工欲善其事,必先利其器
首先要先安装好scrapy框架包,参考https://blog.csdn.net/m0_46202060/article/details/106201764
1.Scrapy框架的基本操作
使用Scrapy框架制作爬虫一般需要以下四个步骤:
(1)新建项目:创建一个新爬虫项目 scrapy startproject ***
(2)明确目标:明确要爬取的目标 scrapy genspider 爬虫名称 “爬虫域”
(3)制作爬虫:制作爬虫,开始爬取网页 scrapy crawl 爬虫名称
(4)储存数据:储存爬取内容 scrapy crawl 爬虫名称 -o json/xml/jsonl/csv
(1) 新建项目
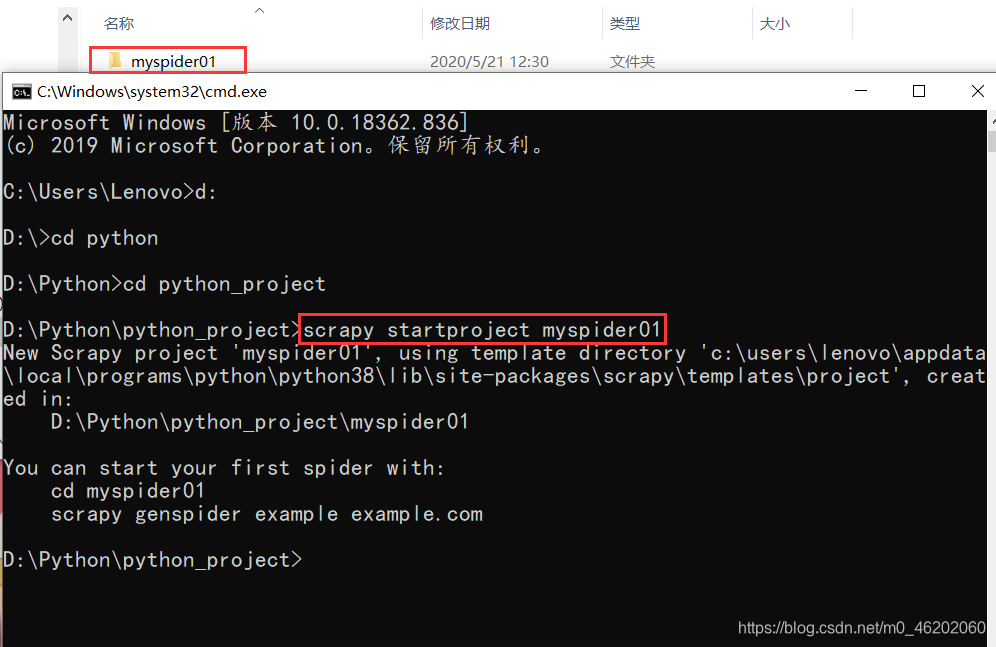
打开cmd,创建一个新项目:
scrapy startproject myspider01
(2)明确目标 (爬取新闻标题、时间、出版社)
首先切换到刚刚创建的工程路径下
scrapy genspider xinwen "news.sina.com.cn"
注意:“ ” 中内容必须为网址形式

然后我们打开pycharm查看:
这里自动生成了若干文件和目录
spiders:储存爬虫代码的目录
scrapy.cfg:配置文件
items.py:用于定义项目的目标实体

(3)制作爬虫
1.将地址更换为你想要爬取的网页地址
2.用xpath爬取网页内容
import scrapy
from myspider01.items import Myspider01Item
class XinwenSpider(scrapy.Spider):
name = 'xinwen'
allowed_domains = ['new.sina.com.cn']
start_urls = ['https://news.sina.com.cn/gov/xlxw/2020-05-20/doc-iircuyvi4073201.shtml']
def parse(self, response):
item = Myspider01Item()
item['title'] = response.xpath('//*[@id="top_bar"]/div/div[1]/text().extract()[0]')
item['time'] = response.xpath('//*[@id="top_bar"]/div/div[2]/span[1]/text().extract()[0]')
item['source'] = response.xpath('//*[@id="top_bar"]/div/div[2]/span[2]/text().extract()[0]')
yield item
3.extract()方法返回的是对应的字符串列表

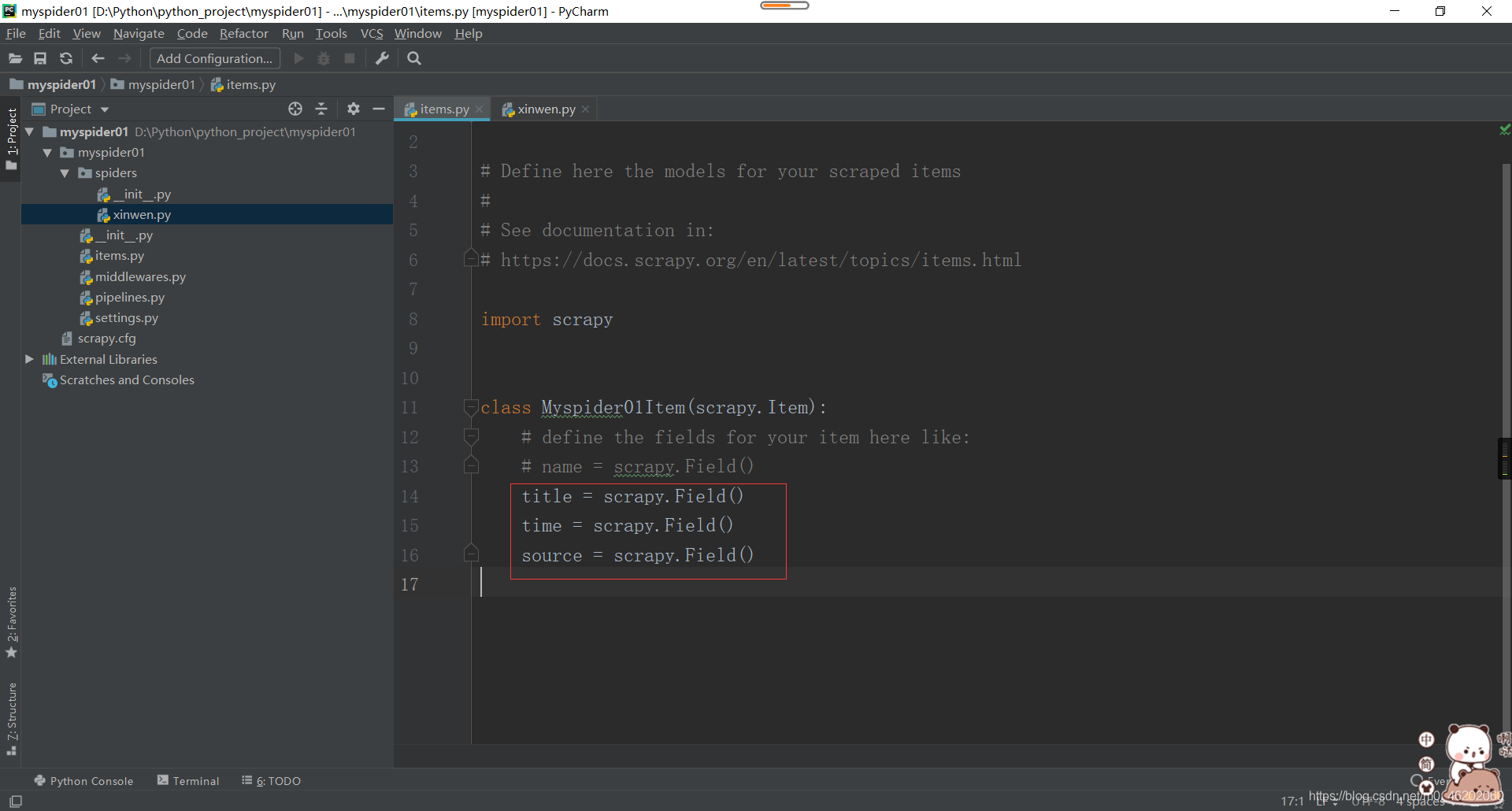
3.在items中添加对应属性title、time、source,分别表示新闻的标题、时间、来源
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Myspider01Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
source = scrapy.Field()
扫描二维码关注公众号,回复:
13002633 查看本文章

4.在myspider01项目中创建一个main文件,用于执行语句
from scrapy import cmdline
cmdline.execute('scrapy crawl xinwen'.split())

这样就成功用scrapy框架将新闻爬取下来了!
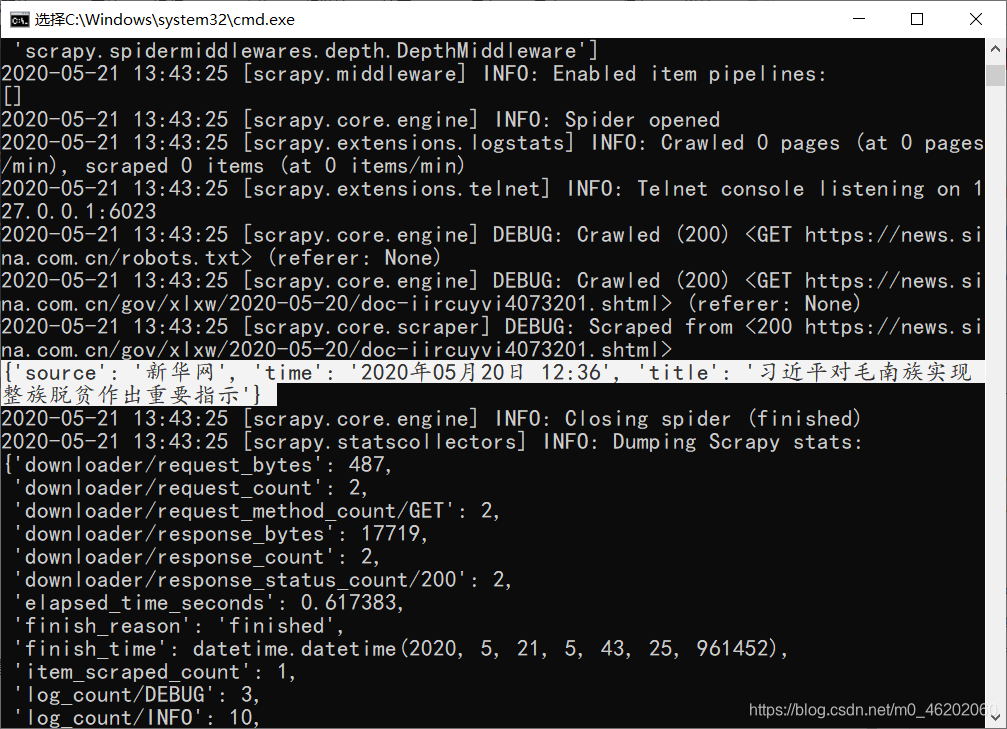
另外,也可以直接在cmd命令行中直接运行,我们来看一下效果
scrapy crawl xinwen
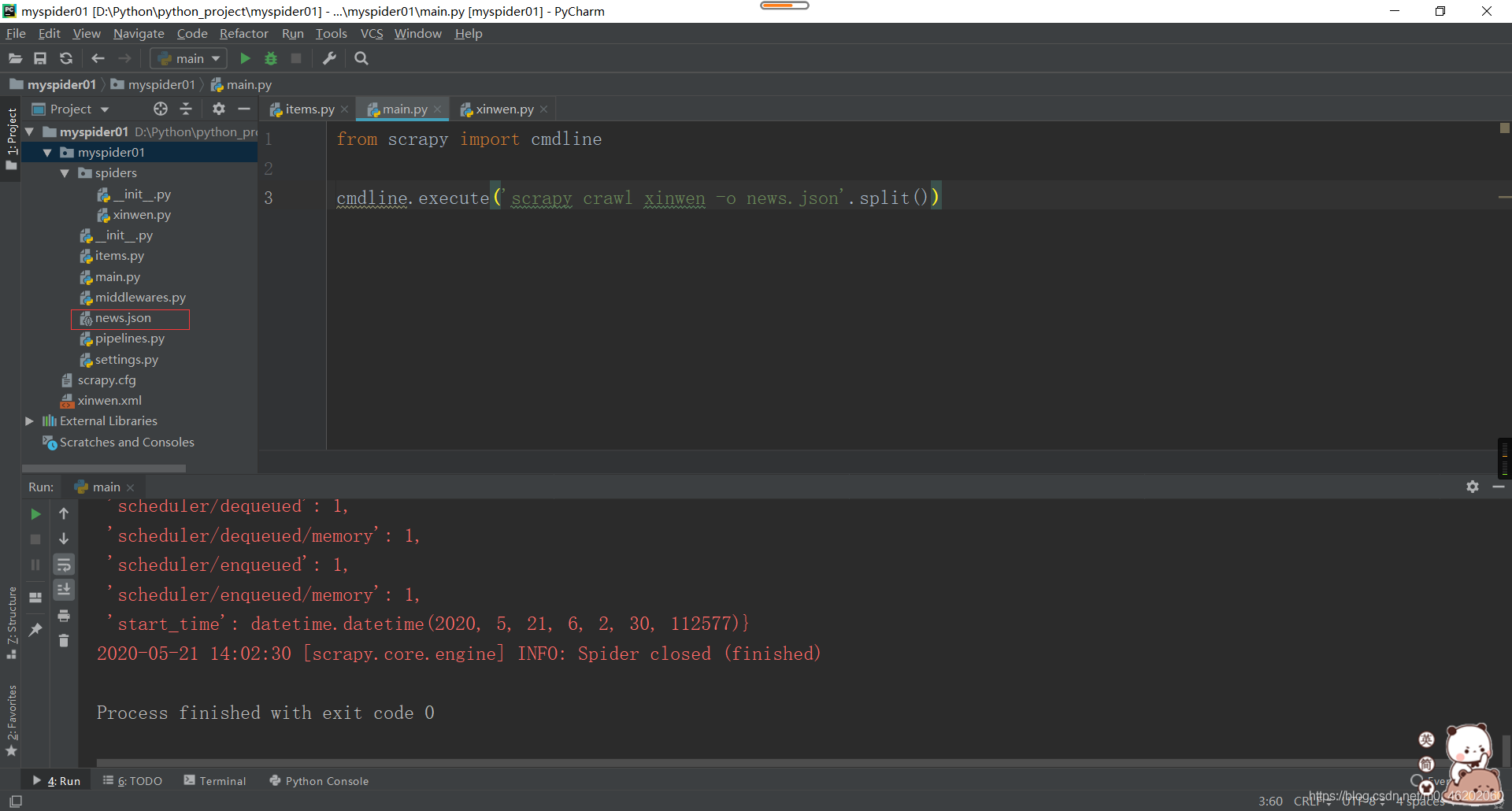
(4)将爬取内容储存下来
这个很easy,直接将main文件中的代码做稍微修改即可:
同样,可以直接在cmd中执行命令:
scrapy crawl xinwen -o xinwen.xml
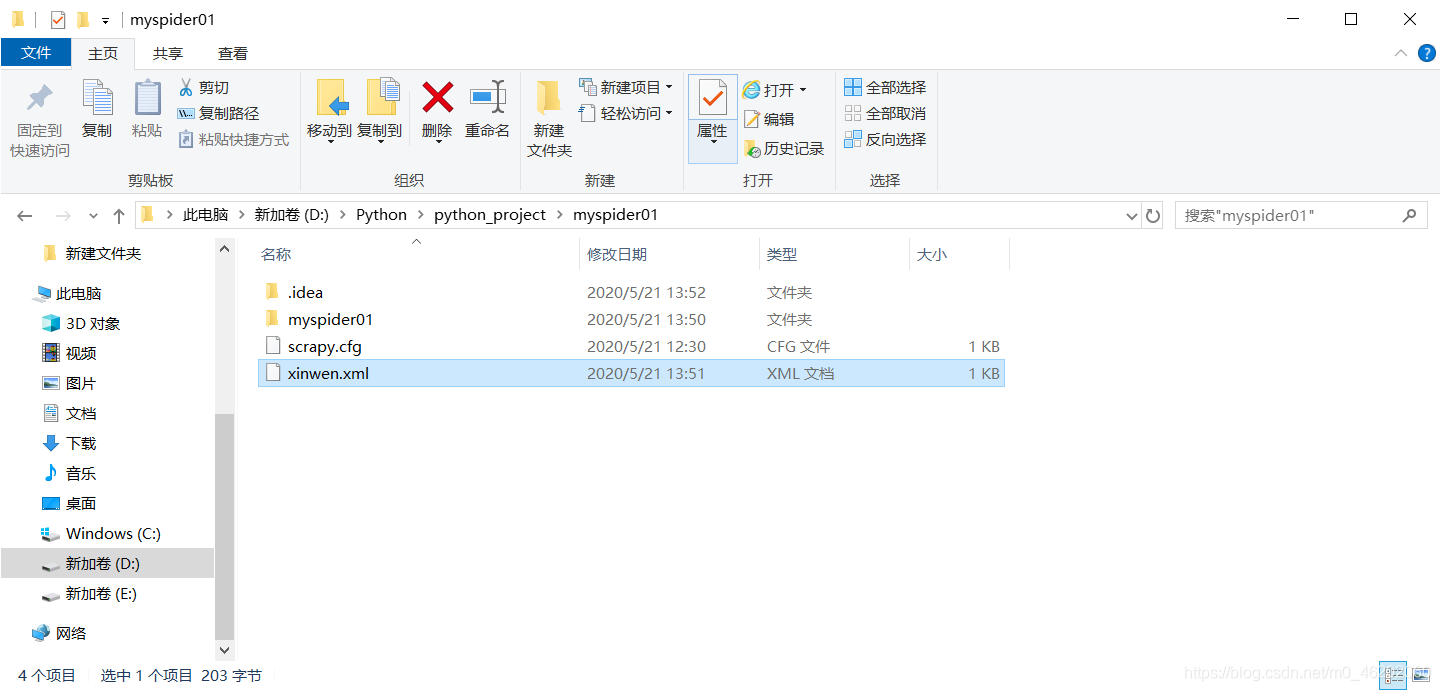
这样就会在项目文件中自动写入xml的文件
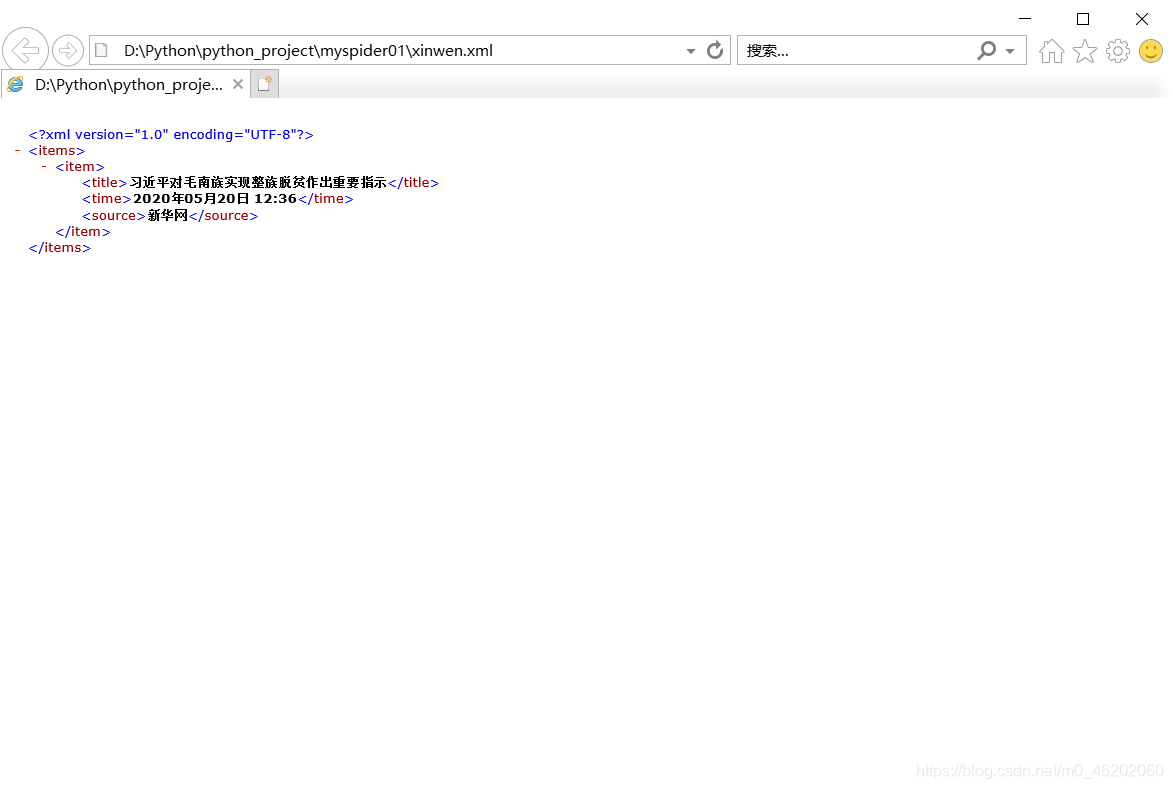
也可直接在pycharm中写入命令:
from scrapy import cmdline
cmdline.execute('scrapy crawl xinwen -o news.json'.split())