1、拿到数据咱们开始分析
我们拿到数据的时候,时间序列是数据主要分为四类,1.长期趋势。2.季节变动。3.循环变动 4.不规则数据。
给大家普及下(手动狗头):
1.长期趋势:
长期趋势是在很长时间实践按照某种特定趋势变化。简单来说,就是函数单调递减和函数单调递增。
2.季节变动:
由于自然条件和社会因素的影响,客观现象的统计数值在一年内出现的带有规律性的变化。
3.循环变动:
就是数据表现的是一个循环函数
4.不规则数据:
不规则变动是指由于意外的波动。而且这个意外是不经常的。
具体演示一下:

尴尬,俺看不出来。当然数据要根据具体应用场景去选择方法,当然我的方法不一定适用全部。
我这个是根据实际运用场景,直接选择了Arima算法。(终归只是算法而已,人是活的,不一定非得用某一种固定的算法)。
2、Arima
现在我们可以看到上面的数据并不平稳,当然咱们这样看只是我们直到了,计算机都不知道啊,所以必须得去测一下。
硬性基础知识
普及下时间序列平稳性:平稳性就是要求样本时间序列拟合的曲线在未来一段时间中顺着现有形态“惯性"的持续下去,平稳性要求序列的均值和方差不发生明显变化。
在Arima里有两个概念:
严平稳:分布不随时间的变化而变化,也就是说方差和期望都是不变的。
弱平稳:期望和相关系数(依赖性)是不变的,比如未来某时刻的Xt依赖于过去的数据,这就是依赖性。
ps:现实生活中严平稳太难,基本上弱平稳就好啦。
如果我们拿到数据不平稳怎么办?
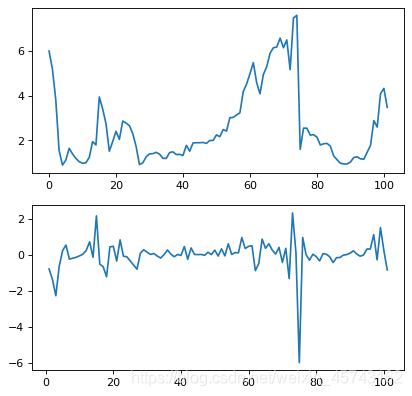
我们这时候就需要差分法:时间序列在t和t-1时刻的差值。
ps:如果我们有一组数据x1,x2,x3如果x1和x2平稳,x3不平稳这个适合我们需要把x1,x2,x3全部差分。
第一幅图是没有了的,第二幅图是差分了的:
代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 26 18:57:06 2020
@author: 13056
"""
import pandas as pd
import matplotlib.pyplot as plt
#导入数据
data =pd.read_csv(r'C:/Users/13056/Desktop/145.csv',encoding = 'gb2312')
data = data.drop(['日期'], axis=1)
#用subplot()方法绘制多幅图形
plt.figure(figsize=(6,6),dpi=80)
#创建第一个画板
plt.figure(1)
#将第一个画板划分为2行1列组成的区块,并获取到第一块区域
ax1 = plt.subplot(211)
#在第一个子区域中绘图
plt.plot(data.ds)
data['ds'] = data['ds'].diff(1)#进行差分
#选中第二个子区域,并绘图
ax2 = plt.subplot(212)
plt.plot(data.ds)
对于差分,给大家举个例子(今天操作系统复习完了,很闲)

应该很简单明了,一次差分就是做一次加减法。(时间序列差分了不还是时间序列嘛/手动狗头),上面那个diff()函数里面的数字,如diff(1)就是时间间隔1的数据做减法,如果是diff(2),就是时间间隔2的数据做减法。
Arima模型
这就是Ar+i+ma的结合咱们现在分开讲一下。
AR
AR是一个自回归模型
p阶自回归过程的公式:yt =μ+∑pi=1riyt-1+εt(其中yt是当前值,u是常数项,p是阶数,ri是自相关系数,εt是误差。
- 用过去的数据去预测未来的数据
- 满足平稳性要求
- 自相关系数ri起码得大于等于0.5(自相关系数度量的是同一事件在两个不同时期之间的相关程度)
MA
MA是一个移动平均模型(关注的是自回归模型中的误差项的累加)。
q阶自回归过程的公式:yt =μ+εt+∑qi=1θiεt-i
目的:有效消除预测过程中的随机波动。
ARMA
自回归移动平均模型,公式定义。
yt =μ+εt+∑qi=1θiεt-i+∑pi=1riyt-1
这里说明一下,p和q是我们自己指定的,我们需要用已有的数据去求θi和ri。i就是我们之前差分的那个差分项(简单来说就是第几个数据)。
ARIMA
ARIMA就是差分自回归移动平均模型。
我们一共需要指定的参数(p,q,d),p和q是自回归模型和移动平均模型的阶数,i就是差分了第几个。(这个阶数就是滞后值,一阶滞后就是模型的前一期值。)
如何选择p值和q值
自相关函数ACF
目的:看同一序列不同时序取值的相关性。
公式acf(k) = ρk = Cov(yt,yt-k)/Var(yt)
ρk的取值范围[-1,1],-1表示负相关,+1表示正相关,0是不相关。
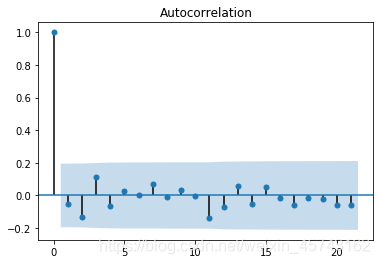
我画的ACF图:(自相关图是一个平面二维坐标悬垂线图。横坐标表示延迟阶数,纵坐标表示ACF值,横坐标表示延迟阶数,纵坐标表示偏自相关系数。那个蓝色区域是置信区间,正常取95%)简单来说横坐标那个k然后表示的数据自然就是t-k个数据表示的信息。
代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 26 18:57:06 2020
@author: 13056
"""
import pandas as pd
from statsmodels.graphics.tsaplots import plot_acf
data =pd.read_csv(r'C:/Users/13056/Desktop/145.csv',encoding = 'gb2312')
data = data.drop(['日期'], axis=1)
data['ds'] = data['ds'].diff(1)
data1 = data.ds.dropna()
plot_acf(data1)
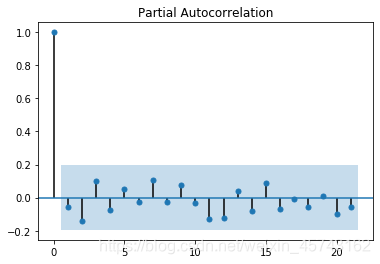
这里说一下偏自相关函数pacf,我们之前求的acf(k)并不是yt和yt-k之间单纯的相关关系,收到了很多东西的影响,包括t和t-k之间数据的影响,而pacf就可以无视这些影响,严格两个关系的相关性。(很复杂的东西,理解就行。)
画图:
代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 26 18:57:06 2020
@author: 13056
"""
import pandas as pd
from statsmodels.graphics.tsaplots import plot_pacf
data =pd.read_csv(r'C:/Users/13056/Desktop/145.csv',encoding = 'gb2312')
data = data.drop(['日期'], axis=1)
data['ds'] = data['ds'].diff(1)
data1 = data.ds.dropna()
plot_pacf(data1)
建立Arima模型
我们现在需要求(p,d,q),d我们就不说了= =就是差分几阶。
| 模型 | acf | pacf |
|---|---|---|
| AR( p) | 衰减趋于0 | p阶后截尾 |
| MA( q) | q阶后截尾 | 衰减趋于0 |
| ARMA( p,q) | q阶后截尾衰减趋于0 | p阶后截尾衰减趋于0 |
再看看我们的pacf那个图,从第2个(1阶)开始进入置信区,也就是AR模型在这里取的p为1。此时数据需要在acf上需要衰减趋于0。
我们再看看acf那个图,从第2个(1阶)开始进入置信区,所以说MA模型在这里取的q为1。
此时数据需要在pacf上需要衰减趋于0。
要是看不懂,还有一个方法 = =那就是暴力遍历!!!
流程:
- 将序列平稳(确定d)
- 求p,q
- 调用模型arima(p,d,q)
最后建立Arima模型的代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 26 18:57:06 2020
@author: 13056
"""
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
data =pd.read_csv(r'C:/Users/13056/Desktop/145.csv',encoding = 'gb2312')
data = data.drop(['日期'], axis=1)
data['ds'] = data['ds'].diff(1)
data1 = data.ds.dropna()
model = sm.tsa.ARIMA(data1, order=(1, 0, 0))
results = model.fit()
#后面就是(p,d,q)
resid = results.resid #赋值
fig = plt.figure(figsize=(12,8))
fig = sm.graphics.tsa.plot_acf(resid.values.squeeze())
plt.show()
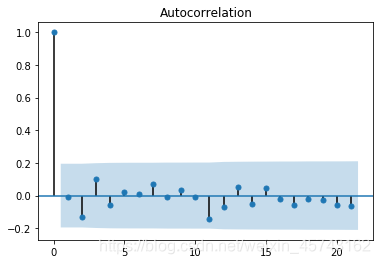
画出的图:
数据的确定
我们拿p和q的时候有时候得到的不仅仅是一组值,可能获得很多满足条件的值。
所以我们可以用另外的一个方法去找p和q值。
就是AIC和BIC的方法(值越小越好,k越小越好,l越大越好。)
AIC(赤池信息准则):AIC = 2k - 2ln(l)
BIC(贝叶斯信息准则):AIC = kln(n) - 2ln(l)
k是模型参数个数,n是样本数量,l是似然函数
BIC的例子:
# BIC准则
results_bic = pd.DataFrame(index=['AR{}'.format(i) for i in range(p_min,p_max+1)],
columns=['MA{}'.format(i) for i in range(q_min,q_max+1)])
for p,d,q in itertools.product(range(p_min,p_max+1),
range(d_min,d_max+1),
range(q_min,q_max+1)):
if p==0 and d==0 and q==0:
results_bic.loc['AR{}'.format(p), 'MA{}'.format(q)] = np.nan
continue
try:
model = sm.tsa.ARIMA(data1, order=(p, d, q),
#enforce_stationarity=False,
#enforce_invertibility=False,
)
results = model.fit()
results_bic.loc['AR{}'.format(p), 'MA{}'.format(q)] = results.bic
except:
continue
results_bic = results_bic[results_bic.columns].astype(float)
fig, ax = plt.subplots(figsize=(10, 8))
ax = sns.heatmap(results_bic,
mask=results_bic.isnull(),
ax=ax,
annot=True,
fmt='.2f',
)
ax.set_title('BIC')
plt.show()
结果:
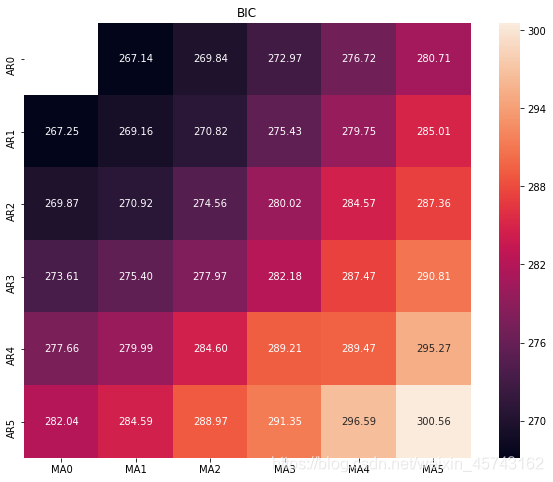
这个热力图的值越低越好= =
其实还有一个办法求:
train_results = sm.tsa.arma_order_select_ic(train, ic=['aic', 'bic'], trend='nc', max_ar=8, max_ma=8)
print('AIC', train_results.aic_min_order)
print('BIC', train_results.bic_min_order)
最后我们需要检查一下模型的残差是否为平均值为0且方差为常数的正态分布。
我上面代码是有这一步的:
model = sm.tsa.ARIMA(train, order=(1, 1, 1))
results = model.fit()
resid = results.resid #赋值
fig = plt.figure(figsize=(12,8))
fig = sm.graphics.tsa.plot_acf(resid.values.squeeze())
plt.show()
模型预测
我这只是一个例子,得到的结果并不咋地。
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 26 18:57:06 2020
@author: 13056
"""
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
data =pd.read_csv(r'C:/Users/13056/Desktop/145.csv',encoding = 'gb2312')
data = data.drop(['日期'], axis=1)
data['ds'] = data['ds'].diff(1)
data1 = data.ds.dropna()
model = sm.tsa.ARIMA(data1, order=(1, 1, 1))
results = model.fit()
#后面就是(p,d,q)
resid = results.resid #赋值
predict_sunspots = results.predict(start=1,end=101,dynamic=False)
plt.plot(data1)
plt.plot(predict_sunspots)
plt.show()
结果:
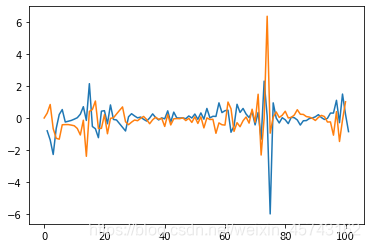
或者是获得结果:
results.forecast()[0]
Out[46]: array([0.16628989])
等写到了用这个项目的时候再给张好看的图叭。