索引的建立与删除
建立索引
在SQL语言中,建立索引使用 CREATE INDEX 语句,其一般形式为
CREATE [UNIQUE][CLUSTER] INDEX <索引名>
ON <表名>(<列名> [<次序>][,<列名> [次序]] ...);
次序 可选ASC(升序)*、DESC(降序)
UNIQUE 表明此索引的每一个索引值只对应唯一的数据记录
CLUSTER 表示要建立的索引是聚簇索引
例3.13:为学生–课程数据库中的Student、Course、SC三个表建立索引
Student表按照学号升序建立唯一索引
Course表按课程号升序建立唯一索引
SC表按学号升序和课程号降序建立唯一索引
建立索引前:
CREATE UNIQUE INDEX Stusno ON Student(Sno);
CREATE UNIQUE INDEX Coucno ON Course(Cno);
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);
建立索引后:

需要添加的索引添加完成!
CREATE (UNIQUE) INDEX 索引名 ON 表名(列名 排列方式,…);
修改索引
修改索引使用 ALTER INDEX 语句,一般格式为
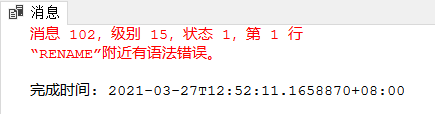
ALTER INDEX <旧索引名> RENAME TO <新索引名>;
例3.14:将SC表的SCno索引名改为SCSno

ALTER INDEX SCno RENAME TO SCSno;
然而…
通过在网上查询,我们可以使用:
EXEC sp_rename 'SC.SCno','SCSno','INDEX';
//此处不使用EXEC也是可以的
//个人推测EXEC是为创建了另一进程来该索引名,加快运行速度吧

删除索引
删除索引一般是用 DROP INDEX 语句,一般格式为:
DROP INDEX <索引名>
例3.15:删除Student表的Stusname索引:
运行前:

DROP INDEX Student.Stusno;
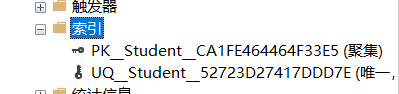
删除成功!
删除某一索引名,必须要添加对应的表名
数据更新
插入数据
SQL的数据插入语句INSERT通常有两种形式,一种是插入一个元组,另一种是插入子查询结果。后者可以一次插入多个元组
插入元组
插入元组的INSERT语句格式为:
INSERT
INTO <表名> [(<属性列1> [,<属性列2 >…)]
VALUES (<常量1> [,<常量2>]… );
其功能是将新元组插入指定表中。
其中新元组的属性列1的值为常量1,属性列2的值为常量2…
INTO 子句中没有出现的属性列,新元组在这些列上将取空值
例3.69:将一个新学生组(学号:201215128,姓名:陈冬,性别:男,所在系:IS,年龄:18岁)插入到Student表中:
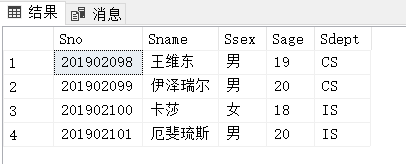
INSERT
INTO Student(Sno,Sname,Ssex,Sdept,Sage)
VALUES('201215128','陈冬','男','IS','18');
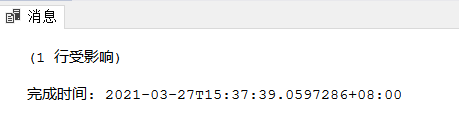
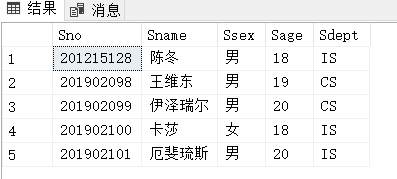
例3.70:将学生张成民的信息插入到Student表中:
INSERT
INTO Student
VALUES('201215126','张成民','男','18','CS');
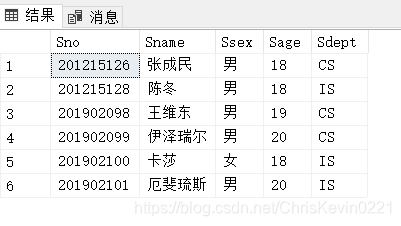
例3.71:插入一条选课记录((‘201215128’,‘1’):
INSERT
INTO SC(Sno,Cno)
VALUES('201215128','1');
等价于==:
INSERT
INTO SC
VALUES('201215128','1',NULL);
插入子查询结果
子查询不仅可以嵌套在SELECT语句中用以构造父查询的条件,也可以嵌套在INSERT语句中用以生成要插入的批量数据
插入子查询的语句格式为:
INSERT
INTO <表名> [(属性列1) [,<属性列2>...]]
子查询;
例3.72:对每一个系,求学生的平均年龄,并把结果存入数据库
首先在数据库中定义一个新表,其中一列存放系名,另一列存放相应的学生平均年龄
CREATE TABLE Dept_age
(Sdept CHAR(15)
Avg_age SMALLINT);
然后对Student表按系分组求平均年龄,再把系名和平均年龄放入新表中
INSERT
INTO Dept_age(Sdept,Avg_age)
SELECT Sdept,AVG(Sage)
FROM Student
GROUP BY Sdept;
修改数据
修改数据又称更新操作,一般格式为
UPDATE <表名>
SET <列名>=<表达式> [,<列名>=<表达式>]...
[WHERE <条件>];
eg1:将学生201215121的年龄改为22岁
UPDATE Student
SET Sage=22
WHERE Sno='201215121';
eg2:将所有学生的年龄增加1岁
UPDATE Student
SET Sage=Sage+1;
如果没有修饰条件,可以省略where语句,默认即为全部
eg3:将计算机科学系全体学生的成绩置0
UPDATE SC
SET Grade=0
WHERE Sno IN(
SELECT Sno
FROM Student
WHERE Sdept='CS'
);
删除数据
删除语句的一般格式为:
DELETE
FROM <表名>
[WHERE <条件>]
eg1:删除学号201215128的学生记录
DELETE
FROM Student
WHERE Sno='201215128';
eg2:删除所有学生的选课记录
DELETE
FROM SC;
eg3:删除计算机科学系所有学生的选课记录
DELETE
FROM SC
WHERE Sno IN(
SELECT Sno
FROM Student
WHERE Sdept='CS'
);
数据查询
单表查询
SELECT [ALL|DISTINCT] <目标列表达式>[,<目标列表达式>] …
FROM <表名或视图名>[,<表名或视图名> ]…|(SELECT 语句)
[AS]<别名>
[ WHERE <条件表达式> ]
[ GROUP BY <列名1> [ HAVING <条件表达式> ] ]
[ ORDER BY <列名2> [ ASC|DESC ] ]
语句含义是:
根据WHERE子句的条件表达式从FROM子句指定的基本表、视图、派生表中找出满足条件的元组,再按SELECT子句中的目标列表达式选出元组中的属性值形成结果表
如果有GROUP BY子句,则将结果按列表1的值进行分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数。如果GROUP BY子句带有HAVING短语,则只有满足指定条件的组才予以输出
如果有ORDER BY子句,则结果表还要按列名2的值的升序或降序排序
SELECT语句既可以完成简单的单表查询,也可以完成复杂的链接查询和嵌套查询。
例3.16:查询全体学生的学号与姓名:
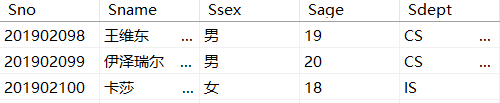
SELECT Sno,Sname
FROM Student;
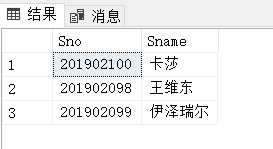
例3.17:查询全体学生的姓名、学号、所在系:
SELECT Sname,Sno,Sdept
FROM Student;
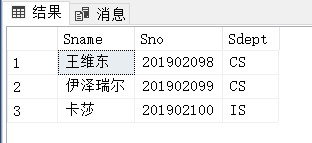
例3.18:查询全体学生的详细信息:
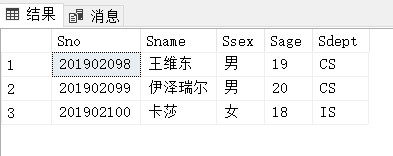
查询经过计算的值
SELECT 子句的<目标列表达式>不仅可以是表中的属性列,也可以是表达式
例3.19:查询全体学生的姓名及其出生月份:
SELECT Sname,2020-Sage
FROM Student;
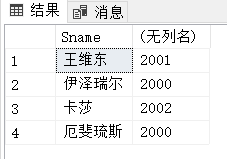
例3.20:查询全体学生的姓名、出生月份和所在院系,要求用小写字母表示系名:
SELECT Sname,"Year of birth:",2021-Sage,LOWER(Sdept)
FROM Student;
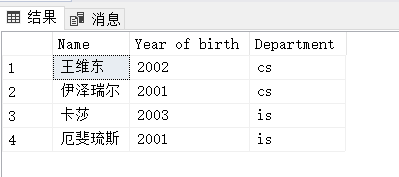
用户可以通过指定别名来改变查询结果的列标题
列名+‘ ’+列标题,…
选择表中的若干元组
例3.21:查询选修了课程的学生学号:
执行下列语句,可能会出现重复的行
SELECT Sno
FROM SC;
而添加一个DISTINCT即可去重
SELECT DISTINCT Sno
FROM SC;