数据类型
( 1) torch.FloatTensor : 用于生成数据类型为浮点型的Tensor ,传递给torch.FloatTensor的参数可以是一个列表,也可以是一个维度值。
torch.randn :用于生成数据类型为浮点型且维度指定的随机Tensor ,和在N umPy中使用numpy . randn 生成随机数的方法类似,随机生成的浮点数的取值满足均值为0 、方差为1的正态分布
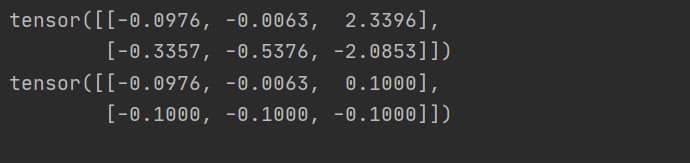
torch.clamp : 对输入参数按照自定义的范围进行裁剪, 最后将参数裁剪的结果作为输出。所以输入参数一共有三个,分别是需要进行裁剪的Tensor 数据类型的变量、裁剪的上边界和裁剪的下边界, 具体的裁剪过程是: 使用变量中的每个元素分别和裁剪的上边界及裁剪的下边界的值进行比较,如果元素的值小于裁剪的下边界的值, 该元素就被重写成裁剪的下边界的值: 同理,如果元素的值大于裁剪的上边界的值, 该元素就被重写成裁剪的上边界的值。
a = torch.randn(2,3)
print(a)
b = torch.clamp(a,-0.1,0.1)
print(b)
结果:
torch.div : 将参数传递到to rch.div 后返回输入参数的求商结果作为输出,同样,参与运算的参数可以全部是Tensor 数据类型的变量,也可以是Tensor 数据类型的变量和标量的组合。
torch.mm : 将参数传递到torch.mm 后返回输入参数的求积结果作为输出,不过这个求积的方式和之前的torch.mul运算方式不太一样, torch.mm 运用矩阵之间的乘法规则进行计算,所以被传入的参数会被当作矩阵进行处理, 参数的维度自然也要满足矩阵乘法的前提条件,即前一个矩阵的行数必须和后一个矩阵的列数相等,否则不能进行计算。
torch.mv : 将参数传递到torch.mv后返回输入参数的求积结果作为输出,torch.mv运用矩阵与向量之间的乘法规则进行计算, 被传入的参数中的第1个参数代表矩阵,第2个参数代表向量, 顺序不能颠倒。
torch. autograd
torch. autograd 包的主要功能是完成神经网络后向传播中的链式求导,手动实现链式求导的代码会给我们带来很大的困扰,而torch.autograd 包中丰富的类减少了这些不必要的麻烦
。如果用autograd.Variable 来定义参数,则 Variable 自动定义了两个变量,data代表原始权重数据;而 grad 代表求导后的数据,也就是梯度。每次迭代过程就用这个 grad 对权重数据进行修正。
from torch.autograd import Variable
x = Variable(torch.ones(2, 2), requires_grad=True)
print(x)
实现自动梯度功能的过程大致为:先通过输入的Tensor 数据类型的变量在神经网络的前向传播过程中生成一张计算图,然后根据这个计算图和输出结果准确计算出每个参数需要更新的梯度,并通过完成后向传播完成对参数的梯度更新。
这个包的使用:
from torch.autograd import Variable
batch_n = 100
hidden_layer = 100
input_data = 1000
output_data = 10
x = Variable (torch。randn(batch_n , input_data), requires _grad= False)
y = Variable(torch。randn(batch_n , output_data) , requires_grad =False)
wl =Variable(torch. randn(input_data, hidden layer) , requires_grad= True)
w2 =Variable(torch.randn(hidden_layer, output_ data) , requires_grad =True)
input_ data 是输入数据的特征个数, hidden_layer 是通过隐藏层后输出的特征数,output_ data 是最后输出的分类结果数,如果requires_grad 的值是False ,那么表示该变量在进行自动梯度计算的过程中不会保留梯度值,将输入的数据x 和输出的数据y 的requires_grad 参数均设置为False , 这是因为这两个变量并不是我们的模型需要优化的参数。w1 w2的requires_grad 参数均设置为True 。
关于Variable :Variable 不光包含了数据,还包含了其他东西,
x=Variable(torch.Tensor(2,2)) 默认 Variable 是有导数 grad的,x.data 是数据,这里 x.data 就是Tensor。x.grad 是计算过程中动态变化的导数。
定义训练次数和学习率:
epoch_n = 20
learning_rate = 1e-6
权值更新方法:
weight = weight + learning_rate * gradient
learning_rate = 0.01
for f in model.parameters():
f.data.sub_(f.grad.data * learning_rate)
learning_rate 是学习速率,多数时候就叫做 lr,是学习步长,用步长 *导数就是每次权重修正的 delta 值,lr 越大表示学习的速度越快,相应的精度就会降低。
如同使用PyTorch 中的自动梯度方法一样,在搭建复杂的神经网络模型的时候, 我们也可以使用PyTorch 中己定义的类和方法,这些类和方法覆盖了神经网络中的线性变换、激活函数、卷积层、全连接层、池化层等常用神经网络结构的实现。在完成模型的搭建之后, 我们还可以使用PyTorch 提供的类型丰富的优化函数来完成对模型参数的优化, 除此之外, 还有很多防止模型在模型训练过程中发生过拟合的类。
torch.nn
PyTorch 中的torch.nn 包提供了很多与实现神经网络中的具体功能相关的类,这些类涵盖了深度神经网络模型在搭建和参数优化过程中的常用内容,比如神经网络中的卷积层、池化层、全连接层这类层次构造的方法、防止过拟合的参数归一化方法、Dropout 方法,还有激活函数部分的线性激活函数、非线性激活函数相关的方法, 等等
torch .nn 包中的类能够帮助我们自动生成和初始化对应维度的权重参数。模型搭建的代码如下:
models = torch.nn.Sequential(
torch.nn.Linear(input_data , hidden_layer ),
torch.nn.ReLU() ,
torch.nn.Linear(hidden_layer , output_data)
)
通过torch.nn .Linear( input_data, hidden layer)完成从输入层到隐藏层的线性变换,然后经过激活函数及torch.nn .Linear(hidden layer, output_ da ta)完成从隐藏层到输出层的线性变换。torch.nn.Linear 类接收的参数有三个,分别是输入特征数、输出特征数和是否使用偏置,设置是否使用偏置的参数是一个布尔值,默认为True ,即使用偏置。在实际使用的过程中,我们只需将输入的特征数和输出的特征数传递给
torch.nn.Linear 类, 就会自动生成对应维度的权重参数和偏置
torch.nn.Sequential类是torch. nn 中的一种序列容器,通过
在容器中嵌套各种实现神经网络中具体功能相关的类,来完成对神经网络模型的搭建,最主要的是,参数会按照我们定义好的序列自动传递下去。我们可以将嵌套在容器中的各个部分看作各种不同的模块,这些模块可以自由组合。模块的加入一般有两种方式, 一种是在以上代码中使用的直接嵌套,另一种是以orderdict 有序字典的方式进行传入,这两种方式的唯一区别是,使用后者搭建的模型的每个模块都有我们自定义的名字, 而前者默认使用从零开始的数字序列作为每个模块的名字。下面通过示例来直观地看一下字典方
式搭建的模型。
字典:
models= torch.nn.Sequential( Orde redDict( [
("Line1", torch.nn.Linear(input data , hidden_layer ) ) ,
("Relul", torch.nn.ReLU() ) ,
("Line2", torch.nn.Linear(hidden_layer , output_data) ) ])
)
torch.nn.Linear类用于定义模型的线性层,即完成前面提到的
不同的层之间的线性变换。torch.nn.Linear 类接收的参数有三个,分别是输入特征数、输出特征数和是否使用偏置,设置是否使用偏置的参数是一个布尔值,默认为True ,即使用偏置。在实际使用的过程中,我们只需将输入的特征数和输出的特征数传递给torch.nn.Linear 类, 就会自动生成对应维度的权重参数和偏置
torch.nn.ReLU 类属于非线性激活分类,在定义时默认不需要传入参数。当然,在torch.nn 包中还有许多非线性激活函数类可供选择,比如之前讲到的PReLU 、LeakyReLU 、Tanh 、S igmoid 、Softmax 等。
torch.nn.MSELoss类使用均方误差函数对损失值进行计算,
在定义类的对象时不用传入任何参数,但在使用实例时需要输入两个维度一样的参数方可进行计算
from torch.autograd import Variable
loss f = torch.nn.MSELoss( )
x = Variable (torch.randn(100 , 100 ) )
y = Variable(torch.randn(l00 , 100))
loss =loss_f(x , y)
print(loss . data)
torch.nn.L1Loss 类使用平均绝对误差函数对损失值进行计算,
同样,在定义类的对象时不用传入任何参数,但在使用实例时需要输入两个维度一样的参数进行计算。
torch.nn.CrossEntropyLoss 类用于计算交叉熵,在定义类的对象时不用传入任何参数,在使用实例时需要输入两个满足交叉熵计算条件的参数
nn.NLLLoss2d
和上面类似,但是多了几个维度,一般用在图片上。
input, (N, C, H, W)
target, (N, H, W)
比如用全卷积网络做分类时,最后图片的每个点都会预测一个类别标签。
Adam 优化函数还有一个强大的功能,就是可以对梯度更新使用到的学习速率进行自适应调节
PyTorch 之torch.optim
优化器Optim
优化器用通俗的话来说就是一种算法,是一种计算导数的算法。各种优化器的目的和发明它们的初衷其实就是能让用户选择一种适合自己场景的优化器。优化器的最主要的衡量指标就是优化曲线的平稳度,最好的优化器就是每一轮样本数据的优化都让权重参数匀速的接近目标值,而不是忽上忽下跳跃的变化。因此损失值的平稳下降对于一个深度学习模型来说是一个非常重要的衡量指标。
在PyTorch 的torch.optim 包中提供了非常多的可实现参数自动优化的类,比如SGD 、AdaGrad 、RMS Prop 、Adam 等,这些类都可以被直接调用,使用起来也非常方便。可以直接调用optimzer. zero_grad 来完成对模型参数梯度的归零; optimzer.step , 它的主要功能是使用计算得到的梯度值对各个节点的参数进行梯度更新。
SGD
SGD 指stochastic gradient descent,即随机梯度下降,随机的意思是随机选取部分数据集参与计算,是梯度下降的 batch 版本。SGD 支持动量参数,支持学习衰减率
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
lr:大于 0 的浮点数,学习率。
momentum:大于 0 的浮点数,动量参数。
parameters:Variable 参数,要优化的对象。
对于训练数据集,我们首先将其分成 n 个 batch,每个 batch 包含 m 个样本。我们每次更新都利用一个 batch 的数据,而非整个训练集,
手写数字识别
使用torchvision. datasets 可以轻易实现对这些数据集的训练集和测试集的下载,只需要使用torchvision.datasets 再加上需要下载的数据集的名称就可以了,
1.下载数据集:
data_train= datasets.MNIST(root =". /data / ",
transform=transform,
train = True,
download = True)
data_test = datasets.MNIST(root=". / data /",
transform = transform,
train = False )
train 用于指定在数据集下载完成后需要载入哪部分数据,如果设置为True ,则说明载入的是该数据集的训练集部分; 如果设置为False ,则说明载入的是该数据集的测试集部分。
torch.transforms 中有大量的数据变换类, 其中有很大一部分可以用于实现数据增强
torchvision. transforms 中常用的数据变换操作:
torchvision.transforms.Resize :用于对载入的图片数据按我们需求的大小进行缩放。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h , w)的序列, 其中, h 代表高度, w 代表宽度,但是如果使用的是一个整型数据,那么表示缩放的宽度和高度都是这个整型数据的值。
torchvision.transforms.Scale : 用于对载入的图片数据按我们需求的大小进行缩放,用法和torchvision . transforms.Resize 类似
torchvision.transforms.CenterCrop :用于对载入的图片以图片中心为参考点, 按我们需要的大小进行裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于( h , w )的序列。
torchvision.transforms.RandomHorizontaIFlip : 用于对载入的图片按随机概率进行水平翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0.5
torchvision.transforms.Random VerticalFlip : 用于对载入的图片按随机概率进行垂直翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0. 5
torchvision.transforms. ToPILlmage : 用于将Tensor 变量的数据转换成PIL 图片
torchvision.transforms. ToTensor : 用于对载入的图片数据进行类型转换, 将之前构成PIL 图片的数据转换成Tensor 数据类型的变量, 让PyTorch 能够对其进行计算和处理。
torchvision.transforms.Compose 类看作一种容器, 它能够同时对多种数据变换进行组合。传入的参数是一个列表,列表中的元素就是对载入的数据进行的各种变换操作。如:
transform =transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5] , std=[0.5 , 0.5, 0.5])])
transforms.Normalize这里使用的标准化变换也叫作标准差变换法,这种方法需要使用原始数据的均值( Mean )和标准差来进行数据的标准化,在经过标准化变换之后,数据全部符合均值为0 、标准差为1的标准正态分布
2.装载图片:
data_loader_train = torch.utils.data.DataLoader(dataset=data_train,batch_size = 64,shuffle = True)
data_loader_test= torch.utils.data.DataLoader (dataset=data_test,batch_size = 64 ,shuffle = True)
对数据的装载使用的是torch.utils .data. Data Loader 类, 类中的dataset 参数用于指定我们载入的数据集名称, batch_s ize 参数设置了每个包中的图片数据个数,代码中的值是64,
所以在每个包中会包含64 张图片。将shuffle 参数设置为True , 在装载的过程会将数据随机打乱顺序并进行打包。
全部代码:
data_train=datasets.MNIST(root ="./data/",transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5] , std=[0.5 , 0.5, 0.5] ) ]
),train = True,download = True)
data_test = datasets.MNIST(root="./data/",transform =transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5] , std=[0.5 , 0.5, 0.5])]),train = False )
data_loader_train = torch.utils.data.DataLoader(dataset=data_train,batch_size = 64,shuffle = True)
data_loader_test= torch.utils.data.DataLoader (dataset=data_test,batch_size = 64 ,shuffle = True)
images , labels= next(iter(data_loader_train))
img = torchvision.utils.makegrid(images)
img = img.numpy().transpose (1 , 2 , 0)
std= [ 0.5 , 0.5 , 0.5]
mean = [ 0.5 , 0.5 , 0.5]
img = img*std+mean
print([labels[i] for i in range(64)])
plt.imshow(img)
因为下载过程中实在太慢,一小时了才百分之零点几,所有就没有继续跑了。
模型搭建和参数优化
在顺利完成数据装载后, 我们就可以开始编写卷积神经网络模型的搭建和参数优化的代码了。因为我们想要搭建一个包含了卷积层、激活函数、池化层、全连接层的卷积神经网络来解决这个问题,所以模型在结构上会和之前简单的神经网络有所区别, 当然, 各个部分的功能实现依然是通过torch.nn 中的类来完成的
如卷积层使用torch.nn.Conv2d 类方法来搭建; 激活层使用torch.nn.ReLU 类方法来搭建; 池化层使用torch.nn .MaxPool2d
实现卷积神经网络模型搭建的代码如下:
class Model(torch . nn .Module):
def init (self):
super(Model,self)__init__()
self.convl=torch.nn.Sequential(
torch.nn.Conv2d (l, 64 ,kernel_size=3 , stride=l , padding=l) ,
torch.nn.ReLU (),
torch.nn.Conv2d(64,128,kernel_size=3 , stride=l,padding=l),
torch.nn.ReLU() ,
torch.nn.MaxPool2d(stride=2,kernel size=2))
self.dense=torch.nn.Sequential(
torch.nn.Linear(14*14*128,10 24);
torch.nn.ReLU(),
torch.nn.Dropout (p=O.5) ,
torch.nn.Linear (1024, 10))
def forward(self, x) :
x = self.convl(x)
x = x.view(-1 , 14*14*128)
x = self.dense(x)
return x
torch.nn.Conv2d :用于搭建卷积神经网络的卷积层,Paddingde 的数据类型是整型,值为0 时表示不进行边界像素的填充,如果值大于0 ,那么增加数字所对应的边界像素层数。
torch.nn.MaxPool2d : 用于实现卷积神经网络中的最大池化层,主要的输入参数是池化窗口大小、池化窗口移动步长和Paddingde 值。
torch.nn.Dropout 类用于防止卷积神经网络在训练的过程中发
生过拟合, 其工作原理简单来说就是在模型训练的过程中,以一定的随机概率将卷积神经网络模型的部分参数归零, 以达到减少相邻两层神经连接的目的
nn.Sequential:一个Sequential容器,是一个包含其他模块的模块,它可以快速搭建神经网络
Linear:每个Linear模块使用线性函数来计算,它会内部创建需要的weight和bias
一些代码的解释:
获取一个批次的数据井迸行数据预览和分析,代码如下:
X_example , y_example = next(iter(dataloader [“train” ]))
以上代码通过next 和iter迭代操作获取一个批次的装载数据
_, predicted = torch.max(outputs.data, 1):
首先,torch.max()这个函数返回的是两个值,第一个值是具体的value(我们用下划线_表示),第二个值是value所在的index(也就是predicted)。数字1其实可以写为dim=1,这里简写为1,python也可以自动识别,dim=1表示输出所在行的最大值,若改写成dim=0则输出所在列的最大值。