前言
朋友请我帮忙爬一下知网的信息,答应之后准备尝试一下爬CNKI的论文,在爬知网前,google了一下网上有没有现成的知网爬虫(想偷了个懒),发现GitHub上的知网爬虫都是好几年前的,于是准备自己动手写一个。
正文
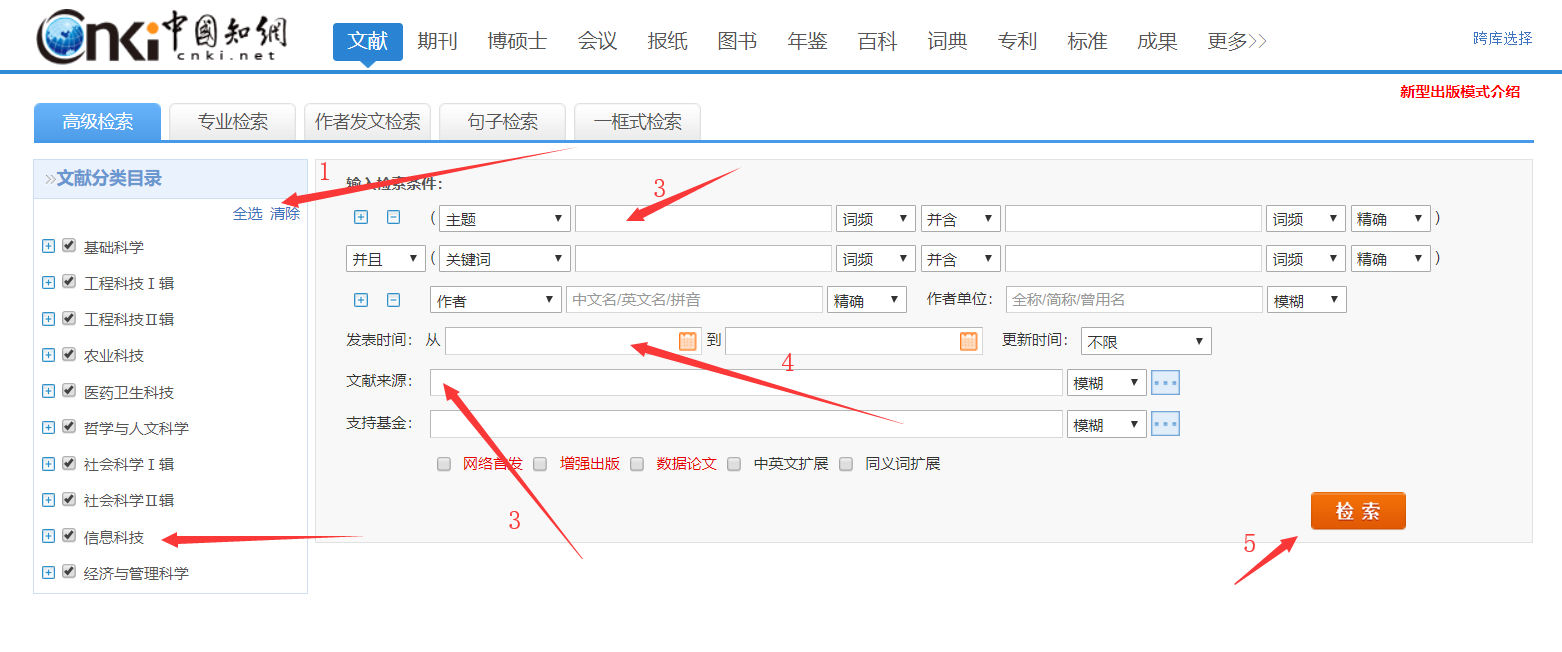
写爬虫的python工具:selenium,在模拟了浏览器行为(包括打开浏览器,打开知网检索页面,勾选左侧响应的栏目,输入关键词,设置检索时间段)之后,点击“检索”,获取浏览器的cookie值,然后再按F12,查看检索结果的url(可以直接按F12后,在前端页面里看到)。对了,知网确实有反爬虫机制,当写的脚本每一步直接操作过快之后,就会被断开连接,所以每一步交互操作之后,设一个time.sleep(),参数随机设吧,等待1,2,5秒不等,这样就不会被断开连接。
接下来,坑来了!
等我发现爬取的检索结果条目的前端页面里的URL 跟实际打开的URL不一样!下面截图里的URL是经过JS编码(说加密也行)过的,是在后台进行的,前端的脚本只能看到编码前的URL,直接访问会被链接到知网首页!网上那些说爬到了论文链接的人,也不试试能不能打开链接,就说爬到了URL,真逗。
所以想通过爬知网站内检索到论文的URL是不可能的。如果只是爬前端页面的论文名称和数据库,引用量,来源这些信息是可以的;但是想要通过爬取论文的URL,再爬论文的详细信息(摘要,机构,关键字,参考文献等)是行不通的。
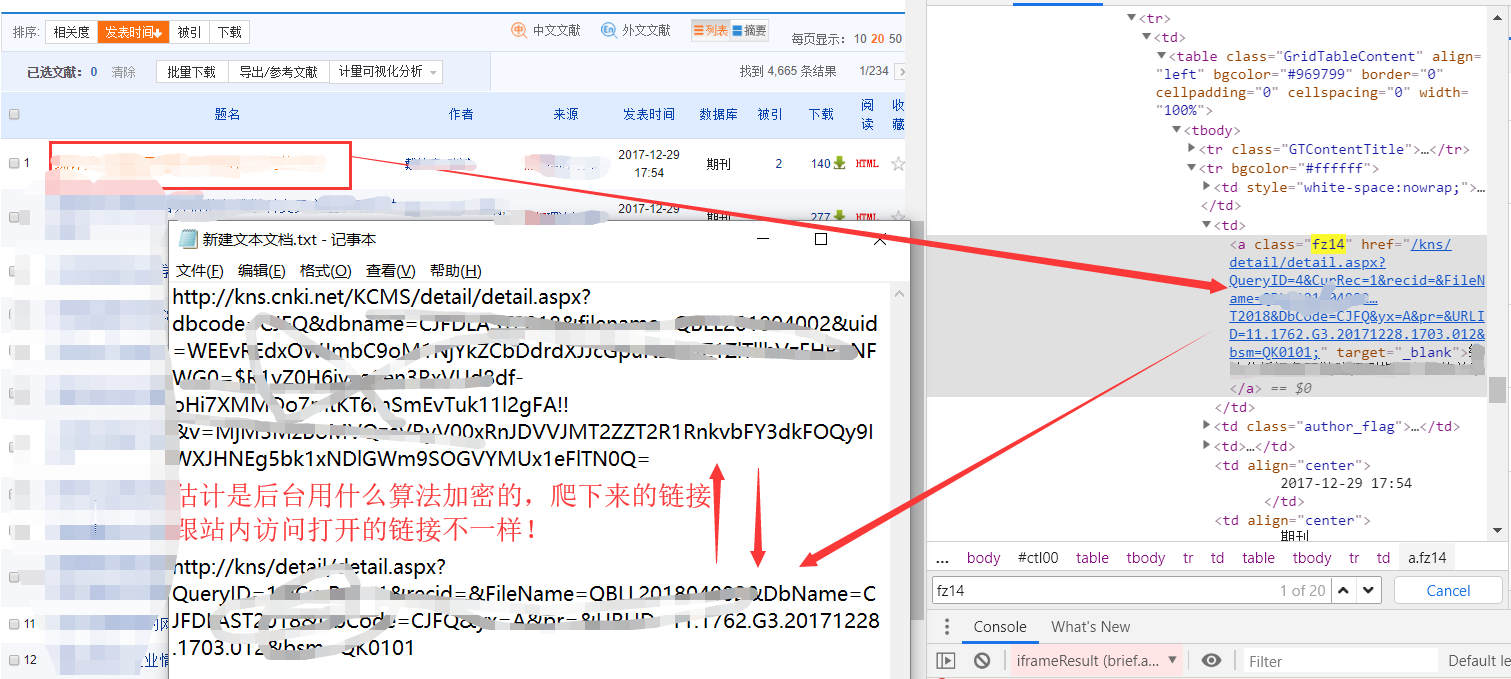
我猜这也是为什么只有人爬取知网前端的一些简单的信息(论文名,作者,来源,时间,引用量等),而不能深入的通过爬取知网检索论文的URL来爬取更多信息的原因吧。
希望大家不要浪费时间踩我踩过的坑了,如果有大神能填上我上面说的坑,请在回复评论我,咱可以交流一下。
整理不易...