sklearn.ensemble._weight_boosting.BaseWeightBoosting.fit
for iboost in range(self.n_estimators):
# Boosting step
sample_weight, estimator_weight, estimator_error = self._boost(
iboost,
X, y,
sample_weight,
random_state)
sample_weight_sum = np.sum(sample_weight)
if iboost < self.n_estimators - 1:
# Normalize
sample_weight /= sample_weight_sum
sklearn.ensemble._weight_boosting.AdaBoostClassifier._boost_discrete
estimator.fit(X, y, sample_weight=sample_weight)
sample_weight就是 w m i w_{mi} wmi,根据样本权重进行拟合
# Instances incorrectly classified
incorrect = y_predict != y
# Error fraction
estimator_error = np.mean(
np.average(incorrect, weights=sample_weight, axis=0))
误分类率是误分类样本权重和: e m = ∑ i = 1 N w m i I ( G m ( x i ) ≠ y i ) e_m=\sum_{i=1}^{N}w_{mi}I(G_m(x_i)\neq y_i) em=∑i=1NwmiI(Gm(xi)=yi)
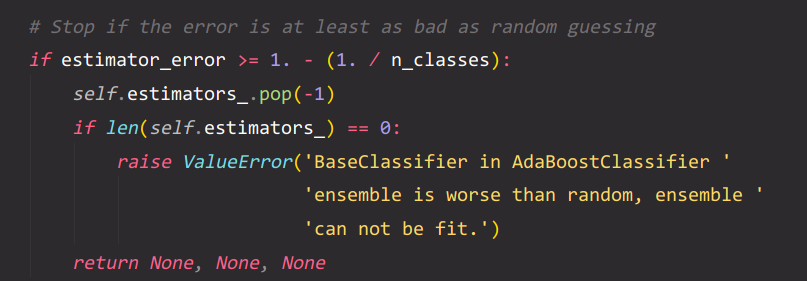
如果弱学习器的效果连随机都如不,早停。
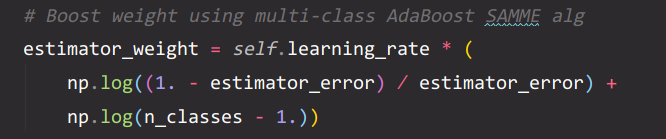
计算 G m G_m Gm的系数 α m = 1 2 l o g 1 − e m e m \alpha_m=\frac{1}{2}log\frac{1-e_m}{e_m} αm=21logem1−em
SAMME算法考虑了多分类,乘以learning_rate的衰减实现正则化。

w m i = e x p ( − y i α m − 1 G m − 1 ( x i ) ) w_{mi}=exp(-y_i \alpha_{m-1} G_{m-1}(x_i)) wmi=exp(−yiαm−1Gm−1(xi))
试想, y × y ^ y\times \hat{y} y×y^,二分类时只有二者不同时才为1
这么写其实也兼顾了多分类的情况。对于多分类其实只需要修改 α m \alpha_m αm也就是代码中的estimator_weight的计算而已。