024 二分查找
漫画学习:https://baijiahao.baidu.com/s?id=1635498997846582026&wfr=spider&for=pc
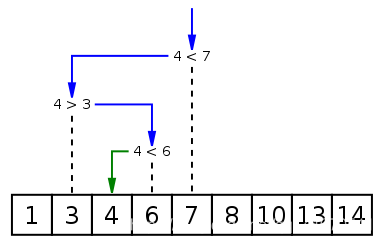
有序数组查找:二分查找:
小游戏:A在心里想一个范围[1, 1000]的数字,B来猜这个数,如果B猜的数字比A想的还要大,就说大看,如果B猜的数字比A想的要小,就说小了,一直到猜中为止。
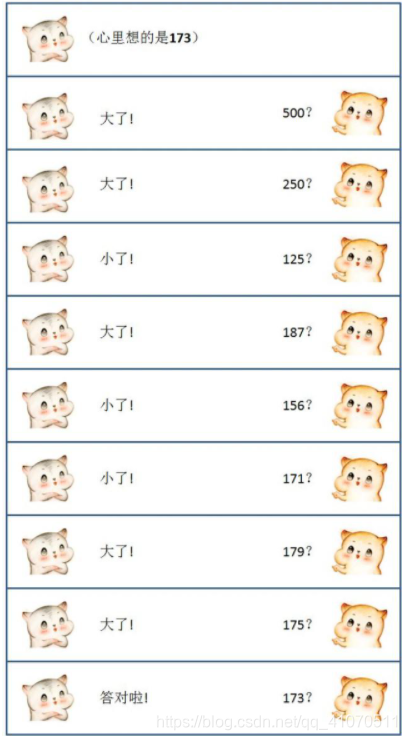
只用9次猜出1000以内的数字,这就是二分查找的思想,每次猜测,都选取一段整数范围的中位数,这样是效率最高效率。
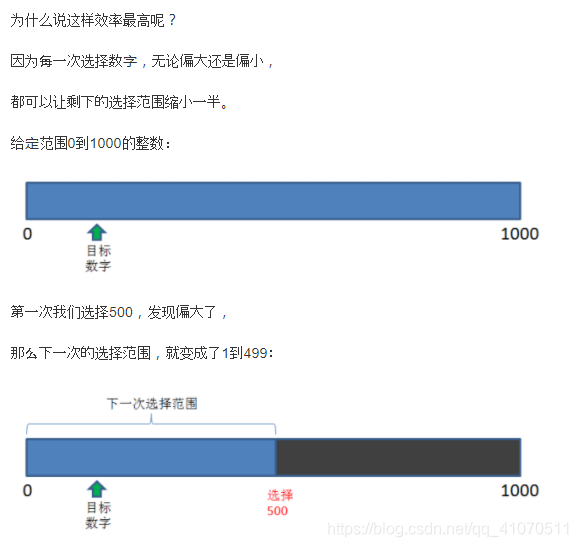

如果我们把场景转换成面试问题:
在包含1000个整型元素的有序数组中查找某个特定整数,
又该如何去做呢?
同样道理,
我们可以首先判断下标是499的元素(因为数组下标从0开始,到999结束),
如果元素大于要查找的整数,
我们再去判断下标是249的元素,
然后判断下标124的元素…
以此类推,直到最终找到想要的元素,
或者选择范围等于0为止。
上述这个过程,
就是所谓的二分查找算法,
查找的时间复杂度是log(n)。
#include<stdio.h>
#include<math.h>
void binary_search(int key, int a[], int n)
{
int low, high, mid, count = 0, count1 = 0; //count\记录查找次数,count1:记录有无查找成功!
low = 0;
high = n - 1;
while (low < high) //查找范围不为0时执行循环体语句
{
count++;
mid = (low + high) / 2;
if (key < a[mid])
{
high = mid - 1;
}
else if (key > a[mid])
{
low = mid + 1;
}
else if (key == a[mid])
{
printf("查找成功!\n 查找 %d 次! [%d] = %d", count, mid, key);
count1++;
break;
}
}
if (count1 == 0) //判断是否查找失败
{
printf("查找失败!\n"); //查找失败输出 no found.
}
}
main()
{
int a[100], i, key, n;
printf(" 请输入数组的长度\n ");
scanf_s("%d", &n);
printf(" 请输入10个数据\n ");
for (i = 1; i <= 10; i++) //输入数组
{
scanf_s(" %d", &a[i]);
}
printf(" 请输入你想查找的元素\n ");
scanf_s(" %d", &key);
binary_search(key, a, n);
printf(" \n ");
}
基本思想:
㈠、选取表中间位置的记录,将其关键字与给定关键字key进行比较,
——若相等,则查找成功;
——若key值比该关键字值大,则要找的元素一定在右子表中,则继续对右子表进行折半查找;
——若key值比该关键字值小,则要找的元素一定在左子表中,继续对左子表进行折半查找,
如此递推,直到查找成功/查找失败(查找范围为0)
025 分块查找
前提:
-
对于需要查找的待查数据元素列表来说,如果很少变化或者几乎不变,则我们完全可以通过排序把这个列表排好序以便我们以后查找。但是对于经常增加数据元素的列表来说,要是每次增加数据都排序的话,那真的是有点太累人了。
-
所以对于几乎不变的数据列表来说,排序之后使用**
二分查找**是很不错的,但是对于经常变动的数据元素列表来说,每次排序后再使用二分查找则不是很好的选择。
①、使用分块查找的原因:
对于需要经常增加或减少数据的数据元素列表,每次增加或减少数据之后排序,或者每次查找前排序都不是很好的选择,这样无疑会增加查找的复杂度,在这种情况下可以采用分块查找。
②、分块查找结构:
- 分块查找是结合二分查找和顺序查找的一种改进方法。
- 在分块查找里有
索引表和分块的概念。 索引表就是帮助分块查找的一个分块依据( 其实就是一个数组 )
,用来存储每块的最大存储值( 也就是范围上限 );分块就是通过索引表把数据分为几块。
③、分块查找小步骤:
-
在每需要增加一个元素的时候,
-
首先根据索引表,知道这个数据应该在哪一块,
-
然后直接把这个数据加到相应的块里面,而块内的元素之间本身不需要有序。因为块内无须有序,所以分块查找特别适合元素经常动态变化的情况。
-
分块查找只需要索引表有序
-
当索引表比较大的时候,可以对索引表进行二分查找,锁定块的位置
-
然后对块内的元素使用顺序查找。
-
这样的总体性能虽然不会比二分查找好,却比顺序查找好很多,最重要的是不需要数列完全有序。
④、分块查找原理:
分块查找要求把一个数据分为若干块,
每一块里面的元素可以是无序的,但是块与块之间的元素需要是有序的。
对于一个非递减的数列来说,第i块中的每个元素一定比第i-1块中的任意元素大。
同时,分块查找需要一个索引表——用来限定每一块的范围。在增加、删除、查找元素时都需要用到。
⑤、分块查找实现:
问: 一个已经分好块的数据,同时有个索引表,现在我们要在数据中插入一个元素,该怎么做?
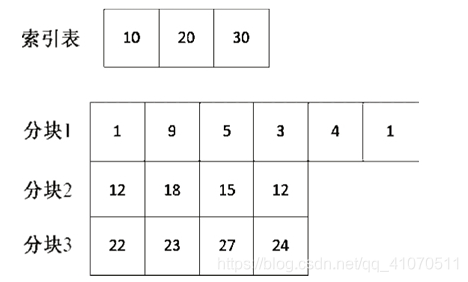
- 首先
插入元素,我们看到索引表是 10、20、30,对于元素 15 来说,应该将其放在分块 2 中。于是,分块 2 的数据变为 12、18、15、12、15,直接把 15 插入分块 2 的最后就好了。 - 接下来是
查找操作。如果要查找图 1 中的 27 这个数,则首先该怎么做呢?通过二分查找索引表,我们发现 27 在分块 3 里,然后在分块 3 中顺序查找,得到 27 存在于数列中。
例子:采用分块查找法在有序表11、12、18、28、39、56、69、89、96、122、135、146、156、256、298中查找关键字96 的元素,要求用户输入有序表各元素,
#include<stdio.h>
#include<math.h>
struct index
{
int key; //块的关键字
int start; //块的起始值
int end; //块的结束值
}index_table[4];
int block_search(int key, int a[])
{
int i, j;
i = 1;
while ((i <= 3) && (key > index_table[i].key)) //确定在哪块中
{
i++;
}
if (i > 3) //大于分的块数,则返回0
{
return 0;
}
j = index_table[i].start; //确定key在哪块的起始值
while (j <= index_table[i].end && a[j] != key) //在确定的块内顺序查找
{
j++;
}
if (j > index_table[i].end) //如果大于块范围的结束值,则说明没有要查找的数,
{
j = 0;
}
return j;
}
main()
{
int a[16], i, j = 0, key, k;
printf(" 请输入15个数据:\n ");
for (i = 1; i < 16; i++) //输入数组
{
scanf_s("%d", &a[i]);
}
for (i = 1; i <= 3; i++)
{
index_table[i].start = j + 1; //每个块范围的起始值
j = j + 1;
index_table[i].end = j + 4; //每块范围的结束值
j = j + 4;
index_table[i].key = a[j]; //确定每块范围元素的最大值
}
printf(" 请输入你想查找的元素: \n ");
scanf_s("%d", &key);
k = block_search(key, a);
if (k != 0)
{
printf(" 查找成功,其位置是:%d\n ", k);
}
else
{
printf(" 查找失败\n ");
}
printf(" \n ");
}
该例子给出15个数按关键字大小分成3块,这15个数的排列是一个有序序列(也可以是无序的),但必须满足分在第一块中的任意数都小于第二块中的所有数,第二块中的所有数都小于第3块中的所有数。当要查找关键字为key的元素时,先用顺序查找在已建好的索引表中查出key所在的块,再对应的块中顺序查找key,若存在,输出其相应位置,否则输出提示信息。
分块查找也称索引顺序查找,要求将待查的元素均匀地分成块,块间按大小排序,块内不排序,要建立一个块的最大(或最小)关键字表,即索引表。
026 哈希查找
哈希函数的构造方法:
- 数字分析法
- 平分取中法
- 分段叠加
- 伪随机数法
余数法(比较常用下列例子)
避免哈希冲突方法:
- 开放定址法(包括
线性探测再散列(比较常用)和二次探测再散列) - 链地址法
- 再哈希法
- 建立公共溢出区
例子:
编程实现哈希查找,要求:已知哈希表长度为11,哈希函数为H(key) = key % 11,随机产生待散列的小于50的8个元素,同时采用线性探测(—— 在冲突发生时,顺序查看表中的下一单元,直到找出一个空单元或查遍全表)再散列的方法处理冲突。任意输入要查找的数据,无论是否找到均给出提示信息。
假设随机数:43 23 10 25 30 28 17 21

#include<stdio.h>
#include<math.h>
#include<time.h>
#include<stdlib.h>
#define Max 11
#define N 8
int hashtable[Max];
int func(int value)
{
return value % Max; //哈希函数
}
//自定义函数实现哈希查找
int search(int key)
{
int pos, t;
pos = func(key);
t = pos;
while (hashtable[t] != key && hashtable[t] != -1)
{
t = (t + 1) % Max; //利用线性探测求出下一个位置
if (pos == t)
{
return -1;
}
}
if (hashtable[t] == -1)
{
return NULL;
}
else
{
return t;
}
}
void creathash(int key)
{
int pos, t;
pos = func(key);
t = pos;
while (hashtable[t] != -1) //如果该位置有元素存在
{
t = (t + 1) % Max;
if (pos == t) //如果冲突处理后确定的位置与原位置相同,则说明哈希表已经满
{
printf(" 哈希表已满\n ");
return;
}
}
hashtable[t] = key;
}
main()
{
int flag[50];
int i, j, t;
for (i = 1; i < Max; i++) //哈希表中,初始位置全置-1
{
hashtable[i] = -1;
}
for (i = 1; i < 50; i++) //50以内所有数未产生时,均标志为0
{
flag[i] = 0;
}
srand((unsigned long)time(0)); //利用系统时间做种子产生随机数
i = 0;
while (i != N)
{
t = rand() % 50; //不能产生一个50以内的随机数赋给t
if (flag[t] == 0) //查看是否产生t
{
creathash(t); //调用函数创建哈希表
printf("%2d: ", t);
for (j = 0; j < Max; j++)
{
printf("(%2d)", hashtable[j]); //输出哈希表内容
}
printf(" \n ");
flag[t] = 1; //将产生的这个数标志为1
i++;
}
}
printf("请输入你想要查找的元素");
scanf_s("%d", &t);
if (t > 0 && t < 50)
{
i = search(t);
if (j != -1)
{
printf(" 查找成功!其位置是:%d\n ", i);
}
else
{
printf(" 查找失败!");
}
}
else
printf(" 查找有误!\n ");
}
参考:
二分查找:
https://zh.wikipedia.org/wiki/%E4%BA%8C%E5%88%86%E6%90%9C%E5%B0%8B%E6%BC%94%E7%AE%97%E6%B3%95
https://baijiahao.baidu.com/s?id=1635498997846582026&wfr=spider&for=pc
分块查找:
http://data.biancheng.net/view/123.html