在目前数据集中拟合得非常好的算法不一定在新数据集中也能work,极有可能发生了overfitting,所以需要一个评估的方法来判断这个算法是否在新的数据集中可行。
1Evaluating a Learning Algorithm
首先第一步要做的,就是将目前已有的数据集随机打乱,然后分成training set和test set,一般70%的training set,30%作为test set。随即打乱是为了保持training set和test set的类别分布均匀。
然后根据training set中的错误J(θ)来更新模型;
最后使用test set中的错误J(θ)来评价模型。错误越小越好。
test set error反映出一个模型的范化能力。
Linear Regression的步骤:

Logistic Regression以及one-to-rest的多分类步骤

如果有多个模型,需要从中挑选出一个最好的模型,如下图:


模型中的权值theta和偏置b都是:
2Bias vs. Variance
high bias的意思是:拟合程度不同
3 Precision & Recall
对于那种“倾斜的数据集(skewed dataset)”,所谓“倾斜”的意思是说,各类别的数据量相差很大。单纯地使用“准确率accuracy”是没法判断模型的好坏的,比如下面的例子:
健康的人有99个(y=0),得癌症的病人有1个(y=1)。我们用一个特别糟糕的模型,永远都输出y=0,就是让所有的病人都是健康的。
这个时候我们的“准确率”accuracy=99%,判断对了99个,判断错了1个,但是很明显地这个模型相当糟糕。
因此需要一种很好的评测方法,来把这些“作弊的”模型给揪出来。
先来了解一下真假阳阴性:
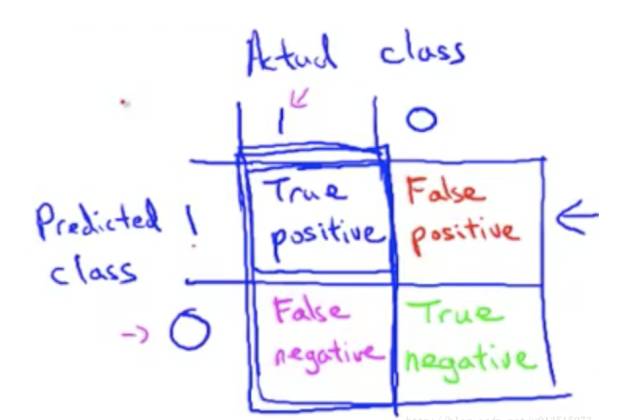
接着引入两个新的术语“查准率precision”和“召回率recall”:

解释一下,“查准率”就是说,所有被查出来得了癌症的人中,有多少个是真的癌症病人;“召回率”就是说,所有得了癌症的病人中,有多少个被查出来得癌症。
按照我们刚才的做法,recall = 01=0,所以这不是一个好模型。
拥有高查准率或者高召回率的模型是一个好模型。
注意:我们是对稀有类别使用的查准率或者召回率,而且我们会将这个“稀有类别”设置成y=1!!!
总结,在skewed dataset中,不能使用准确率accuracy来评判模型,而应该使用查准率或者召回率对模型在“稀有类别”上的performance进行评估。
4F1 score
我们希望对于某个模型而言,在precision越高的情况下,recall也会越高,但是有些情况下这两者是矛盾的,现在来考虑下面情况。
第一种情况:当且仅当非常确信他得癌症了,才确诊他得了癌症,即:
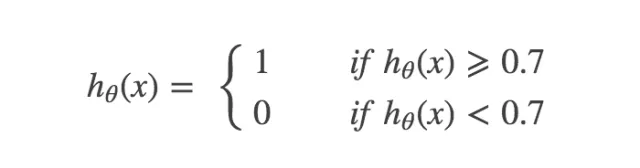
这个时候,就是要“高的查准率”,结果导致了“低的召回率”。
第二种情况:只要怀疑他得了癌症,就确诊他得了癌症,即:
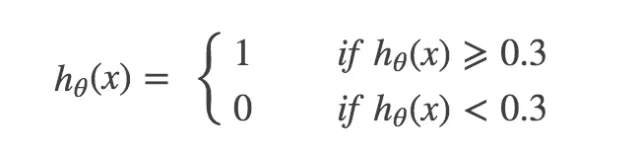
这个时候,就是要“高的召回率”,结果导致了“低的准确率”。
这种情况下precision和recall的关系图如下:
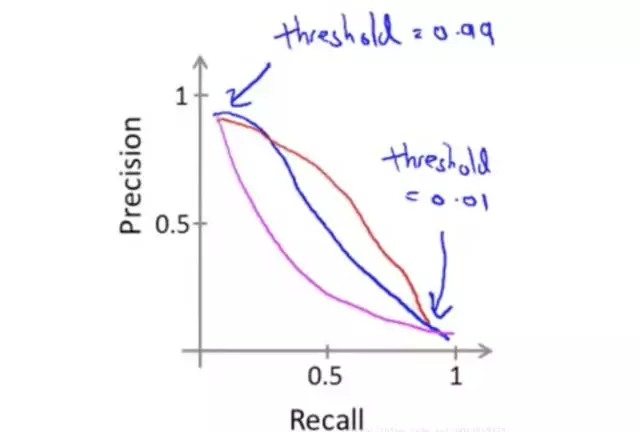
从这张图中看,precision很高的时候,recall就很低,反之。在某些应用中,我们就是需要这种precision和recall反相关的模型,但是有的情况下,我们也需要precision和recall同样好的模型,但是什么样的precision和recall才是同样好的呢?
我们需要一个标准可以综合这二者指标的评估指标,用于综合反映整体的指标,其中一种标准就是F1 score:
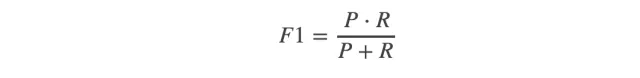
看下面一个例子中,F1 score就反映了整体的指标,当precision和recall差不多好的时候,F1也是最好的:
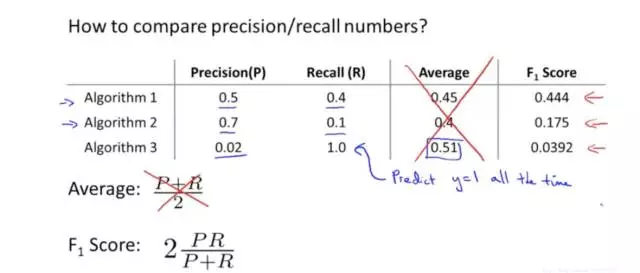
比如,当precision或者recall中有一个特别差的时候,F1会特别低:
precision=0 or recall = 0, then F1=0
当precision和recall都特别好的时候,F1也会特别好:
precision=1 and recall=1, then F1=1
总结一下,不同的应用下会有不同的评判标准,有的时候希望Precision比较高,有的时候希望Recall比较高,还有的时候希望他俩的综合指标F1比较高,这就需要自己根据具体的应用来选定了。