作。
- CASCADE (级联):更新主表记录时,也将更新子表中的匹配记录。
- SET NULL:更新主表记录时,将子表中的匹配记录的外键值改为NULL。
- SET DEFAULT:更新主表记录时,将子表中的匹配记录的外键值改为默认值。
- ON DELETE各选项的作用:
- 在父表_上进行UPDATE、DELETE操作的限制,取决于在定义子表的外键时指定的ON UPDATE、ON DELETE子句
六、多表查询
多表查询分为以下几种:
- 合并结果集:UNION、UNION ALL
- 连接查询
- 内连接:[INNER] JOIN ON
- 外连接:OUTER JOIN ON
- 左外连接:LEFT [OUTER] JOIN
- 右外连接:RIGHT [OUTER] JOIN
- 全外连接:(mysql不支持)FULL JOIN
- 自然连接:NATURAL JOIN
- 子查询
6.1合并结果集
合并结果集就是将两个select语句的查询结果合并到一起,有两种方式:
- UNION:去除重复记录。例如:SELECT * FROM table1 UNION SELECT * FROM table2;
- UNION ALL:不去除重复记录。例如:SELECT * FROM table1 UNION ALL SELECT * FROM table2;
6.2连接查询
连接查询就是求出多个表的乘积,例如t1连接t2,那么查询出来的结果就是t1*t2,
假设集合t1={a,b},集合t2={0,1,2},则两个集合的笛卡尔积t1*t2为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)},
有时候我们并不需要这么多结果显示,比如我们在查询员工表的时候,连接部门信息表想显示员工属于哪个部门的,
select * from empployee,dept where employee.deptno=dept.deptno;这样显示出来的信息都是有用的信息,而不会显示一大堆无用信息,
还可以给表指定别名,在使用的时候用别名即可,
select * from employee as e,dept as d where e.deptno=d.deptno;6.2.1内连接
内连接也称为等值连接,返回两张表都满足条件的部分,
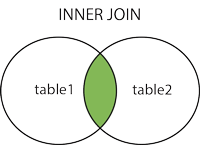
内连接使用inner join on表示,格式如下:
select <select list> from A [innner] join B on A.id=B.id;--其中inner可以省略6.2.2左连接
左连接属于外连接,取左边的表的全部,右边的表按条件选择,符合的显示,不符合则显示null,
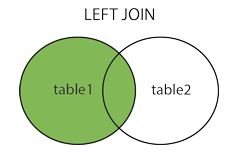
左连接使用left join on表示,格式如下:
select <select list> from A left [outer] join B on A.id=B.id;--outer可以省略6.2.3右连接
右连接也属于外连接,取右边的表的全部,左边的表按条件,符合的显示,不符合则显示null,
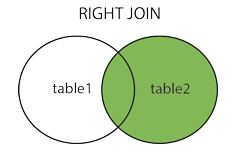
右连接使用right join on表示,格式如下:
select <select list> from A right [outer] join B on A.id=B.id;--outer可以省略6.2.4自然连接
自然连接自动判断相同名称的列,而后形成匹配。
缺点是,虽然可以指定查询结果包括哪些列,但不能人为地指定哪些列被匹配。
另外,自然连接的一个特点是连接后的结果表中匹配的列只有一个,
select * from employee natural join dept;--自然连接employee表和dept表,查找列名和类型相同的6.3子查询
子查询就是嵌套查询,即SELECT中包含SELECT,
如果一条语句中存在两个,或两个以上SELECT,那么就是子查询语句了,
- 子查询出现的位置
- where之后:作为查询条件的一部分
- from之后:作为表
例如:
select * from employee where salary > (selcet salary from employee where name='Bob');--查询比Bob工资高的员工信息
select e.empname,d.deptname from employee e,(select deptname,deptno from dept) d where e.deptno=d.deptno;--查询员工姓名和员工所属部门的名字- 当子查询出现在where后作为条件时,可以使用any和all关键字
- any:相当于和结果集中的任一一个作比较、若满足则返回
- all:相当于和结果集中的所有结果作比较,若满足则返回
例如:
select * from employee where salary > all (select salary from employee where deptno=5);--查询工资高于5部门所有人的员工信息
select * from employee where salary > any (select salary from employee where deptno=5);--查询工资高于5部门最低工资的员工信息- 子查询结果集形式
- 单行单列,用作条件
- 单行多列,用作条件
- 多行单列,用作条件
- 多行多列,用作表
七、mysql函数
7.1时间日期函数
| 函数 | 描述 |
| ADDTIME (date2 ,time_interval ) |
将time_interval加到date2 |
| CURRENT_DATE ( ) |
当前日期 |
| CURRENT_TIME ( ) |
当前时间 |
| CURRENT_TIMESTAMP ( ) | 当前时间戳 |
| DATE (datetime ) |
返回datetime的日期部分 |
| DATE_ADD (date2 , INTERVAL d_value d_type ) |
在date2中加上日期或时间 |
| DATE_SUB (date2 , INTERVAL d_value d_type ) |
在date2上减去一个时间 |
| DATEDIFF (date1 ,date2 ) |
两个日期差 |
| NOW ( ) |
当前时间 |
| YEAR|Month|Day(datetime ) |
年月日 |
7.2字符串函数
| 函数 | 描述 |
| CHARSET(str) |
返回字串字符集 |
| CONCAT (string2 [,... ]) |
连接字串 |
| INSTR (string ,substring ) |
返回substring在string中出现的位置,没有返回0 |
| UCASE (string2 ) |
转换成大写 |
| LCASE (string2 ) |
转换成小写 |
| LEFT (string2 ,length ) |
从string2中的左边起取length个字符 |
| LENGTH (string ) |
string长度 |
| REPLACE (str ,search_str ,replace_str ) |
在str中用replace_str替换search_str |
| STRCMP (string1 ,string2 ) |
逐字符比较两字串大小, |
| SUBSTRING (str , position [,length ]) |
从str的position开始,取length个字符 |
| LTRIM (string2 ) RTRIM (string2 ) trim |
去除前端空格或后端空格 |
7.3数学函数
| 函数 | 描述 |
| ABS (number2 ) | 绝对值 |
| BIN (decimal_number ) | 十进制转二进制 |
| CEILING (number2 ) | 向上取整 |
| CONV(number2,from_base,to_base) | 进制转换 |
| FLOOR (number2 ) | 向下取整 |
| FORMAT (number,decimal_places ) | 保留小数位数 |
| HEX (DecimalNumber ) | 转十六进制 |
| LEAST (number , number2 [,..]) | 求最小值 |
| MOD (numerator ,denominator ) | 求余 |
| RAND([seed]) | 随机数 |
八、数据库的备份与恢复
8.1生成sql脚本
第一步我们先要导出数据生成sql脚本,
在控制台cmd使用mysqldump命令可以用来生成指定数据库的脚本文本,
但要注意,脚本文本中只包含数据库的内容,而不会存在创建数据库的语句!
所以在恢复数据时,还需要自已手动创建一个数据库之后再去恢复数据,
mysqldump –u用户名 –p密码 数据库名>生成的脚本文件路径8.2恢复数据
接着通过执行sql脚本来恢复数据,前提时要先创建数据库名,
执行sql脚本需要登录mysql,进入指定数据库,才可以执行sql脚本,
--第一种方式
SOURCE 脚本路径
--第二种方式
mysql -u用户名 -p密码 数据库名<脚本路径