课程目录 小象学院 - 人工智能
关注公众号【Python家庭】领取1024G整套教材、交流群学习、商务合作。整理分享了数套四位数培训机构的教材,现免费分享交流学习,并提供解答、交流群。
你要的白嫖教程,这里可能都有喔~
本关内容概述
欢迎来到本关的学习,本关的学习目标是找到一种通用的方法来构建出一棵决策树,准备好了吗?Let's go!

我们先来回顾一下在上一关得到的两个重要结论:
-
我们做每一步决策时,希望能最大程度地减少不确定性;
-
我们用信息熵来衡量不确定性:信息熵越大,不确定性越高。
那么,我们再回头看看上一关提出的这个问题:性别和年龄哪一个特征对于我们的预测更加有效呢?

信息熵的计算
不同于上一关的观察法,这里我们将用更严谨的数学知识来计算哪个特征更能减少不确定性。
具体要怎么做呢?很简单,用原来的不确定性减去划分后的不确定性!换句话说,就是用原数据集的信息熵减去划分后的所有数据集的信息熵之和。当然了,我们希望这个差值越大越好。因为划分前后的差值越大,就表明划分后减小的不确定性越多,也就是把最终结果的范围缩小的越小。
沿用之前推荐App下载的例子,先计算最开始没有做任何划分之前的信息熵Entropy。
信息熵的表达式:![]()
我们把下载王者荣耀定义为事件1,在总的下载记录中事件1有3条记录,所以事件1出现的概率 ![]()
我们把下载微信定义为事件2,在总的下载记录中事件2有2条记录,所以事件2出现的概率![]()
我们把下载QQ定义为事件3,在总的下载记录中事件3有1条记录,所以事件3出现的概率![]()
推荐App下载这个例子中可能发生3个事件:下载王者荣耀、下载微信、下载QQ,所以信息熵计算公式中的n=3。
![]()
接下来我们要计算按照性别划分后的不确定性,也就是信息熵。
我们先看效果图,然后再看后面的计算过程,这样理解起来更加直观一些。
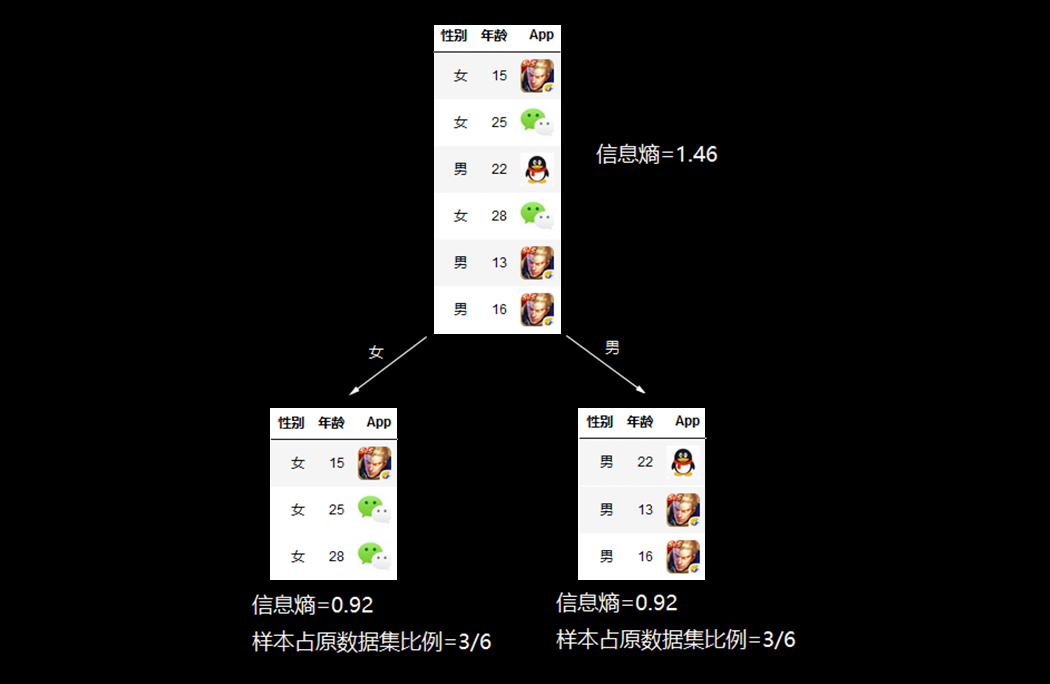
按照性别划分
女性下载App的记录有3条,占总下载记录数的![]()
男性下载App的记录也是3条,占总下载记录数的![]()
所以按照性别划分之后的信息熵:![]()
说明:
![]() :表示女性数据集的信息熵
:表示女性数据集的信息熵
![]() :表示男性数据集的信息熵
:表示男性数据集的信息熵
这里需要特别注意的是在计算划分后的信息熵时,不是简单的把划分之后的两个信息熵相加,而是计算的加权和,权重是划分后的子数据集样本数占原数据集样本数的比例。
被划分到女性的数据集的信息熵:![]()
被划分到男性的数据集的信息熵:![]()
最终按照性别划分之后的信息熵:![]()
有了划分前和划分后的信息熵之后,我们就可以对它们做差运算,计算出按照性别划分前后信息熵减少了多少。
因此,按照性别对数据集进行划分,减少的信息熵等于![]()
按照上面按照性别划分的计算方法,计算按照年龄进行划分的效果,先看效果图,有图有真相,有助于理解。

我们先把之前已经计算过的没有做任何划分之前的信息熵Entropy摆在这,方便后面计算的时候查看。
![]()
按照年龄划分
小于20岁的用户下载App的记录有3条,占总下载记录数的![]()
大于等于20岁的用户下载App的记录也是3条,占总下载记录数的![]()
所以按照年龄划分之后的信息熵:![]()
说明:
![]() :表示小于20岁数据集的信息熵
:表示小于20岁数据集的信息熵
![]() :表示大于等于20岁数据集的信息熵
:表示大于等于20岁数据集的信息熵
小于20岁数据集的信息熵:小于20岁的数据集中所有用户都下载了王者荣耀,所以概率是1,那么![]() ,因为
,因为![]()
大于等于20岁数据集的信息熵:![]()
最终按照性别划分之后的信息熵:![]()
因此,按照年龄对数据集进行划分,减少的信息熵等于$$ = 1.46 - 0.46 = 1 $$。
通过按照性别和年龄划分之后的信息熵减小值可以看出:
按照性别划分,信息熵减小值:0.54
按照年龄划分,信息熵减小值:1
经过对比,按照年龄划分信息熵减小值要大于按照性别划分信息上减小值。
因为我们要最大程度地减少不确定性(减小信息熵),所以按照年龄划分比按照性别划分可以更大程度地减少的不确定性,因此我们优先选择年龄对数据集进行划分。
这和我们上一关用观察法得到的结论是一致的,真是值得庆祝一下!

对了,顺便说一下,由于原来的不确定性减去划分后的不确定性这个差值很常用,因此我们给这个差值起了一个更加专业的名字,叫做信息增益。
我们做每一次决策都希望找到能使信息增益最大的特征,是不是瞬间感觉这个表述变得高大上了?
正如我们所愿,我们找到了一种通用的构建决策树的方法:
-
每次从当前数据集的所有特征中选出一个使信息增益最大的特征;
-
利用这个特征将原数据集划分成子数据集。
不停地重复上述两个步骤,直至构建出一棵决策树。
恭喜你,本关的内容你已学完了。。。一半。

看上去我们似乎已经掌握了构建一棵决策树的方法,我们详细地介绍了如何寻找信息增益最大的特征,这一步没有任何问题;然后我们利用这个特征划分数据集,这一步有没有不对劲的地方呢?
回想一下,利用性别特征划分数据集时,处理起来很方便,因为性别这个特征是个离散特征,只有男和女两种取值,对每种取值创建一个分支就可以了;但是,利用年龄特征划分数据集时,我们采用了20岁作为一个阈值,那么问题来了,20这个数是从哪来的呢?
这就涉及到了决策树算法中如何处理连续型特征的问题,年龄特征是个连续特征,如何利用连续特征对数据集进行划分呢?
连续特征的处理
这当然难不倒我们。
仍使用推荐App下载的例子,数据集中所有样本的年龄为{15,25,22,28,13,16}。我们的目标是找到一个合适的阈值,将数据集分成两部分,从而将连续的问题转化为离散的问题。
排序
先将所有年龄升序排列得到 {13,15,16,22,25,28}。
遍历
对于这个排好序的结果,一个简单的处理思路就是选取一个合适的步长,遍历13到28之间的所有数值,比如以1为步长,我们需要尝试13,14,15,......,27,28分别作为阈值,分别计算出相应的信息增益,从而选出一个最优的阈值。
再仔细想想,就会发现,其实不需要尝试这么多阈值,比如说,阈值取23和24,用这两个值来划分数据集的效果其实是一模一样的!我们只需要在每两个样本之间任意找一个值进行尝试就可以了,如下图所示:

为了方便起见,我们通常会直接取两个样本的平均值作为阈值,因此,我们只需要遍历14, 15.5, 19, 23.5, 26.5这5个阈值,分别计算相应的信息增益,从中选出最优的那个阈值即可。
小练习
接下来是练习的时间了,请你通过编程计算出这5种情况下(分别以14,15.5,19,23.5,26.5作为阈值)的信息增益,并思考哪种划分是最优的。

AI_14_0_1
import numpy as np
# 原数据集的信息熵≈1.46
entropy = -( 1/2 * np.log2(1/2) + 1/3 * np.log2(1/3) + 1/6 * np.log2(1/6))
# 分别计算出划分后的子数据集的信息熵的加权和
entropy1 = 1/6 * 0 + 5/6 * -(2/5 * np.log2(2/5) + 1/5 * np.log2(1/5) + 2/5 * np.log2(2/5))
entropy2 = 2/6 * 0 + 4/6 * -(1/4 * np.log2(1/4) + 1/4 * np.log2(1/4) + 2/4 * np.log2(2/4) )
entropy3 = 3/6 * 0 + 3/6 * -(1/3 * np.log2(1/3) + 2/3 * np.log2(2/3))
entropy4 = 4/6 * -(3/4 * np.log2(3/4) + 1/4 * np.log2(1/4)) + 2/6 * 0
entropy5 = 5/6 * -(3/5 * np.log2(3/5) + 1/5 * np.log2(1/5) + 1/5 * np.log2(1/5) ) + 1/6 * 0
# 分别计算出每种划分的信息增益
gain1 = entropy - entropy1
gain2 = entropy - entropy2
gain3 = entropy - entropy3
gain4 = entropy - entropy4
gain5 = entropy - entropy5
print("gain1=",gain1)
print("gain2=",gain2)
print("gain3=",gain3)
print("gain4=",gain4)
print("gain5=",gain5)5种情况下计算出的信息增益分别为0.19,0.46,1,0.92,0.32,可以看出,第3种划分得到的信息增益是最大的,也就是说我们在16到22之间任意找一个数作为阈值,得到的划分是最优的。到此为止,我们就解释清楚了20这个阈值是怎么来的。
本关总结:在本关,我们给出了构建一棵决策树的通用方法,并对其中的两个步骤进行了详细地介绍。如果你能回答出以下两个问题,那说明本关内容你已经完全掌握了:
- 给定数据集,选择哪个特征进行当前划分?
- 对于选定的特征,在哪个阈值上进行划分?
今天我们就先学到这里吧,下一关见,拜拜~
联系我们,一起学Python吧
分享Python实战代码,入门资料,进阶资料,基础语法,爬虫,数据分析,web网站,机器学习,深度学习等等。
 关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作
关注公众号「Python家庭」领取1024G整套教材、交流群学习、商务合作