13_Loading and Preprocessing Data from multiple CSV with TensorFlow_custom training loop_TFRecord
https://blog.csdn.net/Linli522362242/article/details/107704824
13_Loading and Preprocessing Data from multiple CSV with TensorFlow 2_Feature Columns_TF eXtended
https://blog.csdn.net/Linli522362242/article/details/107933572
The TensorFlow Datasets (TFDS) Project
The TensorFlow Datasets project makes it very easy to download common datasets, from small ones like MNIST or Fashion MNIST to huge datasets like ImageNet (you will need quite a bit of disk space!). The list includes image datasets, text datasets
(including translation datasets), and audio and video datasets. You can visit https://homl.info/tfds to view the full list, along with a description of each dataset.
TFDS is not bundled with TensorFlow, so you need to install the tensorflowdatasets library (e.g., using pip https://blog.csdn.net/Linli522362242/article/details/108037567). Then call the tfds.load() function, and it will download the data you want (unless it was already downloaded earlier) and return the data as a dictionary of datasets (typically one for training and one for testing, but this depends on the dataset you choose).
For example, let’s download MNIST:
import tensorflow_datasets as tfds
datasets = tfds.load(name="mnist")
datasets
The load() function shuffles each data shard it downloads (only for the training set). This may not be sufficient, so it’s best to shuffle the training data some more.
mnist_train, mnist_test = datasets["train"], datasets["test"]Find available datasets
All dataset builders are subclass of tfds.core.DatasetBuilder. To get the list of available builders, uses tfds.list_builders() or look at our catalog.
print(tfds.list_builders())
You can then apply any transformation you want (typically shuffling, batching, and prefetching), and you’re ready to train your model. Here is a simple example:
mnist_train, mnist_test = datasets["train"], datasets["test"]
plt.figure( figsize=(6,3) )
#mnist_train = mnist_train.repeat(5).shuffle(10000).batch(32).prefetch(1)
mnist_train = mnist_train.repeat(5).batch(32).prefetch(1) # for getting same data
for item in mnist_train:
images = item["image"]
labels = item["label"]
for index in range(5):
#print(len(images))# 32 since batch(32)
plt.subplot(1,5, index+1)
image = images[index, ...,0]#indices end with 0 since images[index]: (28, 28, 1) and '0' select [1]th element
label = labels[index].numpy()
plt.imshow(image, cmap="binary")
plt.title(label)
plt.axis("off")
break # just showing part of the first batch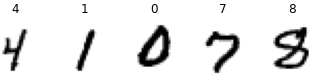
The load() function shuffles each data shard it downloads (only for the training set). This may not be sufficient, so it’s best to shuffle the training data some more.
Note that each item in the dataset is a dictionary containing both the features and the labels. But Keras expects each item to be a tuple containing two elements (again, the features and the labels). You could transform the dataset using the map() method, like this:
Figure 13-2. Loading and preprocessing data from multiple CSV files https://blog.csdn.net/Linli522362242/article/details/107704824
datasets = tfds.load(name="mnist")
mnist_train, mnist_test = datasets["train"], datasets["test"]
#mnist_train = mnist_train.repeat(5).shuffle(10000).batch(32)
mnist_train = mnist_train.repeat(5).batch(32) # for getting same data ###########
mnist_train = mnist_train.map( lambda items: (items["image"], items["label"]) )###########
mnist_train = mnist_train.prefetch(1)
for images, labels in mnist_train.take(1):
print(images.shape)
print(labels.numpy())![]()
datasets = tfds.load(name="mnist")
mnist_train, mnist_test = datasets["train"], datasets["test"]
#mnist_train = mnist_train.repeat(5).shuffle(10000).batch(32)
mnist_train = mnist_train.repeat(5) # for getting same data ###########
mnist_train = mnist_train.map( lambda items: (items["image"], items["label"]) )###########
mnist_train = mnist_train.batch(32) ###########
mnist_train = mnist_train.prefetch(1)
for images, labels in mnist_train.take(1):
print(images.shape)
print(labels.numpy())![]()
datasets = tfds.load(name="mnist")
mnist_train, mnist_test = datasets["train"], datasets["test"]
#mnist_train = mnist_train.repeat(5).shuffle(10000).batch(32)
mnist_train = mnist_train.repeat(5) # for getting same data ###########
mnist_train = mnist_train.map( lambda items: (items["image"], items["label"]) )###########
mnist_train = mnist_train.batch(32) ###########
mnist_train = mnist_train.prefetch(1)
for images, labels in mnist_train.take(1):
n_cols = 10
n_rows = len(labels)//10+1
plt.figure( figsize=(n_cols*1.2, n_rows*1.2) ) # 0.2: for the extra space
for row in range(n_rows):
for col in range(len(labels)-row*n_cols):
index = n_cols * row + col
plt.subplot( n_rows, n_cols, index+1 ) # the subplot's index start 1
plt.imshow(images[index,...,0], cmap="binary", interpolation="nearest" )
plt.axis("off") #remove the axis
plt.title(labels.numpy()[index], fontsize=12)
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.show()
But it’s simpler to ask the load() function to do this for you by setting as_supervised=True (obviously this works only for labeled datasets). You can also specify the batch size if you want. Then you can pass the dataset directly to your tf.keras model:
https://blog.csdn.net/Linli522362242/article/details/104124771
Equation 4-22. Cross entropy cost function 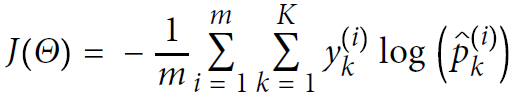
![]() is equal to 1 if the target class for the ith instance is k; otherwise, it is equal to 0.
is equal to 1 if the target class for the ith instance is k; otherwise, it is equal to 0.
Notice that when there are just two classes (K = 2), this cost function is equivalent to the Logistic Regression’s cost function (log loss; see Equation 4-17 ![]() OR
OR ![]() (L2 regularization
(L2 regularization ![]() ) Before building this model, recall that our objective is to minimize the cost function in regularized logistic regression( divided by m(instances) for calculating the partial derivative of the cost function since since the weight update in logistic regression via gradient descent):
) Before building this model, recall that our objective is to minimize the cost function in regularized logistic regression( divided by m(instances) for calculating the partial derivative of the cost function since since the weight update in logistic regression via gradient descent): ![]()
).https://blog.csdn.net/Linli522362242/article/details/96480059
https://blog.csdn.net/Linli522362242/article/details/106433059
There are two ways to handle labels in multiclass classification:
– Encoding the labels via categorical encoding (also known as one-hot encoding) andn using categorical_crossentropy as a loss function
– Encoding the labels as integers and using the sparse_categorical_crossentropy loss function
https://blog.csdn.net/Linli522362242/article/details/106562190
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
datasets = tfds.load(name="mnist", batch_size=32, as_supervised=True)###########
mnist_train = datasets["train"].repeat().prefetch(1)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28,1]), #to 1D
keras.layers.Lambda( lambda images: tf.cast(images, tf.float32) ),#since types: {image: tf.uint8, label: tf.int64}>
keras.layers.Dense(10, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy", # 0~9 class_label
optimizer=keras.optimizers.SGD(lr=1e-3),
metrics=["accuracy"])
model.fit(mnist_train, steps_per_epoch = 60000//32, epochs=5)https://www.tensorflow.org/datasets/catalog/mnist


This was quite a technical chapter, and you may feel that it is a bit far from the abstract beauty of neural networks, but the fact is Deep Learning often involves large amounts of data, and knowing how to load, parse, and preprocess it efficiently is a
crucial skill to have. In the next chapter, we will look at convolutional neural networks, which are among the most successful neural net architectures for image processing and many other applications.
TensorFlow Hub
TF2 SavedModel
This is a SavedModel in TensorFlow 2 format. Using it requires TensorFlow 2 (or 1.15) and TensorFlow Hub 0.5.0 or newer.
Overview
This module is in the SavedModel 2.0(https://www.tensorflow.org/hub/tf2_saved_model) format and was created to help preview TF2.0 functionalities. It is based on https://tfhub.dev/google/nnlm-en-dim50/1.
Text embedding based on feed-forward Neural-Net Language Models[1] with pre-built OOV. Maps from text to 50-dimensional embedding vectors.
Example use
The saved model can be loaded directly:
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/tf2-preview/nnlm-en-dim50/1")
embeddings = embed(["cat is on the mat", "dog is in the fog"])It can also be used within Keras:
The tensorflow_hub library provides the class hub.KerasLayer that gets initialized with the URL (or filesystem path) of a SavedModel and then provides the computation from the SavedModel, including its pre-trained weights.
hub_layer = hub.KerasLayer("https://tfhub.dev/google/tf2-preview/nnlm-en-dim50/1", output_shape=[50],
input_shape=[], dtype=tf.string)
model = keras.Sequential()
model.add(hub_layer)
model.add(keras.layers.Dense(16, activation='relu'))
model.add(keras.layers.Dense(1, activation='sigmoid'))
model.summary()
Details
Based on NNLM(Neural-Net Language Models) with two hidden layers.
Input
The module takes a batch of sentences in a 1-D tensor of strings as input.
Preprocessing
The module preprocesses its input by splitting on spaces.
Out of vocabulary tokens
Small fraction of the least frequent tokens and embeddings (~2.5%) are replaced by hash buckets. Each hash bucket is initialized using the remaining embedding vectors that hash to the same bucket.
Sentence embeddings
Word embeddings are combined into sentence embedding using the sqrtn combiner (see tf.nn.embedding_lookup_sparse).
sentences = tf.constant(["It was a great movie", "The actors were amazing"])
embeddings = hub_layer(sentences)
embeddings3x16+2=50

print(embeddings.shape, embeddings.dtype) ![]()
https://www.tensorflow.org/hub/tf2_saved_model
Exercises
1. Why would you want to use the Data API?
Ingesting a large dataset and preprocessing it efficiently can be a complex engineering challenge. The Data API makes it fairly simple. It offers many features, including loading data from various sources (such as text or binary files), reading
data in parallel from multiple sources, transforming it, interleaving the records, shuffling the data, batching it, and prefetching it.
2. What are the benefits of splitting a large dataset into multiple files?
Splitting a large dataset into multiple files makes it possible to shuffle it at a coarse level(dataset = tf.data.Dataset.list_files(filepaths).repeat(repeat)) before shuffling it at a finer level using a shuffling buffer(dataset = dataset.shuffle(shuffle_buffer_size)). It also makes it possible to handle huge datasets that do not fit on a single machine. It’s also simpler to manipulate thousands of small files rather than one huge file; for example, it’s easier to split the data into multiple subsets. Lastly, if the data is split across multiple files spread across multiple servers, it is possible to download several files from different servers simultaneously, which improves the bandwidth usage.
https://blog.csdn.net/Linli522362242/article/details/107704824
import numpy as np
def save_to_multiple_csv_files(data, name_prefix, header=None, n_parts=10):
housing_dir = os.path.join("datasets", "housing")
os.makedirs( housing_dir, exist_ok=True)
path_format = os.path.join(housing_dir, "my_{}_{:02d}.csv")
filepaths = []
m = len(data)
# file_idx: group indices of multiple arrays
# row_indices: element indices in an array
# np.split==> [array([ 0., 1., 2.]), array([ 3., 4., 5.]), array([ 6., 7., 8.])]
# np.array_split==>[array([ 0., 1., 2.]), array([ 3., 4., 5.]), array([ 6., 7.])]
for file_idx, row_indices in enumerate( np.array_split(np.arange(m), n_parts) ): # iterate files
part_csv = path_format.format(name_prefix, file_idx)#os.path.join(housing_dir, "my_{}_{:02d}.csv")
filepaths.append(part_csv)
#"t": refers to the text mode
with open(part_csv, "wt", encoding="utf-8") as f:
if header is not None:
f.write(header)
f.write("\n")
for row_idx in row_indices: # iterate rows
# str()主要面向用户,其目的是可读性,返回形式为用户友好性和可读性都较强的字符串类型;
# repr() 函数将对象转化为供解释器读取的形式
# 当我们想所有环境下都统一显示的话,可以重构__repr__方法;
# 当我们想在不同环境下"支持不同的显示",例如终端用户显示使用__str__,
# 而程序员在开发期间则使用底层的__repr__来显示,实际上__str__只是覆盖了__repr__
# 以得到更友好的用户显示。
f.write(",".join([repr(col) for col in data[row_idx]
])
)
f.write("\n")
return filepaths
train_data = np.c_[X_train, y_train]
valid_data = np.c_[X_valid, y_valid]
test_data = np.c_[X_test, y_test]
# y_target
header_cols = housing.feature_names + ["MedianHouseValue"]
header = ",".join(header_cols)
train_filepaths = save_to_multiple_csv_files( train_data, "train", header, n_parts=20 )
valid_filepaths = save_to_multiple_csv_files( valid_data, "valid", header, n_parts=10 )
test_filepaths = save_to_multiple_csv_files( test_data, "test", header, n_parts=10 ) 
# scaler = StandardScaler()
# scaler.fit(X_train)
# X_mean = scaler.mean_
# X_std = scaler.scale_
n_inputs = 8 # X_train.shape[-1] # X_train.shape=(11610, 8)
@tf.function
def preprocess(line):
defs =[0.]*n_inputs + [tf.constant([], dtype=tf.float32)] # record_defaults
fields = tf.io.decode_csv(line, record_defaults=defs)
x = tf.stack(fields[:-1])
y = tf.stack(fields[-1:])
return (x - X_mean)/X_std, ydef csv_reader_dataset(filepaths, repeat=1,
n_readers=5,# number of files or filepaths
n_read_threads=None,
shuffle_buffer_size=10000,
n_parse_threads=5,
batch_size=32
):
######### pick multiple files randomly and read them simultaneously, interleaving交错 their records #########
# list_files() function returns a dataset that "shuffles" the file paths, then repeat 'repeat' times
dataset = tf.data.Dataset.list_files(filepaths).repeat(repeat)
# interleave() method to read from cycle_length(=n_readers) files at a time and
# "interleave their lines" (called cycle) : reading one line at a time from each until all datasets are out of items
# Then it will get the next five file paths from the 'dataset' and interleave them the same way,
# and so on until it runs out of file paths
dataset = dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1), # skip the header row via map_func
cycle_length=n_readers,# 'interleave' pull cycle_length(=n_readers) file paths(1 by 1) from the 'dataset'
num_parallel_calls=n_read_threads
)#and for each one(filepath) it will call the function you gave it(lambda) to create a new dataset(TextLineDataset)
#the interleave dataset including cycle_length(=n_readers) datasets
############## Then on top of that you can add a shuffling buffer using the shuffle() method ##############
dataset = dataset.shuffle(shuffle_buffer_size)
dataset = dataset.map(preprocess, #split and combine to form x_train and y_train, then scale
num_parallel_calls=n_parse_threads)
dataset = dataset.batch(batch_size)#group the items of the previous dataset in batches of 'batch_size' items
return dataset.prefetch(1)tf.random.set_seed(42)
train_set = csv_reader_dataset(train_filepaths, batch_size=3)
for X_batch, y_batch in train_set.take(2):
print('X =', X_batch)
print('y =', y_batch)
print() 3. During training, how can you tell that your input pipeline is the bottleneck? What can you do to fix it?
https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras
The Profile tab opens the Overview page which shows you a high-level summary of your model performance. Looking at the Step-time Graph on the right, you can see that the model is highly input bound (i.e., it spends a lot of time in the data input piepline). The Overview page also gives you recommendations on potential next steps you can follow to optimize your model performance.
You can use TensorBoard to visualize profiling data: if the GPU is not fully utilized then your input pipeline is likely to be the bottleneck. You can fix it by making sure it reads and preprocesses the data in multiple threads in parallel, and ensuring it prefetches a few batches. If this is insufficient to get your GPU to 100% usage during training, make sure your preprocessing code is optimized. You can also try saving the dataset into multiple TFRecord files, and if necessary perform some of the preprocessing ahead of time so that it does not need to be done on the fly during training (TF Transform can help with this). If necessary, use a machine with more CPU and RAM, and ensure that the GPU bandwidth is large enough.
https://blog.csdn.net/Linli522362242/article/details/107704824
# train_filepaths = save_to_multiple_csv_files( train_data, "train", header, n_parts=20 )
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(1),
])
optimizer = keras.optimizers.Nadam(lr=0.01)
loss_fn = keras.losses.mean_squared_error # returns one loss per instance(with few features)
@tf.function
def train(model, n_epochs, batch_size=32,
n_reader=5, n_read_threads=5, shuffle_buffer_size=10000, n_parse_threads=5):
train_set = csv_reader_dataset(train_filepaths,
repeat = n_epochs, # list_files() returns a dataset that "shuffles" the file paths, then repeat
n_readers=n_readers, # interleave() read from cycle_length files at a time
n_read_threads = n_read_threads,#num_parallel_calls
shuffle_buffer_size=shuffle_buffer_size, # shuffle
n_parse_threads=n_parse_threads, #map(preprocess, num_parallel_calls = n_parse_threads)
batch_size=batch_size, #batch()
#prefetch()
)
##############################################
n_steps_per_epoch = len(X_train) // batch_size # 11610 // 32 = 362 steps per epochs
total_steps = n_epochs * n_steps_per_epoch # if n_epochs=5, then total_steps=1810
global_step = 0
##############################################
for X_batch, y_batch in train_set.take(total_steps): # 11610//32 * 5 =1810 (taken times) # each time, take 32 instances
#tracking
global_step +=1
if tf.equal( global_step % 100, 0):
#'\r' moves the cursor ahead on current row
tf.print("\rGlobal step", global_step, "/", total_steps )
with tf.GradientTape() as tape:
y_pred = model(X_batch) # prediction
main_loss = tf.reduce_mean( loss_fn(y_batch, y_pred) )# returns a mean loss per batch
loss = tf.add_n([main_loss] + model.losses) #model.losses: there is one "regularization loss" per layer
# compute the gradient of the loss with regard to each trainable variable
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients( zip(gradients, model.trainable_variables))
######################## constraint ########################
train(model, 5)
4. Can you save any binary data to a TFRecord file, or only serialized protocol buffers?
A TFRecord file is composed of a sequence of arbitrary binary records: you can store absolutely any binary data you want in each record. However, in practice most TFRecord files contain sequences of serialized protocol buffers. This makes it possible to benefit from the advantages of protocol buffers, such as the fact that they can be read easily across multiple platforms and languages and their definition can be updated later in a backward-compatible way.
5. Why would you go through the hassle of converting all your data to the Example protobuf format? Why not use your own protobuf definition?
The Example protobuf format has the advantage that TensorFlow provides some operations to parse it (the tf.io.parse*example() functions) without you having to define your own format. It is sufficiently flexible to represent instances in
most datasets. However, if it does not cover your use case, you can define your own protocol buffer, compile it using protoc (setting the --descriptor_set_out and --include_imports arguments to export the protobuf descriptor), and use the tf.io.decode_proto() function to parse the serialized protobufs (see the “Custom protobuf ” section of the notebook for an example). It’s more complicated, and it requires deploying the descriptor along with the model, but it can be done.
########################################################################
https://blog.csdn.net/Linli522362242/article/details/107704824
First let's write a simple protobuf definition:
%%writefile person.proto
syntax = "proto3";
message Person{
string name =1;
int32 id=2;
repeated string email = 3;
}
Once you have a definition in a .proto file, you can compile it. This requires protoc, the protobuf compiler, to generate access classes in Python (or some other language).
And let's compile it (the --descriptor_set_out and --include_imports options are only required for the tf.io.decode_proto() example below):
所在的源目录 生成python代码(person_pb2.py)
!protoc person.proto --python_out=. --descriptor_set_out=person.desc --include_imports
!protoc person.proto --python_out=. --descriptor_set_out=person.desc --include_imports
!dir person* # !ls person* #note 'ls' is for linux system 
from person_pb2 import Person
person = Person(name='Al', id = 123, email=["[email protected]"]) # create a Person
print(person) # display the Person
person.email.append('[email protected]') # add an email address
s = person.SerializePartialToString()# serialize the object to a byte string
s![]()
person_tf = tf.io.decode_proto(
bytes=s,
message_type="Person",
field_names=["name", "id", "email"],
output_types=[tf.string, tf.int32, tf.string],
descriptor_source="person.desc"
)
person_tf
person_tf.values
Here is the definition of the tf.train.Example protobuf:
The numbers 1, 2, and 3 are the field identifiers: they will be used in each record’s binary representation
syntax = "proto3";
message BytesList { repeated bytes value = 1; }
message FloatList { repeated float value = 1 [packed = true]; }
message Int64List { repeated int64 value = 1 [packed = true]; }
message Feature {
oneof kind {
# The numbers 1, 2, and 3 are the field identifiers:
# they will be used in each record’s binary representation
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
message Features { map<string, Feature> feature = 1; };
message Example { Features features = 1; };Here is how you could create a tf.train.Example representing the same person as earlier and write it to a TFRecord file:
import tensorflow as tf
BytesList = tf.train.BytesList
FloatList = tf.train.FloatList
Int64List = tf.train.Int64List
Feature = tf.train.Feature
Features = tf.train.Features
Example = tf.train.Example
person_example = Example(
#message 'Example' { Features 'features' = 1; };
features = Features(
#message 'Features' { map<string, Feature> 'feature' = 1; };
feature={
#map<string, Feature>
"name": Feature( bytes_list=BytesList( value=[b"Alice"] ) ),
"id": Feature( int64_list=Int64List( value=[123] ) ),
"emails": Feature( bytes_list=BytesList( value=[b"[email protected]",
b"[email protected]"]
)
)
}
)
)Now that we have an Example protobuf, we can serialize it by calling its SerializeToString() method, then write the resulting data to a TFRecord file:
with tf.io.TFRecordWriter("my_contacts.tfrecord") as f:
f.write(person_example.SerializeToString())The following code defines a description dictionary, then it iterates over the TFRecord Dataset and parses(based on description) the serialized Example protobuf this dataset contains:
Instead of parsing examples one by one using tf.io.parse_single_example(), you may want to parse them batch by batch using tf.io.parse_example():
feature_description = {
# feature’s shape, type, and default value
"name": tf.io.FixedLenFeature([], tf.string, default_value=""),
"id": tf.io.FixedLenFeature([], tf.int64, default_value=0),
# only the type (if the length of the feature’s list may vary
"emails": tf.io.VarLenFeature(tf.string)
}
# for serialized_example in tf.data.TFRecordDataset(["my_contacts.tfrecord"]):
# parsed_example = tf.io.parse_single_example(serialized_example,
# feature_description)
# parsed_example
dataset = tf.data.TFRecordDataset(["my_contacts.tfrecord"]).batch(10)
for serialized_examples in dataset:
parsed_examples = tf.io.parse_example(serialized_examples, feature_description)
parsed_example
Handling Lists of Lists Using the SequenceExample Protobuf
Here is the definition of the SequenceExample protobuf:
syntax = "proto3";
message FeatureList { repeated Feature feature = 1; };
message FeatureLists { map<string, FeatureList> feature_list = 1; };
message SequenceExample {
Features context = 1;
FeatureLists feature_lists = 2;
};# from tensorflow.train import FeatureList, FeatureLists, SequenceExample
BytesList = tf.train.BytesList
Int64List = tf.train.Int64List
Feature = tf.train.Feature
Features = tf.train.Features
FeatureList = tf.train.FeatureList
FeatureLists = tf.train.FeatureLists
SequenceExample = tf.train.SequenceExample
# Features context = 1;
context = Features(
# message Features { map<string, Feature> feature = 1; };
feature={
# map<string, Feature>;
"author_id": Feature( int64_list=Int64List(value=[123]) ),
"title": Feature( bytes_list=BytesList(value=[b"A", b"desert", b"place", b"."]) ),
"pub_date": Feature( int64_list=Int64List(value=[1623, 12, 25]) ),
}
)
content = [["When", "shall", "we", "three", "meet", "again", "?"],
["In", "thunder", ",", "lightning", ",", "or", "in", "rain", "?"]
]
comments = [["When", "the", "hurlyburly", "'s", "done", "."],
["When", "the", "battle", "'s", "lost", "and", "won", "."]
]
# message Feature {
# oneof kind {
# BytesList 'bytes_list' = 1;
# FloatList 'float_list' = 2;
# Int64List 'int64_list' = 3;
# }
# };
def words_to_feature(words):
return Feature( bytes_list=BytesList( value=[word.encode("utf-8") for word in words] ) )
#repeated Feature feature =>[feature, feature] :each Feature would represent a sentence or comment
# feature=content_features
content_features = [words_to_feature(sentence) for sentence in content]
comments_features = [words_to_feature(comment) for comment in comments]
sequence_example = SequenceExample(
# Features 'context' = 1;
context = context,
# FeatureLists 'feature_lists' = 2;
feature_lists = FeatureLists(
# FeatureLists { map<string, FeatureList> feature_list = 1; };
feature_list={
# map<string, FeatureList>
# FeatureList { repeated Feature feature = 1; };
# Each FeatureList contains a list of Feature objects
"content": FeatureList( feature=content_features),
"comments": FeatureList( feature=comments_features)
}
)
)
sequence_example 

serialized_sequence_example = sequence_example.SerializePartialToString()context_feature_descriptions = {
"author_id": tf.io.FixedLenFeature([], tf.int64, default_value=0),
"title": tf.io.VarLenFeature(tf.string),
"pub_date": tf.io.FixedLenFeature([3], tf.int64, default_value=[0,0,0]),
}
sequence_feature_descriptions = {
"content": tf.io.VarLenFeature(tf.string),
"comments": tf.io.VarLenFeature(tf.string)
}
parsed_context, parsed_feature_lists = tf.io.parse_single_sequence_example(
serialized_sequence_example, context_feature_descriptions, sequence_feature_descriptions
)
parsed_context
print(
tf.RaggedTensor.from_sparse(parsed_feature_lists['content'])
)![]()
Putting Images in TFRecords
from sklearn.datasets import load_sample_images
import matplotlib.pyplot as plt
img = load_sample_images()['images'][0]
# encode an image using the JPEG format and put this binary data in a BytesList.
data = tf.io.encode_jpeg(img)
# message Example { Features features = 1; };
example_with_image = Example( features=Features(
# message Features { map<string, Feature> feature = 1; };
feature={
#map<string, Feature> #BytesList bytes_list = 1;
"image": Feature( bytes_list=BytesList( value=[data.numpy()] ) )
}))
serialized_example = example_with_image.SerializeToString()
# This is the binary data that is ready to be saved or transmitted over the network.
# then write the resulting data to a TFRecord filefeature_description = { 'image': tf.io.VarLenFeature(tf.string) }
example_with_image = tf.io.parse_single_example( serialized_example, feature_description )
# OR # decoded_img = tf.io.decode_image( example_with_image['image'].values[0]
decoded_img = tf.io.decode_jpeg( example_with_image['image'].values[0] )
plt.imshow(decoded_img)
plt.title("Decoded Image")
plt.axis("off")
plt.show()
########################################################################
6. When using TFRecords, when would you want to activate compression? Why not do it systematically?
When using TFRecords, you will generally want to activate compression if the TFRecord files will need to be downloaded by the training script, as compression will make files smaller and thus reduce download time. But if the files are located on the same machine as the training script, it’s usually preferable to leave compression off, to avoid wasting CPU for decompression.
7. Data can be preprocessed directly when writing the data files, or within the tf.data pipeline, or in preprocessing layers within your model, or using TF Transform. Can you list a few pros and cons of each option?
https://blog.csdn.net/Linli522362242/article/details/108108665