矩阵、张量乘法(numpy.tensordot)的时间复杂度分析
文章目录
- Transformer的运行流程
- Transformer为何使用多头注意力机制?
- Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
- Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别
- ※ 为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
- 在计算attention score的时候如何对padding做mask操作?
- 为什么在进行多头注意力的时候需要对每个head进行降维(切割)?
- 大概讲一下Transformer的Encoder模块?
- 为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
- ※ 简单介绍一下Transformer的位置编码?有什么意义和优缺点?你还了解哪些关于位置编码的技术,各自的优缺点是什么?
- 简单讲一下Transformer中的残差结构以及意义。
- 为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
- 简答讲一下BatchNorm技术,以及它的优缺点。
- 简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
- Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
- Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
- Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
- 简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
- Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
- 引申一个关于bert问题,bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
Transformer的运行流程
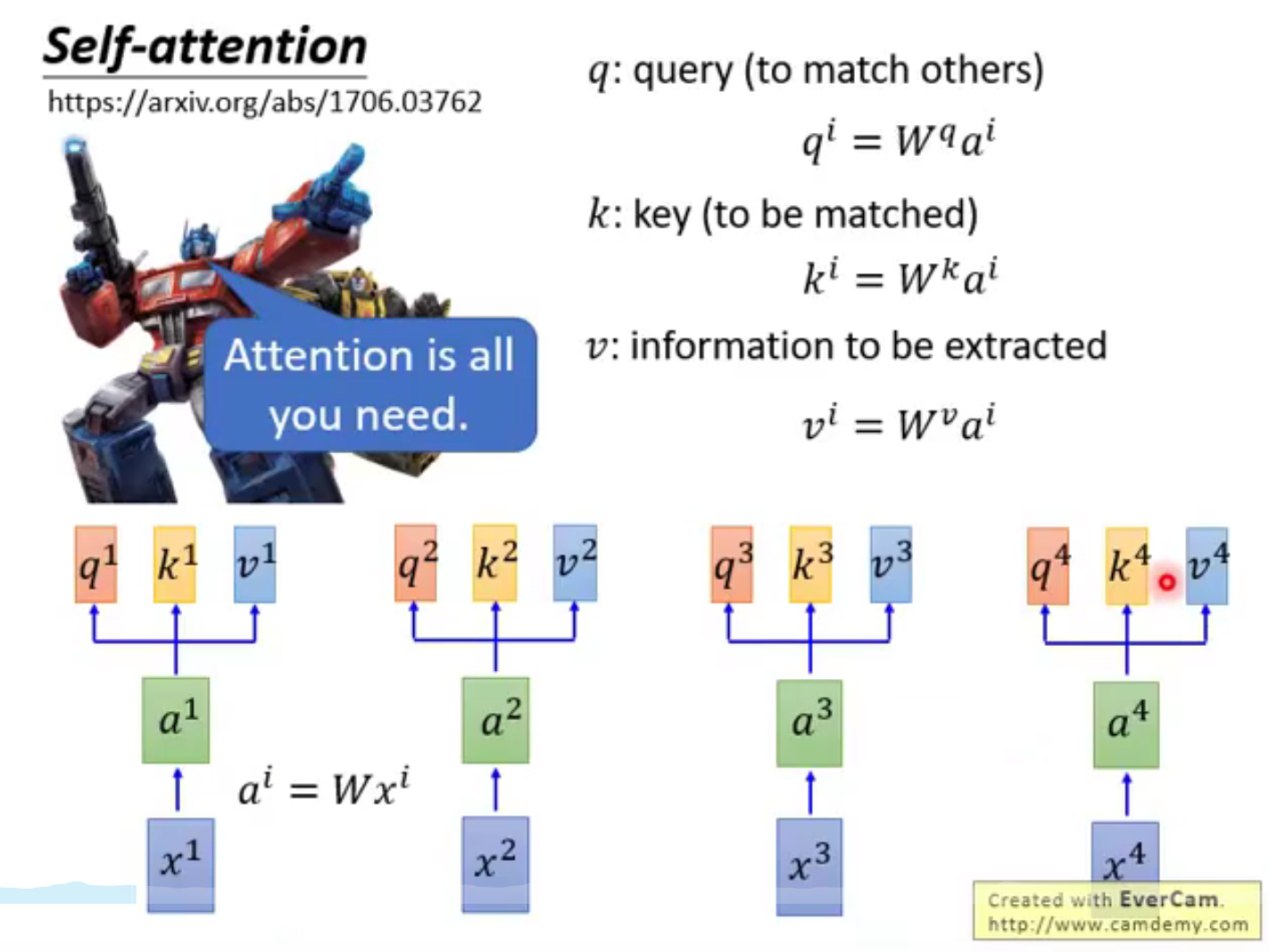
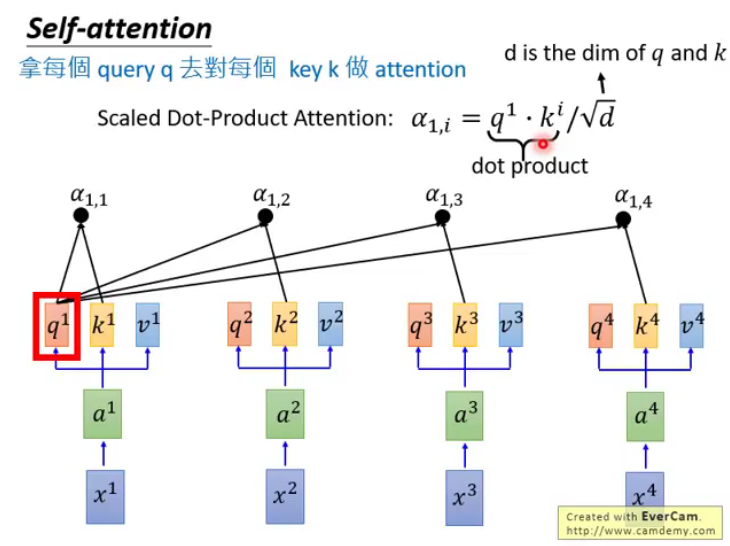
Transformer为何使用多头注意力机制?
- 从直觉上的解释,其实类似cnn中的多核,关注到不同子空间的信息,捕捉到更加丰富的特征信息
- 当然从代码实现上不是类似于cnn的多核,因为keyi, queryi 并没有去关注其他子空间j!=i的值
为什么Transformer 需要进行 Multi-head Attention?
What Does BERT Look At?An Analysis of BERT’s Attention.pdf
将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息
Transformer,或Bert的特定层是有独特的功能的,底层更偏向于关注语法,顶层更偏向于关注语义。
既然在同一层Transformer关注的方面是相同的,那么对该方面而言,不同的头关注点应该也是一样的。但是我们发现,同一层中,总有那么一两个头独一无二,和其他头的关注pattern不同,比如下图:
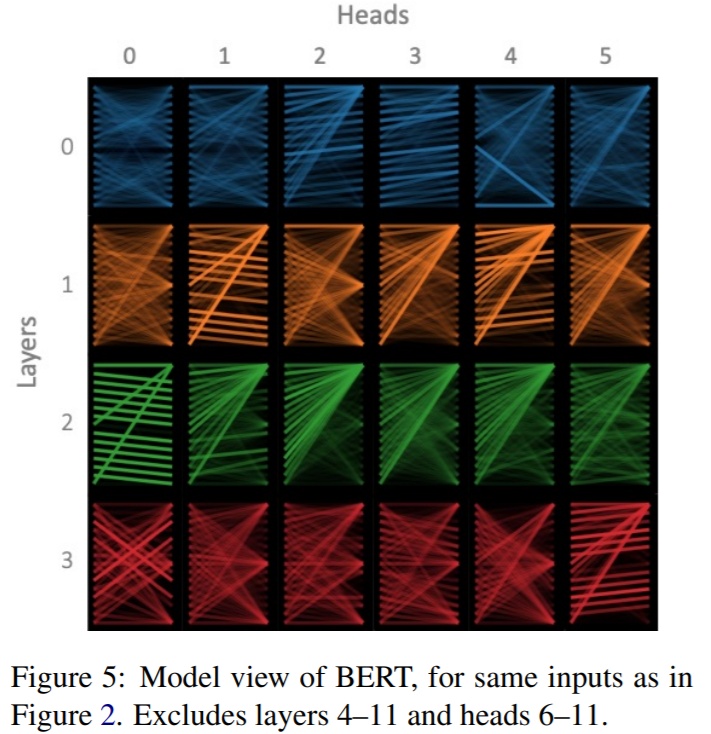

头之间的方差随着所在层数的增大而减小。
- 一种可能的解释是,它类似一种noise,或者dropout,而不是去关注不同的方面。也就是说,无论多少层,既然都会出现与众不同的头,那么这个(些)头就是去使得模型收敛(效果最优)的结果,反过来说,模型可能认为,全部一样的头不会使效果最优(至少在梯度下降的方法上)。这样的话,把这个(些)头解释为模型的一种“试探”,或者噪声,是可能合理的。
- 另外一种解释是,Transformer对初始化比较敏感,一些初始化点必然导致不同的头,但这样解释就很难从直觉上解释了。
- Transformer底层的头方差大是因为Transformer存在的梯度消失问题,也就是说,并不是模型自己觉得底层的方差大是好的,而是自己没有办法让它变好。所以,合理的初始化应该可以减少底层头的方差,提高效果。Improving Deep Transformerwith Depth-Scaled Initialization and Merged Attention
BLEU (其全称为Bilingual Evaluation Understudy), 其意思是双语评估替补

Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
transformer中为什么使用不同的K 和 Q, 为什么不能使用同一个值?
两个向量的点乘表示两个向量的相似度, 如果在同一个向量空间里进行点乘,理所应当的是自身和自身的相似度最大,那会影响其他向量对自己的作用,(形成类似单位矩阵?)
使用Q/K/V 不相同,保证在不同空间进行投影,增强表达能力,提高泛化能力
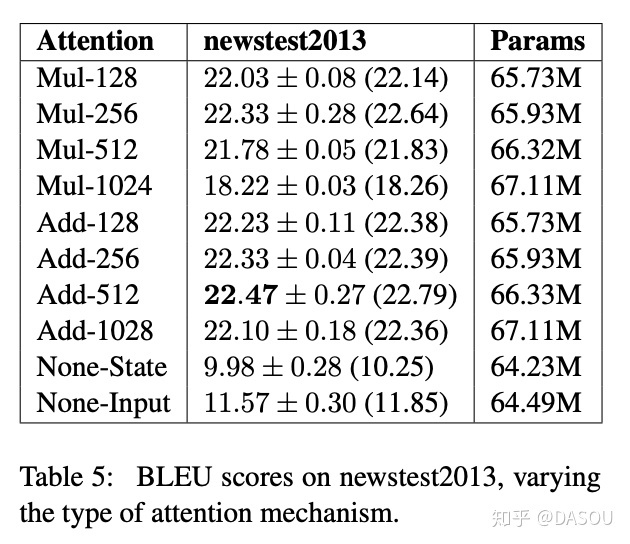
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别
答案解析:为了计算更快。矩阵加法在加法这一块的计算量确实简单,但是作为一个整体计算attention的时候相当于一个隐层,整体计算量和点积相似。在效果上来说,从实验分析,两者的效果和dk相关,dk越大,加法的效果越显著。更具体的结果,大家可以看一下实验图(从莲子同学那里看到的,专门去看了一下论文):
※ 为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
transformer中的attention为什么scaled?
D ( q ⋅ k d k ) = d k ( d k ) 2 = 1 D\left(\frac{q \cdot k}{\sqrt{d}_{k}}\right)=\frac{d_{k}}{\left(\sqrt{d}_{k}\right)^{2}}=1 D(dkq⋅k)=(dk)2dk=1
在计算attention score的时候如何对padding做mask操作?
padding位置置为负无穷(一般来说-1000就可以)。
为什么在进行多头注意力的时候需要对每个head进行降维(切割)?
transformer中multi-head attention中每个head为什么要进行降维?
在不增加时间复杂度的情况下,同时,借鉴CNN多核的思想,在更低的维度,在多个独立的特征空间,更容易学习到更丰富的特征信息。
Self-Attention时间复杂度: O ( n 2 d ) O(n^2 d) O(n2d),n是序列的长度,d是embedding的维度。
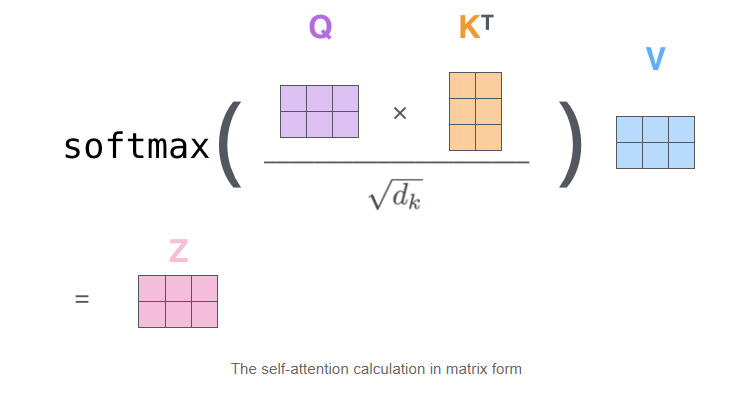
示例的序列长度:2;Embedding维度:3
相似度计算:看成 ( n , d ) × ( d , n ) (n,d)\times (d,n) (n,d)×(d,n)矩阵相乘,时间复杂度 O ( n 2 d ) O(n^2d) O(n2d),得到 ( n , n ) (n,n) (n,n)矩阵
softmax: O ( n 2 ) O(n^2) O(n2)
加权平均:看成 ( n , n ) × ( n , d ) (n,n)\times (n,d) (n,n)×(n,d)矩阵相乘,时间复杂度 O ( n 2 d ) O(n^2d) O(n2d)
因此:Self-Attention的时间复杂度是 O ( n 2 d ) O(n^2d) O(n2d)
假设有m个头,每个头a维, O ( n 2 ⋅ m ⋅ a ) = O ( n 2 ⋅ d ) O\left(n^{2} \cdot m \cdot a\right)=O\left(n^{2} \cdot d\right) O(n2⋅m⋅a)=O(n2⋅d)
大概讲一下Transformer的Encoder模块?
为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
※ 简单介绍一下Transformer的位置编码?有什么意义和优缺点?你还了解哪些关于位置编码的技术,各自的优缺点是什么?
因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。positional encoding的公式如下:
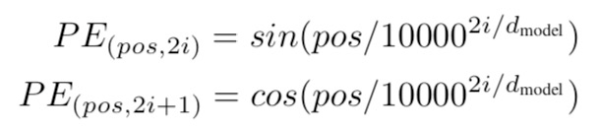
如何理解Transformer论文中的positional encoding,和三角函数有什么关系?