特征工程
一.为什么需要特征工程?
因为“数据和特征决定机器学习的上限,而模型和算法只是逼近这个上限而已”,使用专业背景知识和技巧处理数据,使算法变得更好。
二.什么是特征工程
sklearn库用于做特征工程
pandas库用来做数据清洗、数据处理。
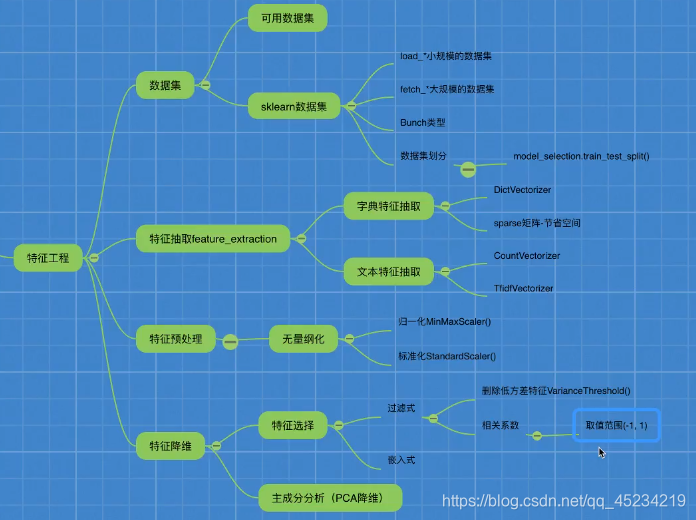
特征降维
定义:降低特征的个数(降低列数),得到一组“不相关”的主变量得过程
方法一:特征选择
1.Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间得关联
①方差选择法:低方差特征过滤
②相关系数法:衡量特征与特征之间的相关程度
2.Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)
①决策树:信息熵、信息增益
②正则化:L1、L2
③深度学习:卷积等
特征选择定义:数据中心包含冗余或相关变量,旨在原有特征中找出主要特征
1.Filter(过滤式)
①方差选择法:低方差特征过滤
原理:特征的方差小,说明某个特征的样本值比较相似,则删掉低方差特征;特征的方差大,说明某个特征的样本值差别大,则保留高方差特征。

②相关系数法



当特征与特征之间相关系数很高时:
(1)保留其中一个
(2)加权求和
(3)主成分分析
方法二:主成分分析(PCA)

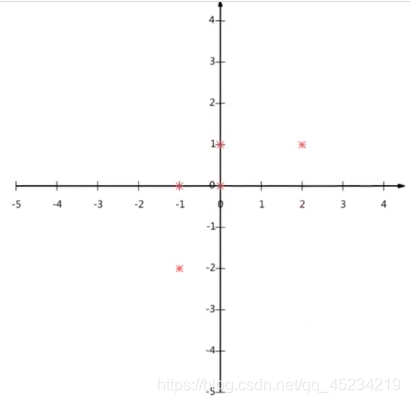
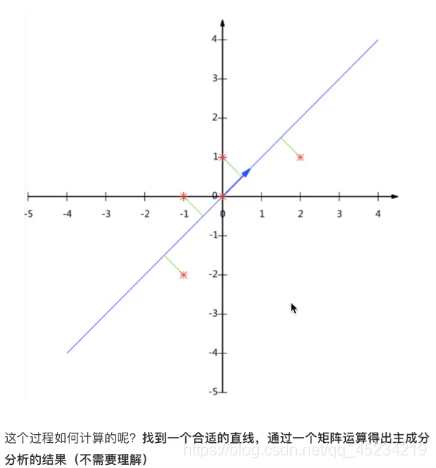
例如:给定五个点,画到明面直角坐标系中,是个二维的,我们使用主成分分析给降到一维:


案例:探究用户对物品类别的喜好细分降维

处理流程:

读取四个表:
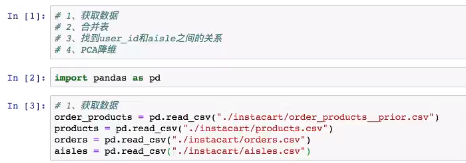
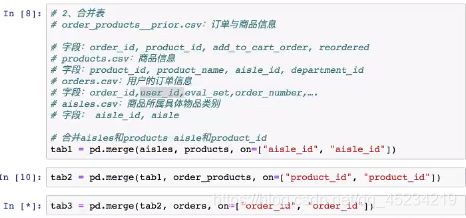
将ueser_id和aisle_id合并:
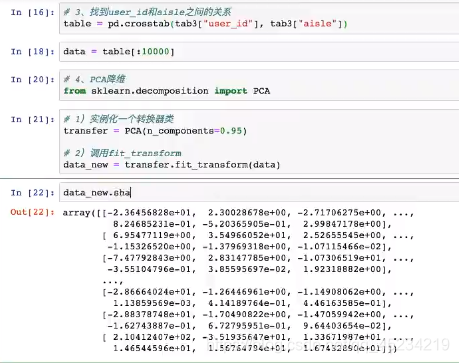
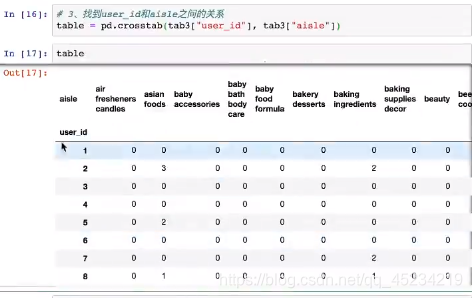
找到ueser_id和aisle_id之间的关系:
取前一万个数据。由于0太多了,冗余太多了,进行PCA降维: