思路:

解法1.abab 变为abababab 去头与去尾看看是否存在s 若存在s说明有重复的字符串
class Solution:
def repeatedSubstringPattern(self, s: str) -> bool:
new_s= s+s
return s in new_s[1:-1]c++:
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string new_str;
new_str = s + s;
for(int i=1; i<new_str.size() - s.size();i++){
if (new_str.substr(i, s.size()) == s){
return true;
}
}
return false;
}
};解法2.kmp算法
构造s+s作为主字符串,s作为模板字符串,再利用kmp即可。

思路:整数→二进制数→替换‘0’和‘1’→整数
class Solution:
def bitwiseComplement(self, N: int) -> int:
# res = []
# for bin_i in bin(N)[2:]:
# if int(bin_i):
# res.append('0')
# else:
# res.append('1')
# print(res)
# print('0b'+''.join(res))
# return int('0b'+''.join(res),2)
return int('0b'+''.join('0' if int(bin_i) and 1 else '1' for bin_i in bin(N)[2:]), 2)

思路:让n-1个元素加1等于让一个元素-1
代码:
class Solution:
def minMoves(self, nums: List[int]) -> int:
moves = 0
nums = sorted(nums)
for i in range(len(nums)):
moves+=nums[i]-nums[0]
return moves
思路:找尾数是0也就是除于10,10可以拆成5*2,通过找规律可以知道出现2的次数比5多,也就变成了找5的个数
class Solution:
def trailingZeroes(self, n: int) -> int:
res= 0
while n>0:
n = n//5
res +=n
return res
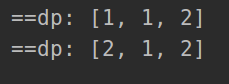
思路:j是 拆分的第一个数字,i-j就是剩下的,求i的最大等价于求i-j的最大,故状态转移方程为:max(j*(i-j),j*dp[i-j])
1.dp解法
#dp[i] = max(j*(i-j),j*dp[i-j])
class Solution:
def integerBreak(self, n):
dp = [0 for i in range(n+1)]
# print('==dp:', dp)
for i in range(n+1):#
value = 0
for j in range(i):#循环去确定i的时候的最大值
value = max(value, max(j*(i-j), j*dp[i-j]))
dp[i] = value
# print('==dp:', dp)
return dp[-1]
sol = Solution()
res = sol.integerBreak(n=10)
print('res:', res)2.递归解法
class Solution:
def integerBreak(self, n):
if n<=1:
return 0
if n == 2:
return 1
res = 0
for i in range(2, n):
res = max(res, max(i*(n-i), i*self.integerBreak(n-i)))
return res
sol = Solution()
res = sol.integerBreak(n=35)
print('res:', res)解法一:数学解法
class Solution:
def findErrorNums(self, nums: List[int]) -> List[int]:
count = sum(set(nums))
return [sum(nums)-count, len(nums)*(len(nums)+1)//2 - count]解法二:位运算
def findErrorNums(nums):
res = 0
length = len(nums)
err = sum(nums) - sum(set(nums)) # 重复
print('err:', err)
for n in nums:#求出非重复数之和
res ^= n
print('res:', res)
for i in range(1, length + 1):#求出重复数之前的值
res ^= i
print('==res:', res)
miss = err ^ res#求出缺失值
print('===miss:', miss)
return [err, miss]
nums = [1, 2, 2, 4]
findErrorNums(nums)
思路:动态规划,找到状态方程dp[i]=max(nums[i]+dp[i-1], nums[i])
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
dp = [0 for i in range(len(nums))]
# print('===dp', dp)
dp[0] =nums[0]
for i in range(1, len(nums)):
dp[i] = max(nums[i], dp[i-1]+nums[i])
# print('==dp:', dp)
return max(dp)class Solution:
def maxSubArray(self, nums: List[int]) -> int:
if len(nums)==0:
return []
res = nums[0]
for i in range(1,len(nums)):
nums[i] = max(nums[i], nums[i] + nums[i-1])
res = max(nums[i], res)
return resclass Solution:
def maxSubArray(self, nums: List[int]) -> int:
if len(nums)==0:
return []
value = nums[0]
res = nums[0]
for i in range(1,len(nums)):
value = max(nums[i], value + nums[i])
res = max(value, res)
return res一百一十一:编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。

思路:找到值最大的一行的左下角,如果值小就减少行,值大就增加列.
class Solution:
def searchMatrix(self, matrix, target):
"""
:type matrix: List[List[int]]
:type target: int
:rtype: bool
"""
if len(matrix)<=0:
return False
if len(matrix[0])<=0:
return False
h = len(matrix)
w = len(matrix[0])
col, row = 0, h - 1
#先找到最大值的一行 左下脚
while row >= 0 and col < w:
if target>matrix[row][col]:
col+=1
elif target < matrix[row][col]:
row-=1
else:
return True
return False
思路:排序 取前几个k值即可.
class Solution:
def smallestK(self, arr: List[int], k: int) -> List[int]:
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
return quicksort(arr)[:k]python最小堆,所以用负数 时间复杂度o(nlogk)
import heapq
class Solution:
def smallestK(self, arr, k):
nums = []
heapq.heapify(nums)
for i in range(k):
heapq.heappush(nums, -arr[i])
print('==nums:', nums)
for i in range(k, len(arr)):
heapq.heappush(nums, -arr[i])
heapq.heappop(nums)
print('=nums:', nums)
res = [-num for num in nums]
print('==res:', res)
return res
arr = [1,3,5,7,2,4,6,8]
k = 4
sol = Solution()
sol.smallestK(arr, k)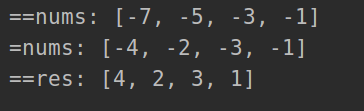

class Solution:
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
nums_of_station = len(gas)
total_ = 0
curent_= 0
st_station = 0
for i in range (nums_of_station):
total_ +=gas[i] - cost[i]
curent_ +=gas[i] - cost[i]
if curent_<0:
st_station=i+1
curent_=0
return st_station if total_>=0 else -1
思路:找到相邻的字母,对其相应的损失取最小相加,注意的是碰到小的值要进行交换,否则会拿小的值再次计算和.
class Solution:
def minCost(self, s, cost):
price = 0
for i in range(len(s)-1):
if s[i] == s[i+1]:
price += min(cost[i], cost[i+1])
if cost[i] > cost[i+1]:#碰到小的值进行交换 不交换的话会拿小的值再一次进行相加
cost[i], cost[i+1] = cost[i+1], cost[i]
# print('==price', price)
return price
# s = "abaac"
# cost = [1, 2, 3, 4, 5]
s = "aaabbbabbbb"
cost = [3, 5, 10, 7, 5, 3, 5, 5, 4, 8, 1]
# s = "aabaa"
# cost = [1, 2, 3, 4, 1]
sol = Solution()
price = sol.minCost(s, cost)
print('=price:', price)
思路:两个指针分别指向两个列表,进行值的比较,将小的值放进列表,最后在看指针有没有走完
class Solution(object):
def merge(self, nums1, m, nums2, n):
"""
:type nums1: List[int]
:type m: int
:type nums2: List[int]
:type n: int
:rtype: None Do not return anything, modify nums1 in-place instead.
"""
nums1_copy = nums1[:m]
nums1[:] = []
# 双指针法
p1 = 0
p2 = 0
#将小的值放进res
while p1 < m and p2 < n:
if nums1_copy[p1] < nums2[p2]:
nums1.append(nums1_copy[p1])
p1 += 1
else:
nums1.append(nums2[p2])
p2 += 1
# 在把剩下的元素进行添加
if p1 < m:
nums1[p1 + p2:] = nums1_copy[p1:]
if p2 < n:
nums1[p1 + p2:] = nums2[p2:]
return nums1
思路:利用桶计数对每个字符建立桶,进行左右扫描直到都为空
方法1:
class Solution:
def sortString(self, s):
#构建每个字符的桶 用于计数
barrel = [0]*26
for i in s:
barrel[ord(i)-97] += 1
# print('==barrel:', barrel)
res = []
while True:
if any([barrel[i] for i in range(26)]):#退出条件 如果所有桶的字符都为0
for i in range(len(barrel)):#从小到大加字符
if barrel[i]>0:
barrel[i]-=1
res.append(chr(i+97))
# print('res:', res)
# print('==barrel:', barrel)
for i in range(len(barrel)-1, -1, -1):#从大到小加字符
if barrel[i]>0:
barrel[i]-=1
res.append(chr(i+97))
else:
break
# print('res:', res)
return ''.join(res)
sol = Solution()
s = "aaaabbbbcccc"
res = sol.sortString(s)
print('res:', res)方法2:利用collections
import collections
class Solution:
def sortString(self, s):
chars=collections.Counter(s)
print(chars)
ans=[]
signal=0
while chars:
group=list(chars)
print('==group:', group)
group.sort(reverse=signal)
print('====group:', group)
ans.extend(group)
print('====collections.Counter(group):',collections.Counter(group))
chars-=collections.Counter(group)
print('===chars:', chars)
signal=1-signal
return ''.join(ans)
sol = Solution()
s = "aaaabbbbcccc"
res = sol.sortString(s)120.字符串压缩

思路:从左到右遍历字符串,开出两个变量,一个用于计数,一个用于更新字符
class Solution(object):
def compressString(self, S):
"""
:type S: str
:rtype: str
"""
if len(S)==0:
return ''
S_start = S[0]#将字符串中的第一个字符作为开始字符串
cnt = 0
res = ''
for i in range(len(S)):
if S[i] == S_start: # 等于开始字符就进行计数
cnt += 1
else:
res += S_start + str(cnt)#碰到不等于的字符 将字符开头和出现次数加入结果集合
S_start = S[i]#重新更新开始字符串
cnt = 1#重新计数
# print('res:', res)
res += S_start + str(cnt)
# print('res:', res)
return S if len(res) >= len(S) else res
思路: 1. 回文字符串特点 奇数 偶数都只找一半即可
2. 对于前半部分如果发现不为a的替换成a即可 否则说明前半部分都是a这个时候就将后半部分变为b即可
class Solution(object):
def breakPalindrome(self, palindrome):
"""
:type palindrome: str
:rtype: str
"""
if len(palindrome) <= 1:
return ''
# 回文字符串特点 奇数 偶数都只找一半即可
# 对于前半部分如果发现不为a的替换成a即可 否则说明前半部分都是a这个时候就将后半部分变为b即可
for i in range(len(palindrome) // 2):
if palindrome[i] != 'a':
return palindrome[:i]+'a'+palindrome[i+1:]
return palindrome[:-1]+'b'
#思路:通过双指针来遍历找到是否在dictionary,开辟一个列表用于计数未识别的字符数
# 利用字典key的特性方便进行判断
class Solution(object):
def respace(self, dictionary, sentence):
#思路:通过双指针来遍历找到是否在dictionary,开辟一个列表用于计数未识别的字符数
# 利用字典key的特性方便进行判断
dict_ = {}
for dictionary_str in dictionary:
dict_[dictionary_str] = ''
print('===dict_:', dict_)
opt = (len(sentence)+1) * [0]
print('==opt:', opt)
for i in range(1, len(sentence)+1):#加1 是因为要走到最后来判断是否在字典里面
opt[i] = opt[i - 1] + 1
for j in range(i):
if sentence[j:i] in dict_:
opt[i] = min(opt[i], opt[j])
print('==opt:', opt)
return opt[-1]
sol = Solution()
# dictionary = ["haha", "look"]
# sentence = "hahhahalookme"
# dictionary = ["h"]
# sentence = "aaa"
dictionary = ["looked", "just", "like", "her", "brother"]
sentence = "jesslookedjustliketimherbrother"
sol.respace(dictionary, sentence)
思路:第一位数字有9种可能性,后面的数字分别有两种可能性,故对于一个5位数字,有9*2^4种可能性,故直接遍历即可
class Solution(object):
def numsSameConsecDiff(self, n, k):
"""
:type n: int
:type k: int
:rtype: List[int]
"""
"""
:type n: int
:type k: int
:rtype: List[int]
"""
if n == 1:
return [0]
res = [i for i in range(1, 10)]
for i in range(n - 1):
temp = []
for j in res:
d = j % 10
if d - k >= 0:
temp.append(10 * j + d - k)
if d + k <= 9:
temp.append(10 * j + d + k)
print('==temp:', temp)
res = temp
return list(set(res))
N = 3
K = 2
sol = Solution()
sol.numsSameConsecDiff(N, K)

思路1:bfs 将为0的坐标存入队列,在对上下左右斜等8个方向用bfs进行遍历,需要注意的是遍历过为0的点需要更新为-1,代表已经遍历过了,否则会陷入无限循环
class Solution(object):
def pondSizes(self, land):
"""
:type land: List[List[int]]
:rtype: List[int]
"""
res = []
rows = len(land)
columns = len(land[0])
for i in range(rows):
for j in range(columns):
if land[i][j] == 0: # 找到水域
land[i][j] = -1 # 将访问的点标记进行标记
quene = []
quene.append([i, j])
temp_water_num = 1
while len(quene) > 0:
x, y = quene.pop(0)
directions = [[x, y - 1], [x, y + 1], [x - 1, y - 1], [x - 1, y],
[x - 1, y + 1], [x + 1, y - 1], [x + 1, y], [x + 1, y + 1]]
for new_x, new_y in directions:
# print('==new_x, new_y :', new_x, new_y)
if 0 <= new_x < len(land) and 0 <= new_y < len(land[0]) and land[new_x][new_y] == 0:
temp_water_num += 1
quene.append([new_x, new_y])
land[new_x][new_y] = -1 # 将访问的点标记进行标记
res.append(temp_water_num)
print('==res:', res)
return sorted(res)
sol = Solution()
land = [[0, 2, 1, 0],
[0, 1, 0, 1],
[1, 1, 0, 1],
[0, 1, 0, 1]]
sol.pondSizes(land)
思路2:递归 对经过的0进行更新替换 每掉一次递归 就用一个变量+1 记录水域的个数
class Solution:
def helper(self, i, j, h, w):
if i < 0 or i >= h or j < 0 or j >= w or self.land[i][j] != 0:
return
self.temp += 1
self.land[i][j] = -1
self.helper(i - 1, j, h, w)
self.helper(i + 1, j, h, w)
self.helper(i, j-1, h, w)
self.helper(i, j+1, h, w)
self.helper(i-1, j - 1, h, w)
self.helper(i-1, j + 1, h, w)
self.helper(i+1, j - 1, h, w)
self.helper(i+1, j + 1, h, w)
def pondSizes(self, land):
self.land = land
h = len(self.land)
w = len(self.land[0])
res = []
for i in range(h):
for j in range(w):
if self.land[i][j] == 0:
self.temp = 0
self.helper(i, j, h, w)
res.append(self.temp)
# print(res)
return sorted(res)
land = [
[0,2,1,0],
[0,1,0,1],
[1,1,0,1],
[0,1,0,1]
]
sol = Solution()
res = sol.pondSizes(land)
print('==res:', res)
思路:n=0有一位, n=1有10位,n=2 有 9*9位 n=3有9*9*8 n=4有9*9*8*7 大于10位就固定了
class Solution(object):
def countNumbersWithUniqueDigits(self, n):
"""
:type n: int
:rtype: int
"""
# n=0有一位, n=1有10位,n=2 有 9*9位 n=3有9*9*8 n=4有9*9*8*7 大于10位就固定了
if n == 0:
return 1
temp = 9
k = 9
res = 10
for i in range(1, min(n, 10)):
temp *= k
res += temp
k -= 1
print('res:', res)
return res
sol = Solution()
n = 10
sol.countNumbersWithUniqueDigits(n)

思路:一个子集中的最大数能够被整数 这个子集中的其他数就不需要在除了 故先对数字进行排序 依次找子集 最后返回最长的子集即可
class Solution(object):
def largestDivisibleSubset(self, nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
if len(nums)==0:
return []
nums = sorted(nums)
opt = [[num] for num in nums]
for i in range(len(nums)):
for j in range(i-1, -1, -1):
if nums[i]%nums[j]==0:# 整数满足除于子集中的最大值余数为0 则将整数加入子集
if len(opt[j])+1>len(opt[i]):
opt[i] = opt[j]+[nums[i]]
# print('===opt:',opt)
return max(opt, key=len)

思路:对于偶数指数一分为2即可, 对于奇数指数一分为2 在乘以底数即可
#思路:对于偶数指数一分为2即可, 对于奇数指数一分为2 在乘以底数即可
class Solution(object):
def myPow(self, x, n):
"""
:type x: float
:type n: int
:rtype: float
"""
# 2^5= 2^2 * 2^2 *2
# 2^4= 2^2 * 2^2
def get_power(x, n):
# 递归终止条件
if n == 0:
return 1
if x == 1:
return 1
# print('===r:', r)
if n % 2 == 0: # 偶数的情况
# 二分法的一半
r = get_power(x, n / 2) # 分
return r * r # 合
else: # 奇数的情况
r = get_power(x, (n - 1) / 2) # 分
return r * r * x # 合
if n > 0:
res = get_power(x, n)#指数为正
else:
res = 1 / get_power(x, -n)#指数为负
return res
sol = Solution()
x = 2.00000
n = 2
res = sol.myPow(x, n)
print('==res:', res)
思路:其实就是查找第一个值,利用双指针,故左指针与右指针不会相遇,对于左指针更新采用middle+1,而右指针为middle即可.
# The isBadVersion API is already defined for you.
# @param version, an integer
# @return a bool
# def isBadVersion(version):
class Solution:
def firstBadVersion(self, n):
"""
:type n: int
:rtype: int
"""
#二分查找
left,right = 1,n
while left<right:
middle = left + (right - left)//2
if isBadVersion(middle):
right = middle
else:
left = middle+1
return left

思路:双指针遍历即可
class Solution:
def search(self, nums: List[int], target: int) -> int:
left,right = 0,len(nums)-1
while left<=right:
middle = left + (right-left)//2
if nums[middle]==target:
return middle
elif nums[middle]<target:
left = middle+1
else:
right = middle-1
return -1
思路:利用动态规划存储 上升序列的值
class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
if len(nums)==0:
return 0
dp = len(nums)*[0]
dp[0] = 1
for i in range(1, len(nums)):
value = 0
for j in range(i):
if nums[i]>nums[j]:
value = max(value, dp[j])
dp[i] = value+1
# print('==dp:',dp)
return max(dp)事先先把dp存储值为1
class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
if len(nums)==0:
return 0
dp = len(nums) * [1]
for i in range(1, len(nums)):
for j in range(i):
if nums[i] > nums[j]:
dp[i] = max(dp[i], dp[j]+1)
# print('==dp:', dp)
return max(dp)
思路:
1. 当s中单词数和pattern长度不相同时,直接可以判断为不匹配
2. 当s中单词数和pattern长度相同时:
# 以pattern中的单词作为key,以str中的元素作为value。遍历pattern,s,
# 当pattern中的单词未出现过时,判断其是否在字典中的key值出现过:
# 若是,则判断其对应的value是否出现过,若冲突返回不匹配;
#若否,判断是否出现在字典中的value:若是,返回不匹配;若否,加入字典.
class Solution(object):
def wordPattern(self, pattern, s):
"""
:type pattern: str
:type str: str
:rtype: bool
"""
s = s.split(' ')
if len(pattern)!=len(s):#s的长度与pattern不一样就返回False
return False
dic_ = {}
for i, x in enumerate(s):
# print('==dic_:', dic_)
if pattern[i] not in dic_:
# print('==dic_.values():', dic_.values())
if x in dic_.values():
return False
dic_[pattern[i]] = x
else:
if x != dic_[pattern[i]]:
return False
return True
# pattern = "abba"
# s = "dog cat cat dog"
pattern = "abba"
s = "dog dog dog dog"
sol = Solution()
res = sol.wordPattern(pattern, s)
print('==res:', res)144.三角形的最大周长

思路:两边之和大于第三边,可以从小到大排序,尽可能选最长边.
class Solution:
def largestPerimeter(self, A: List[int]) -> int:
A =sorted(A)
#三角形满足两边之和大于第三边
for i in range(len(A)-3, -1, -1):
if A[i]+A[i+1]>A[i+2]:
return A[i]+A[i+1]+A[i+2]
return 0
class Solution(object):
def maxSubArray(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
opt = [0]*len(nums)
opt[0] = nums[0]
for i in range(1,len(nums)):
opt[i] = max(opt[i-1]+nums[i],nums[i])
return max(opt)class Solution:
def maxSubArray(self, nums: List[int]) -> int:
if len(nums)==0:
return []
res = nums[0]
for i in range(1,len(nums)):
nums[i] = max(nums[i], nums[i] + nums[i-1])
res = max(nums[i], res)
return resclass Solution:
def maxSubArray(self, nums: List[int]) -> int:
if len(nums)==0:
return []
value = nums[0]
res = nums[0]
for i in range(1,len(nums)):
value = max(nums[i], value + nums[i])
res = max(value, res)
return res
思路:单调栈
class Solution(object):
def removeKdigits(self, num, k):
"""
:type num: str
:type k: int
:rtype: str
"""
#单调栈
stack = []
for digit in num:
while k and stack and stack[-1]>digit:
stack.pop()
k -= 1
stack.append(digit)
# print('==stack:', stack)
final_stack = stack[:-k] if k else stack
return "".join(final_stack).lstrip('0') or "0"
思路:贪心算法得到末端最小的数
class Solution(object):
def eraseOverlapIntervals(self, intervals):
"""
:type intervals: List[List[int]]
:rtype: int
"""
if len(intervals)==0:
return 0
intervals = sorted(intervals,key=lambda x:x[-1])
# print('intervals', intervals)
res = [intervals[0]]
for interval in intervals[1:]:
if res[-1][-1] <= interval[0]:
res.append(interval)
else:
pass
# print('res:',res)
return len(intervals) - len(res)
思路1:不断合并更新列表即可以
class Solution:
def insert(self, intervals, newInterval):
intervals.append(newInterval)
# print('==intervals:', intervals)
intervals = sorted(intervals, key=lambda x: (x[0], x[1]))
print('==intervals:', intervals)
index = 0
while index < len(intervals) - 1:
print('==index:', index)
print('==intervals:', intervals)
# 合并删除
if intervals[index][1] >= intervals[index + 1][0]:
intervals[index][1] = max(intervals[index][1], intervals[index + 1][1])
intervals.pop(index + 1)
else:
index += 1
return intervals
# intervals = [[1, 3], [6, 9]]
# newInterval = [2, 5]
intervals = [[1, 2], [3, 5], [6, 7], [8, 10], [12, 16]]
newInterval = [4, 8]
sol = Solution()
sol.insert(intervals, newInterval)思路2:开出一个新列表用于存储满足的即可
class Solution:
def insert(self, intervals, newInterval):
intervals.append(newInterval)
# print('==intervals:', intervals)
intervals = sorted(intervals, key=lambda x: (x[0], x[1]))
print('==intervals:', intervals)
merge = []
for interval in intervals:
if len(merge) == 0 or interval[0] > merge[-1][-1]:
merge.append(interval)
else:
merge[-1][-1] = max(merge[-1][-1], interval[-1])
print(merge)
return merge
# intervals = [[1, 3], [6, 9]]
# newInterval = [2, 5]
intervals = [[1, 2], [3, 5], [6, 7], [8, 10], [12, 16]]
newInterval = [4, 8]
sol = Solution()
sol.insert(intervals, newInterval)

思路:两层for循环取出相应的值和剩下的值进行递归即可.
class Solution:
def backtrace(self, n1, n2, rest):
sum_ = str(int(n1)+int(n2))
if sum_ == rest:#找到满足的条件
return True
if len(sum_) > len(rest) or rest[:len(sum_)] != sum_:#找到不满足的条件
return False
else:
return self.backtrace(n2, sum_, rest[len(sum_):])
def isvalid_num(self, value):
"""以0开头,例如01,065"""
return len(value) > 1 and value[0] == '0'
def isAdditiveNumber(self, num):
if len(num) < 3:
return False
for i in range(1, len(num)):# 找到第一个数:num[:i]
for j in range(i + 1, len(num)):# 找到第二个数:num[i:j]
n1, n2, rest = num[:i], num[i:j], num[j:]# 剩下的数
# print('==n1, n2, rest:', n1, n2, rest)
if self.isvalid_num(n1) or self.isvalid_num(n2) or self.isvalid_num(rest): # 避免0开头的非0数
continue
if self.backtrace(n1, n2, rest):
return True
return False
num = "112358"
sol = Solution()
res = sol.isAdditiveNumber(num)
print('res:', res)
思路:BFS遍历每个节点
"""
# Definition for a Node.
class Node:
def __init__(self, val = 0, neighbors = None):
self.val = val
self.neighbors = neighbors if neighbors is not None else []
"""
class Solution:
def cloneGraph(self, node: 'Node') -> 'Node':
if not node:
return node
visited = {}#存储遍历过的节点
visited[node] = Node(node.val, [])
quene = [node]
while quene:
pop_node = quene.pop()
for neighbor in pop_node.neighbors:
if neighbor not in visited:#没有遍历过
visited[neighbor] = Node(neighbor.val, [])
quene.append(neighbor)
# 更新当前节点的邻居列表
visited[pop_node].neighbors.append(visited[neighbor])
return visited[node]

思路:从边界的'O'回退,找到依次相邻的O则不动,否则置为'X'
# 从边界的'O'回退,找到依次相邻的O则不动,否则置为'X'
class Solution:
def helper(self, i, j, h, w):
if not 0 <= i < h or not 0 <= j < w or self.board[i][j] != 'O':
return
self.board[i][j] = 'F'
self.helper(i - 1, j, h, w)
self.helper(i + 1, j, h, w)
self.helper(i, j-1, h, w)
self.helper(i, j+1, h, w)
def solve(self, board):
"""
Do not return anything, modify board in-place instead.
"""
self.board = board
h, w = len(self.board), len(self.board[0])
for i in range(h):
self.helper(i, 0, h, w)
self.helper(i, w - 1, h, w)
print('==self.board:', self.board)
for j in range(1, w-1):
self.helper(0, j, h, w)
self.helper(h-1, j, h, w)
print('==self.board:', self.board)
for i in range(h):
for j in range(w):
if self.board[i][j] == "F":
self.board[i][j] = "O"
elif self.board[i][j] == "O":
self.board[i][j] = "X"
print('==self.board:', self.board)
return self.board
board = [["X", "X", "X", "X"],
["X", "O", "O", "X"],
["X", "X", "O", "X"],
["X", "O", "X", "X"]]
# board = [["X", "X", "X"],
# ["X", "O", "O"],
# ["X", "X", "O"],
# ["X", "O", "X"]]
sol = Solution()
sol.solve(board)

思路:当成 0 1背包问题来做,只不过这道题需要两个背包一个是装0的,一个是装1的,求在装满的时候的最大字符串量
使用i为止这个字符串 j个0 k个1 能够容纳的最多字符串
dp[i][j][k] = dp[i-1][j][k] 不选这个字符串
dp[i][j][k] = dp[i-1][j-cnt[0]][k-cnt[1]] 选这个字符串 cnt[0]代表0的个数 cnt[1]代表1的个数
代码1:需要初始化第一个字符串的dp
import numpy as np
class Solution:
def count(self, str_):
cnt= [0, 0]
for i in str_:
cnt[int(i) - 0] += 1
return cnt
def findMaxForm(self, strs, m, n):
dp = [[[0 for _ in range(n+1)] for _ in range(m+1)] for _ in range(len(strs))]
print(np.array(dp).shape)
cnt = self.count(strs[0])
#对第一件物品进行初始化
for j in range(m+1):
for k in range(n+1):
dp[0][j][k] = 1 if j >= cnt[0] and k >= cnt[1] else 0
print(np.array(dp).shape)
for i in range(1, len(strs)):
# print('==strs[i]:', strs[i])
cnt = self.count(strs[i])
print('==cnt', cnt)
for j in range(m+1):
for k in range(n+1):
if (j - cnt[0])<0 or (k - cnt[1])<0:
dp[i][j][k] = dp[i - 1][j][k]
else:
dp[i][j][k] = max(dp[i-1][j][k], dp[i - 1][j - cnt[0]][k - cnt[1]]+1)
print(np.array(dp))
return dp[len(strs)-1][m][n]
strs = ["10", "0001", "111001", "1", "0"]
m = 5#0
n = 3#1
sol = Solution()
res= sol.findMaxForm(strs, m, n)
print('res:',res)

代码2:多生成一个字符串空间dp,就不需要初始化第一个字符串
# 使用i为止这个字符串 j个0 k个1 能够容纳的最多字符串
# dp[i][j][k] = dp[i-1][j][k] 不选这个字符串
# dp[i][j][k] = dp[i-1][j-cnt[0]][k-cnt[1]] 选这个字符串
import numpy as np
class Solution:
def count(self, str_):
cnt= [0, 0]
for i in str_:
cnt[int(i) - 0] += 1
return cnt
def findMaxForm(self, strs, m, n):
dp = [[[0 for _ in range(n+1)] for _ in range(m+1)] for _ in range(len(strs)+1)]
print(np.array(dp).shape)
for i in range(1, len(strs)+1):
# print('==strs[i]:', strs[i])
cnt = self.count(strs[i-1])
print('==cnt', cnt)
for j in range(m+1):
for k in range(n+1):
if (j - cnt[0])<0 or (k - cnt[1])<0:
dp[i][j][k] = dp[i - 1][j][k]
else:
dp[i][j][k] = max(dp[i-1][j][k], dp[i - 1][j - cnt[0]][k - cnt[1]]+1)
print(np.array(dp))
return dp[len(strs)][m][n]
181.两地调度问题

1.贪心算法未优化版
# 贪心算法:
#思路:对AB两地的费用之差绝对值排序,利用贪心算法选择最小费用的城市,当最小费用的城市人满了以后,剩下的人就去另外一个城市
class Solution:
def twocitycost(self, costs):
# 对差值进行排序
costs = sorted(costs, key=lambda x: abs(x[0] - x[1]), reverse=True)
print('==costs:', costs)
total_cost = 0
toA, toB = 0, 0
every_city_person = len(costs) // 2
for i, cost in enumerate(costs):
if toA < every_city_person and toB < every_city_person:
if cost[0] < cost[-1]: # A地未去满同时A地的费用最小
toA = +1
total_cost += cost[0]
else: # B地未去满同时B地的费用最小
toB = +1
total_cost += cost[-1]
elif toA<every_city_person:#B地满了
toA+=1
total_cost = cost[0]
else:#A地满了
toB += 1
total_cost = cost[-1]
print('==total_cost:', total_cost)
return total_cost
2.贪心算法优化版
#优化版
#思路:对AB两地的费用之差排序,自然前面的人费用最小 后面的人费用最大
class Solution:
def twocitycost(self, costs):
# 对差值进行排序
costs = sorted(costs, key=lambda x: x[0] - x[1])
print('==costs:', costs)
total_cost = 0
every_city_person = len(costs) // 2
for i in range(every_city_person):
total_cost+=costs[i][0]+costs[i+every_city_person][-1]
print('==total_cost:', total_cost)
return total_cost
costs = [[10, 20], [30, 200], [400, 50], [30, 20]]
sol = Solution()
sol.twocitycost(costs)
思路:归并排序中的并
#思路:归并排序中的并
class Solution:
def merge(self, nums1, m, nums2, n):
"""
Do not return anything, modify nums1 in-place instead.
"""
l, r = 0, 0
nums1_copy = nums1[:m].copy()
nums1 = []
while l<len(nums1_copy) and r<len(nums2):
if nums1_copy[l]<nums2[r]:
nums1.append(nums1_copy[l])
l+=1
else:
nums1.append(nums2[r])
r+=1
nums1+=nums1_copy[l:]
nums1+=nums2[r:]
return nums1
nums1 = [1,2,3,0,0,0]
m = 3
nums2 = [2,5,6]
n = 3
sol = Solution()
res = sol.merge(nums1, m, nums2, n)
print('==res:', res)思路2:
class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
"""
Do not return anything, modify nums1 in-place instead.
"""
res = []
i, j = 0, 0
while i < m and j < n:
if nums1[i]<nums2[j]:
res.append(nums1[i])
i += 1
else:
res.append(nums2[j])
j += 1
for k in range(i, m):
res.append(nums1[k])
for k in range(j, n):
res.append(nums2[k])
nums1[:] = res
return nums1
思路:栈用来保存索引和相应的左右括号
class Solution:
def minRemoveToMakeValid(self, s):
stack = []
for i in range(len(s)):
# print('===s[i]==', s[i])
# print('==i, stack:', i, stack)
if s[i] == '(':
stack.append((i, '('))
elif s[i] == ')':
if len(stack) and stack[-1][-1]=='(':
stack.pop()
else:
stack.append((i, ')'))
else:
pass
# print('===stack', stack)
stack_index = [i[0] for i in stack]
res = ''
for i in range(len(s)):
if i not in stack_index:
res+=s[i]
# print('==res:', res)
return res
s = "a)b(c)d"
# s = "lee(t(c)o)de)"
# s = "))(("
sol = Solution()
sol.minRemoveToMakeValid(s)189.转置矩阵

思路1.开辟二维数组
import numpy as np
class Solution:
def transpose(self, A):
print(np.array(A))
rows = len(A)
cols = len(A[0])
res = [[0] * rows for _ in range(cols)]
print(np.array(res))
for i in range(rows):
for j in range(cols):
res[j][i] = A[i][j]
print(np.array(res))
return res
A = [[1,2,3],[4,5,6]]
sol = Solution()
res = sol.transpose(A)
print('==res:', res)思路2:用zip
class Solution:
def transpose(self, A: List[List[int]]) -> List[List[int]]:
return list(zip(*A))193.面试题 08.13. 堆箱子

思路:其实就是在找最长上升子序列 可以将箱子先从小到大排序 在寻找最长子序列
#dp[i] 代表以第 i 个箱子放在最底下的最大高度
class Solution:
def pileBox(self, box):
dp = [0]*len(box)
print('==dp:', dp)
box = sorted(box)
# print('=box:', box)
for i in range(len(box)):
dp[i] = box[i][-1]
for j in range(i):
if box[i][0] > box[j][0] and box[i][1] > box[j][1] and box[i][-1] > box[j][-1]:
dp[i] = max(dp[i], dp[j]+box[i][-1])
print('==dp:', dp)
return max(dp)
# box = [[1, 1, 1], [2, 2, 2], [3, 3, 3]]
box = [[1, 1, 1], [2, 3, 4], [3, 4, 5],[2, 6, 7]]
sol = Solution()
sol.pileBox(box)

198.字符串中的第一个唯一字符

思路:利用hash统计每个字符出现的个数,在判断hash中字符个数为1的字母,即找到
class Solution:
def firstUniqChar(self, s):
letter_num = {}
for i in s:
letter_num[i] = letter_num.get(i, 0) + 1
print('==letter_num:', letter_num)
for i in range(len(s)):
if letter_num.get(s[i]) == 1:
return i
print('==res:', res)
return -1
s = "loveleetcode"
# s = ""
# s = "cc"
sol = Solution()
sol.firstUniqChar(s)
199.分发糖果

思路:从左往右找递增 在从右往左找递增
class Solution:
def candy(self, ratings):
n = len(ratings)
dp = [0] * n
dp[0] = 1
#每个孩子至少一颗糖 从左往右 找递增的
for i in range(1, n):
if ratings[i] > ratings[i - 1]:
dp[i] = dp[i - 1] + 1
else:
dp[i] = 1
print('==dp:', dp)
#在从右往左 找递增的
for i in range(n - 2, -1, -1):
if ratings[i] > ratings[i + 1] and dp[i] <= dp[i+1]:#i的分比i+1高,同时i的糖还<=i+1的糖
dp[i] = dp[i+1] + 1
print('==dp:', dp)
return sum(dp)
ratings = [1, 0, 2]
# ratings = [1, 3, 4, 5, 2]
sol = Solution()
sol.candy(ratings)