手推公式,现场造轮子
kmeans
#coding=utf-8
def distance(pt1,pt2):
m=len(pt1)
ans=0
for i in range(m):
ans+=(pt1[i]-pt2[i])**2
return ans
# 构造样本
pts=[]
for i in range(10):
for j in range(10):
pts.append([i,j])
# 初始中心
centers=[[0,2],[3,3]]
k=len(centers)
m=2
# 迭代
print(centers)
for i in range(5):
# 给每个样本分配对应的标签
labels=[]
for pt in pts:
best_i=-1
best_dis=100000
for i, center in enumerate(centers):
dis=distance(pt,center)
if dis<best_dis:
best_i=i
best_dis=dis
labels.append(best_i)
# 重新计算中心点
cts=[[] for _ in range(k)]
centers=[[0]*m for _ in range(k)]
for pt,label in zip(pts, labels):
cts[label].append(pt)
for label in range(k):
n_samples=len(cts[label])
for dim in range(m):
sm=0
for sample in range(n_samples):
sm+=cts[label][sample][dim]
sm/=n_samples
centers[label][dim]=sm
print(centers)
print(labels)
logistic regression
主要背这几个代码
- 交叉熵
loss = -(y @ np.log(y_hat) + (1 - y) @ np.log(1 - y_hat)) / n
- y_hat 计算
就sigmoid
return 1 / (1 + np.exp(-X @ self.w))
- 梯度计算
dw = (y - y_hat) @ X
dw /= n
class LR:
def __init__(self, lr=0.1, max_iter=1000, eps=1e-5):
self.eps = eps
self.max_iter = max_iter
self.lr = lr
def predict_proba(self, X):
return 1 / (1 + np.exp(-X @ self.w))
def fit(self, X: np.ndarray, y: np.ndarray):
n, m = X.shape
X = np.hstack([X, np.ones([n, 1])])
m += 1
self.w = np.zeros([m])
pre_loss = 0
for i in range(self.max_iter):
y_hat = self.predict_proba(X)
# 交叉熵
loss = -(y @ np.log(y_hat) + (1 - y) @ np.log(1 - y_hat)) / n
if abs(loss - pre_loss) < self.eps:
print('误差不再减少')
break
pre_loss = loss
print(loss)
# 计算梯度
dw = (y - y_hat) @ X
dw /= n
# 梯度下降
self.w += dw * self.lr
print(self.w)
线性回归
手撕代码
挖井的问题(每个家庭都可以打井,成本为c[i],或者挖水管,i,j两家通水管成本为dp[i][j]。求所有家庭喝上水的最小成本)
输出数据库中满足四个要求的样本(具体要求忘记了,涉及到hash)
一个亿级别的数据,是地球上各个位置的温度,对该数组进行排序,时间复杂度O(n)。面试官非常nice,给了很多提示,最后写出来了…真是惭愧
计算机基础
python深拷贝和浅拷贝的问题
正则表达式
散列表
Python里面哈希表对应哪种结构,是如何解决哈希冲突的
哈希冲突的解决方法
Metric
AUC
随机给定一正一负两个样本,将正样本排在负样本之前的概率(等价与Wilcoxon-Mann-Witney Test),因此AUC越大,说明正样本越有可能被排在负样本之前,即分类额结果越好。
所以AUC反应的是分类器对样本的排序能力。
绘图/计算 方法
方法1
做法是由于每种样本出现的概率已知,将其由小到大进行排序,依次作为截断概率,小于该概率预测为负例,大于该概率预测为正例,这样每个样本都有一个预测值,可以计算出样本中的真阳率和假阳率,在坐标系上描点,然后依次改变截断概率,计算不同组的真假阳率,绘制出的曲线与横轴所夹的面积就是AUC
方法2
假设总共有(m+n)个样本,其中正样本m个,负样本n个,总共有mn个样本对,计数,正样本预测为正样本的概率值大于负样本预测为正样本的概率值记为1,累加计数,然后除以(mn)就是AUC的值
import numpy as np
from sklearn.metrics import roc_auc_score
def auc(labels, probs):
n_samples = len(labels)
pos_cnt = sum(labels)
neg_cnt = n_samples - pos_cnt
total_comb = pos_cnt * neg_cnt #组合数
pos_index = np.where(labels==1)[0] #找出正例的索引
neg_index = np.where(labels==0)[0] # 找出负例的索引
cnt = 0
for pos_i in pos_index:
for neg_j in neg_index:
if probs[pos_i] > probs[neg_j]:
cnt += 1
elif probs[pos_i] == probs[neg_j]:
cnt += 0.5
else:
cnt += 0
auc = cnt / total_comb
return auc
labels = np.array([1,1,0,0,1,1,0])
probs= np.array([0.8,0.7,0.5,0.5,0.5,0.5,0.3])
print('ours:', auc(labels,probs))
print('sklearn:', roc_auc_score(labels,probs))
方法3
把横轴的刻度间隔设置为1/N, 纵轴的刻度间隔设置为1/P; 再根据模型输出的预测概率对样本进行排序( 从高到低) ;
依次遍历样本, 同时从零点开始绘制ROC曲线, 每遇到一个正样本就沿纵轴方向绘制一个刻度间隔的曲线, 每遇到一个负样本就沿横轴方向绘制一个刻度间隔的曲线, 直到遍历完所有样本, 曲线最终停在( 1,1) 这个点, 整个ROC曲线绘制完成。
为什么ROC比PR对不均衡样本更鲁棒?
我们知道,当我们画ROC和PR曲线时,我们是分别以(FPR, TPR)和(Precision,Recall)绘点描线的。
因为在同样的TPR的情况下,它们的FPR差别比较小。但是它们的PR曲线差异是比较大的,因为在同样的TPR的情况下,它们的Precision差异是相当的大。
什么时候选择PR,什么时候选择ROC?
本质上,第一问中的差异在于ROC和PR关注的点是不一样的。ROC是同时关注对正负样本,PR只关注正样本。这个不难理解,因为TPR是衡量正样本,FPR是衡量负样本。但是,Precision和Recall都是衡量的正样本。
举例来说,对于预测癌症,我们会更喜欢PR,因为我们希望尽可能准的同时,尽可能多的预测出癌症患者,不要漏掉任何一个癌症患者。至于FPR,其实不那么重要,因为总是可以通过其他更多的手段进一步核实。
但是对于猫和狗的图片分类模型,我们会更喜欢ROC,因为将猫和狗都识别准确都是我们的目标,ROC同时关注了这两方面。
线性模型
L1不可导的时候怎么办
当损失函数不可导,梯度下降不再有效,可以使用坐标轴下降法,梯度下降是沿着当前点的负梯度方向进行参数更新,而坐标轴下降法是沿着坐标轴的方向,假设有m个特征个数,坐标轴下降法进参数更新的时候,先固定m-1个值,然后再求另外一个的局部最优解,从而避免损失函数不可导问题。
使用Proximal Algorithm对L1进行求解,此方法是去优化损失函数上界结果# 概率统计
概率统计
概率题:甲、乙两个人轮流吃糖,每一轮吃到的概率为1/2,,先吃到的赢;甲赢的概率。有两颗糖,甲吃到糖个数的期望
2 3 \frac{2}{3} 32
期望不会
某疾病发病概率1/1000,患者有95%的概率检测出患病,健康者有5%的概率被误诊,问若一个人被检测出患病,实际患病概率是多少。
贝叶斯公式
各种rand花式转换
class Solution {
public:
int rand10() {
int row,col,idx;
do{
row=rand7();
col=rand7();
idx=col+(row-1)*7;
}while(idx>40);
return 1+(idx-1)%10;
}
};
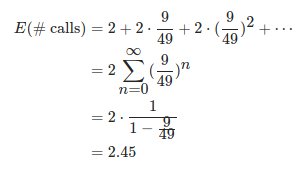
- rand5 实现 rand7
class Solution {
public:
int rand7() {
int row,col,idx;
do{
row=rand5();
col=rand5();
idx=col+(row-1)*5;
}while(idx>21);
return 1+(idx-1)%7;
}
};
期望:
2 ⋅ 1 1 − 4 25 2\cdot \frac{1}{1-\frac{4}{25}} 2⋅1−2541
- rand11实现rand7
这个比较诡异,我理解相当于只有一行
最大似然估计和最大后验概率的区别
最大似然估计提供了一种给定观察数据来评估模型参数的方法,而最大似然估计中的采样满足所有采样都是独立同分布的假设。
最大后验概率是根据经验数据获难以观察量的点估计,与最大似然估计最大的不同是最大后验概率融入了要估计量的先验分布在其中,所以最大后验概率可以看做规则化的最大似然估计
什么是共轭先验分布
假设为总体分布中的参数,的先验密度函数为,而抽样信息算得的后验密度函数与具有相同的函数形式,则称为的共轭先验分布
0~1均匀分布的随机器如何变化成均值为0,方差为1的随机器

均匀分布产生正态分布
反函数法
一般,一种概率分布,如果其分布函数为 y = F ( x ) y=F(x) y=F(x),那么,y的范围是0~1,求其反函数 G G G,然后产生0到1之间的随机数作为输入,那么输出的就是符合该分布的随机数了:
y = G ( x ) y= G(x) y=G(x)
中心极限定理
import numpy as np
import pylab as plt
n = 12
N = 5000
x = np.zeros([N])
for j in range(N):
a = np.random.rand(n)
u = sum(a)
x[j] = u - n * 0.5
plt.hist(x)
plt.show()
Box Muller
import numpy as np
import pylab as plt
N = 1000
x1 = np.random.rand(1, N)
x2 = np.random.rand(1, N)
y1 = np.sqrt(-2 * np.log(x1)) * np.cos(2 * np.pi * x2)
y2 = np.sqrt(-2 * np.log(x1)) * np.sin(2 * np.pi * x2)
y = np.hstack([y1, y2])
plt.hist(y)
plt.show()
37%定律
一个活动,n个女生手里拿着长短不一的玫瑰花,无序的排成一排,一个男生从头走到尾,试图拿更长的玫瑰花,一旦拿了一朵就不能再拿其他的,错过了就不能回头,问最好的策略?