数据库
1. 数据完整性
作用:保证用户输入的数据保存到数据库中是正确的。
确保数据的完整性 = 在创建表时给表中添加约束
完整性的分类:
- 实体完整性
- 域完整性
- 引用完整性
1.1 实体完整性
实体: 即表中的一行(一条记录)代表一个实体(entity)
实体完整性的作用:标识每一行数据不重复
约束类型: 主键约束(primary key) 唯一约束(unique) 自动增长列(auto_increment)
1.1.1 主键约束
注:每个表中要有一个主键。
特点:数据唯一,且不能为null
例子:
第一种添加方式:
CREATE TABLE student(
id int primary key,
name varchar(50)
);
第二种添加方式:
CREATE TABLE student(
id int,
name varchar(50),
primary key(id)
);
CREATE TABLE student(
classid int,
stuid int,
name varchar(50),
primary key(classid,stuid)
);
此种方式优势在于,可以创建联合主键
第三种方式:
CREATE TABLE student(
id int,
name varchar(50)
);
ALTER TABLE student ADD PRIMARY KEY (id);
1.1.2 唯一约束(unique):
特点: 数据不能重复
CREATE TABLE student(
Id int primary key,
Name varchar(50) unique
);
1.1.3
自动增长列(auto_increment)
这种用法只限于mysql,其他数据库略有不同
CREATE TABLE student(
Id int primary key auto_increment,
Name varchar(50)
);
INSERT INTO student(name) values(‘tom’);
1.2 域完整性
域完整性的作用:限制此单元格的数据正确,不对照此列的其它单元格比较
域代表当前单元格
域完整性约束:数据类型 非空约束(not null) 默认值约束(default)
check约束(mysql不支持)check(sex=‘男’ or sex=‘女’)
1.2.1 非空约束: not null
CREATE TABLE student(
Id int pirmary key,
Name varchar(50) not null,
Sex varchar(10)
);
INSERT INTO student values(1,’tom’,null);
1.2.2 默认值约束 default
CREATE TABLE student(
Id int pirmary key,
Name varchar(50) not null,
Sex varchar(10) default ‘男’
);
insert into student1 values(1,'tom','女');
insert into student1 values(2,'jerry',default);
1.3 引用完整性
外键约束(实际开发中基本上不会使用)
例:
CREATE TABLE student(
sid int pirmary key,
name varchar(50) not null,
sex varchar(10) default ‘男’
);
create table score(
id int,
score int,
sid int , -- 外键列的数据类型一定要与主键的类型一致
CONSTRAINT fk_score_sid foreign key (sid) references student(id)
);
第二种添加方式
ALTER TABLE score ADD CONSTRAINT fk_stu_score FOREIGN KEY(sid) REFERENCES stu(id);
外键会保证score中的数据是student表中sid这一列已经存在的值
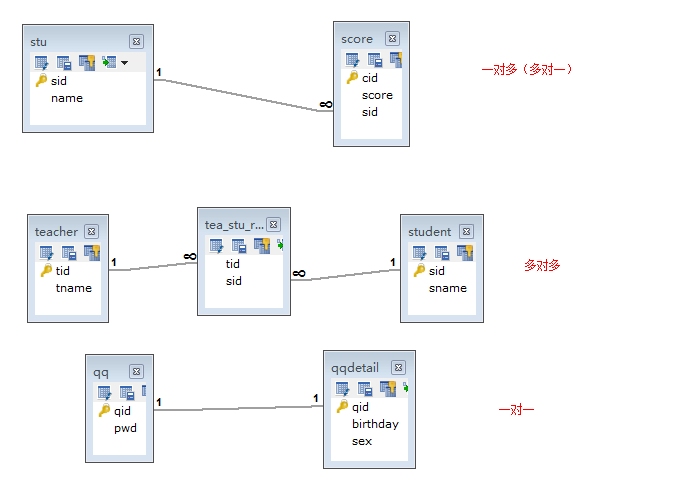
表与表之间的关系
- 一对一:例如t_person表和t_card表,即人和身份证。这种情况需要找出主从关系,即谁是主表,谁是从表。人可以没有身份证,但身份证必须要有人才行,所以人是主表,而身份证是从表。设计从表可以有两种方案:
- 在t_card表中添加外键列(相对t_user表),并且给外键添加唯一约束;
- 给t_card表的主键添加外键约束(相对t_user表),即t_card表的主键也是外键。
- 一对多(多对一):最为常见的就是一对多!一对多和多对一,这是从哪个角度去看得出来的。t_user和t_section的关系,从t_user来看就是一对多,而从t_section的角度来看就是多对一!这种情况都是在多方创建外键!
- 多对多:例如t_stu和t_teacher表,即一个学生可以有多个老师,而一个老师也可以有多个学生。这种情况通常需要创建中间表来处理多对多关系。例如再创建一张表t_stu_tea表,给出两个外键,一个相对t_stu表的外键,另一个相对t_teacher表的外键。
2. 多表查询
多表查询有如下几种:
- 合并结果集 UNION, UNION ALL
- 链接查询
- 内连接 [INNER] JOIN ON
- 外连接 OUTER JOIN ON
- 左外连接 LEFT [OUTER] JOIN
- 右外连接 RIGHT [OUTER] JOIN
- 全外连接(MySQL不支持)FULL JOIN
- 自然连接 NATURAL JOIN
- 子查询
2.1 合并结果集(很少很少使用)
- 作用:合并结果集就是把两个select语句的查询结果合并到一起!
- 合并结果集有两种方式:
- UNION:去除重复记录,例如:
SELECT * FROM t1 UNION SELECT * FROM t2; - UNION ALL:不去除重复记录,例如:
SELECT * FROM t1 UNION ALL SELECT * FROM t2。
- UNION:去除重复记录,例如:
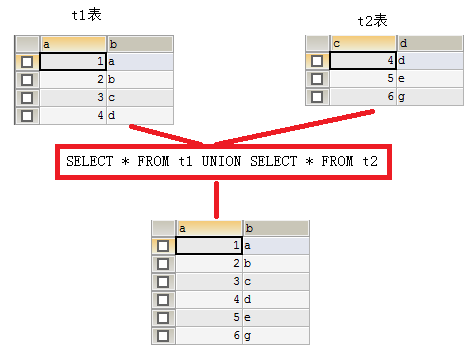
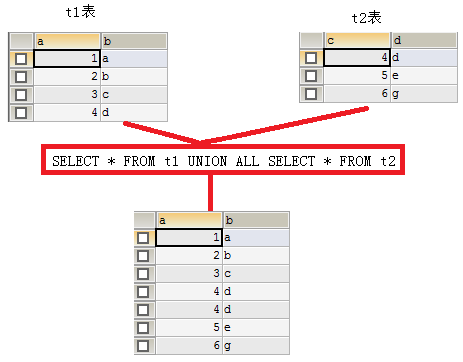
- 要求:被合并的两个结果:列数、列类型必须相同。
2.2 连接查询
2.2.0 交叉连接
既然是多表查询,那么我们先来看看两张非常简单的表,我们就以这两张表为例,进行演示。
student表
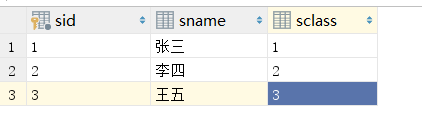
班级表
同时查询这两张表
select * from student,class;
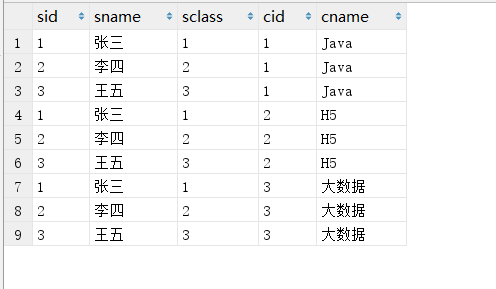
仔细观察查询出的数据,可以发现,当使用上图中的语句时,student表中的每一行记录,都与class表中的任意一条记录相关联,同样,class表中的每一行记录,都与student表中的任意一条记录相关联。即当我们有2张表时,交叉连接的效果如下:
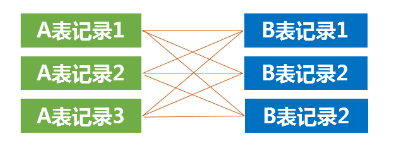
我们把上述"没有任何限制条件的连接方式"称之为"交叉连接","交叉连接"后得到的结果跟线性代数中的"笛卡尔乘积"一样。
笛卡尔积: 假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}。可以扩展到多个集合的情况
“交叉连接"的英文原文为"cross join”,被咱们翻译为交叉连接,其实,上述示例中的语句我们可以换一种写法,两种写法能够获取到相同的结果,示例如下
SELECT * FROM student CROSS JOIN class;
只不过在mysql中 我们可以简化为上述的写法
多表查询产生这样的结果并不是我们想要的,那么怎么去除重复的,不想要的记录呢,当然是通过条件过滤。通常要查询的多个表之间都存在关联关系,那么就通过关联关系去除笛卡尔积
2.2.1 内连接 inner join
既然"交叉连接"不常用,那么肯定有其他的常用的"多表查询方式"。我们来看看另一种常用的多表查询的方式:内连接
扔用刚才的两张表student和class为例,首先回顾一下两张表的内容:
那么什么是"内连接"呢?我们可以把"内连接"理解成"两张表中同时符合某种条件的数据记录的组合",例如在查出的数据中同时展现学生信息和他们所在的编号,示例如下:
SELECT * FROM student, class where student.
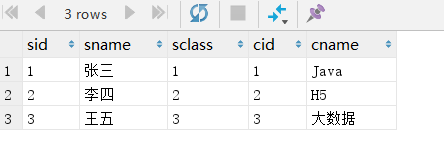
上述的sql语句就使用了"内连接",对比交叉连接发现,其实内连接就是交叉连接有更多的限制条件,内连接的英文原文为inner join,所以sql还可以写成
SELECT * FROM student INNER JOIN class ON student.sid = class.cid;
上述的是等值内连接,还可以有不等值内连接
SELECT * FROM student INNER JOIN class ON student.sid > class.cid;
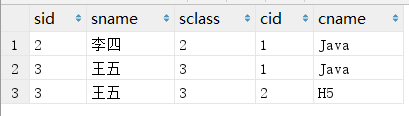
这样内连接可以用图来表示:
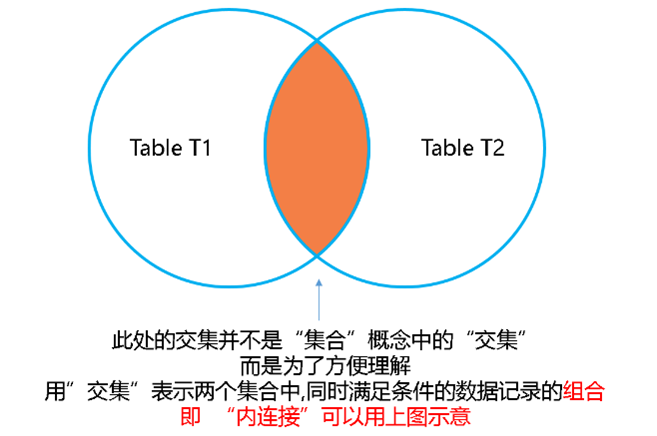
使用"内连接"语句查询出的结果集是两个集合中"同时满足条件的数据"的"组合",所以我们并不能单纯的用"交集"去表示这个组合,就以上图为例,按照"交集"的定义,属于集合A且同时属于集合B的元素所组成的集合被称为交集,但是上图中,id号为1的元素只属于t1表,在t2表中并不存在id号为1的元素,但是,上图中"中间"的结果集就是"内连接"查询出的结果,所以,我们不能单纯的用"交集"表示"内连接",但是,我们可以从另一个角度定义"交集",我们定义,“交集"为"两个集合中同时满足条件的数据的组合”
自连接
“内连接"除了"等值连接"与"不等连接”,还有一种分类,被称作"自连接",自连接可以理解为比较特殊的"内连接",刚才说到的"等值连接"与"不等连接"所连接的表为两张不同的表,而"自连接"连接的表为一张表,也就是自己连接自己,所以被称为"自连接"
我们再创建一张员工表,:
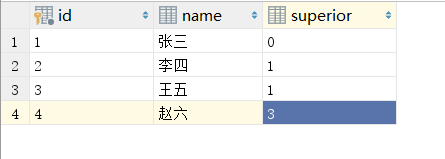
如图 员工表有上级属性,上级指向的是员工的ID,如果我们想把每个人的上级都显示出来可以使用语句:
SELECT * FROM emp AS e1 INNER JOIN emp AS e2 ON e1.superior = e2.id;

这就属于自连接,在自连接的时候,由于表名是相同的,需要给表名起一个别名
2.2.2 外连接
外连接分为两种,左外连接,和右外连接,外连接的特点,结果集中有不满足情况的
左外连接
首先还是学生和班级表,不过我们学生表中插入了一个新学生,他还没有确定班级
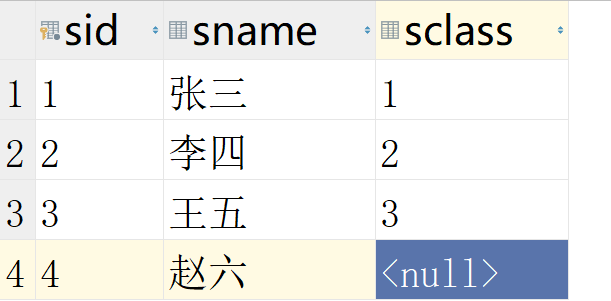
使用左外连接,查询学生信息和它对应的班级
SELECT * FROM temp.student LEFT JOIN temp.class ON sid = cid;
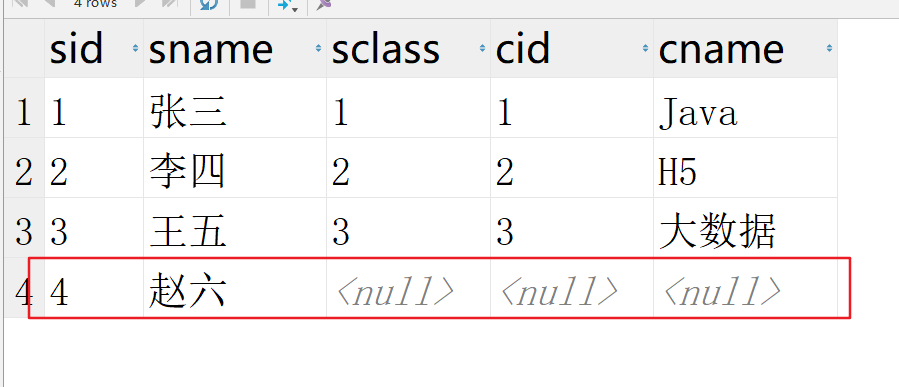
左外连接不仅会查询出两表中同时符合条件的记录的组合,同时还会将"left join"左侧的表中的不符合条件的记录同时展示出来,由于左侧表中的这一部分记录并不符合连接条件,所以这一部分记录使用"空记录"进行连接。即左表的数据会完全的加载出来,即使右表中没有符合条件的数据

右连接
右连接与之类似
SELECT * FROM temp.class RIGHT JOIN temp.student ON sid = cid;
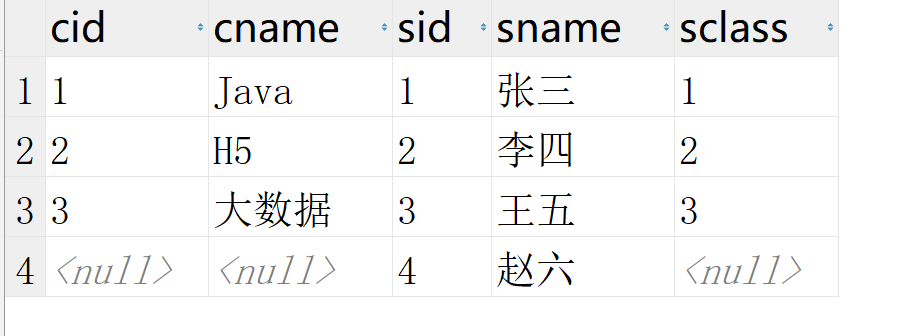

2.2.3 子查询
一个select语句中包含另一个完整的select语句。
子查询就是嵌套查询,即SELECT中包含SELECT,如果一条语句中存在两个,或两个以上SELECT,那么就是子查询语句了。
- 子查询出现的位置
- where后,作为条为被查询的一条件的一部分
- from后,作表
- 当子查询出现在where后作为条件时,还可以使用如下关键字
- any
- all
- 子查询结果集的形式
- 单行单列(用于条件)
- 单行多列(用于条件)
- 多行单列(用于条件)
- 多行多列(用于表)
示例
原始数据表

工资高于JONES的员工
SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename='JONES')
-- 一行一列
查询与SCOTT同一个部门的员工
SELECT *
FROM lan_ou.emp
WHERE deptno = (SELECT deptno
FROM lan_ou.emp
WHERE ename = 'SCOTT');
工资高于30号部门所有人的员工信息
SELECT * FROM emp WHERE sal>(
SELECT MAX(sal) FROM emp WHERE deptno=30);
查询工作和工资与MARTIN完全相同的员工信息
SELECT * FROM emp WHERE (job,sal) IN (SELECT job,sal FROM emp WHERE ename='MARTIN')
查询有2个以上直接下属的员工信息
SELECT *
FROM emp
WHERE empno IN (
SELECT mgr
FROM emp
GROUP BY mgr
HAVING COUNT(mgr) >= 2);
3. 常用函数
1. 数学函数
- ABS(x) 返回x的绝对值
- BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制)
- CEILING(x) 返回大于x的最小整数值
- EXP(x) 返回值e(自然对数的底)的x次方
- FLOOR(x) 返回小于x的最大整数值
- GREATEST(x1,x2,…,xn)返回集合中最大的值
- LEAST(x1,x2,…,xn) 返回集合中最小的值
- LN(x) 返回x的自然对数
- LOG(x,y)返回x的以y为底的对数
- MOD(x,y) 返回x/y的模(余数)
- PI()返回pi的值(圆周率)
- RAND()返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。
- ROUND(x,y)返回参数x的四舍五入的有y位小数的值
- SIGN(x) 返回代表数字x的符号的值
- SQRT(x) 返回一个数的平方根
- TRUNCATE(x,y) 返回数字x截短为y位小数的结果
2. 日期函数
- CURDATE()或CURRENT_DATE() 返回当前的日期
- CURTIME()或CURRENT_TIME() 返回当前的时间
- DATE_ADD(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_ADD- (CURRENT_DATE,INTERVAL 6 MONTH);
- DATE_FORMAT(date,fmt) 依照指定的fmt格式格式化日期date值
- DATE_SUB(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_SUB- (CURRENT_DATE,INTERVAL 6 MONTH);
- DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7)
- DAYOFMONTH(date) 返回date是一个月的第几天(1~31)
- DAYOFYEAR(date) 返回date是一年的第几天(1~366)
- DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE);
- FROM_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts
- HOUR(time) 返回time的小时值(0~23)
- MINUTE(time) 返回time的分钟值(0~59)
- MONTH(date) 返回date的月份值(1~12)
- MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE);
- NOW() 返回当前的日期和时间
- QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE);
- WEEK(date) 返回日期date为一年中第几周(0~53)
- YEAR(date) 返回日期date的年份(1000~9999)
- LAST_DAY(date) 需要一个日期或日期时间值,并返回该月的最后一天对应的值。 如果该参数是无效的,则返回NULL。
3. 字符串类
- ASCII(char)返回字符的ASCII码值
- BIT_LENGTH(str)返回字符串的比特长度
- CONCAT(s1,s2…,sn)将s1,s2…,sn连接成字符串
- CONCAT_WS(sep,s1,s2…,sn)将s1,s2…,sn连接成字符串,并用sep字符间隔
- INSERT(str,x,y,instr) 将字符串str从第x位置开始,y个字符长的子串替换为字符串instr,返回结果
- FIND_IN_SET(str,list)分析逗号分隔的list列表,如果发现str,返回str在list中的位置
- LCASE(str)或LOWER(str) 返回将字符串str中所有字符改变为小写后的结果
- LEFT(str,x)返回字符串str中最左边的x个字符
- LENGTH(s)返回字符串str中的字符数
- LTRIM(str) 从字符串str中切掉开头的空格
- POSITION(substr,str) 返回子串substr在字符串str中第一次出现的位置
- QUOTE(str) 用反斜杠转义str中的单引号
- REPEAT(str,srchstr,rplcstr)返回字符串str重复x次的结果
- REVERSE(str) 返回颠倒字符串str的结果
- RIGHT(str,x) 返回字符串str中最右边的x个字符
- RTRIM(str) 返回字符串str尾部的空格
- STRCMP(s1,s2)比较字符串s1和s2
- TRIM(str)去除字符串首部和尾部的所有空格
- UCASE(str)或UPPER(str) 返回将字符串str中所有字符转变为大写后的结果
4. 导出数据
mysqldump –hlocalhost –uroot –p databaseName >d:\dump.sql (window)