大家:
好! kafka同SparkStreaming的对接,以下是我自己的总结,仅供参数。scala代码如下:
package SparkStream
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* Created by Administrator on 2017/10/11.
* 功能:演示kafka的单词统计(kafka同SparkStreaming的对接)
*
*/
object KafkaWc {
val updateFunc = (iterator: Iterator[(String, Seq[Int], Option[Int])]) => {
iterator.flatMap{case(x,y,z)=> Some(y.sum + z.getOrElse(0)).map(n=>(x, n))}
}
def main(args: Array[String]): Unit = {
//设置日志的级别
LoggerLevels.setStreamingLogLevels()
//接收命令行中的参数
val Array(zkQuorum, groupId, topics, numThreads)=args
val conf=new SparkConf().setAppName("KafkaWc").setMaster("local[2]")
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(5))
//设置检查点
ssc.checkpoint("c://test//checkpoint1011")
//设置topic信息 //消费者用多少个线程来消费这个topic
val topicMap=topics.split(",").map((_,numThreads.toInt)).toMap
//重Kafka中拉取数据创建DStream
val lines = KafkaUtils.createStream(ssc, zkQuorum ,groupId, topicMap, StorageLevel.MEMORY_ONLY)
//切分数据,截取用户点击的url
// 取2的目的是kafka中存的数据都是键值对的形式
val word = lines.map(_._2).flatMap(_.split(" ")).map((_,1))
//统计各个单词的个数
val result = word.updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
//将结果打印到控制台
result.print()
ssc.start()
ssc.awaitTermination()
}
}
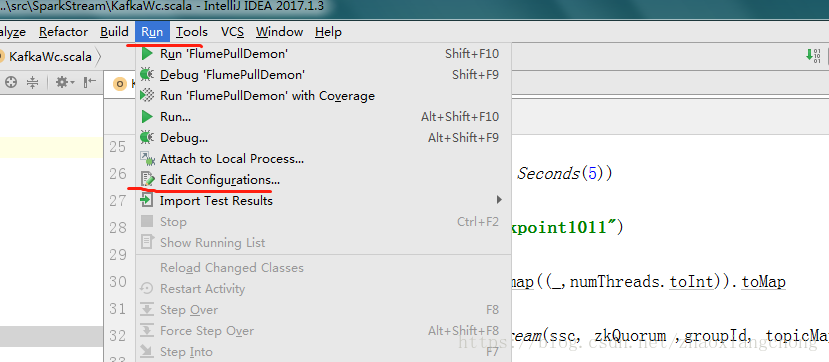
第一步: 在idea中对程序的参数进行设置
1.1 先打开配置参数的窗口,截图如下所示:
1.2 在配置参数的窗口中,进行以下的设置,截图如下所示:
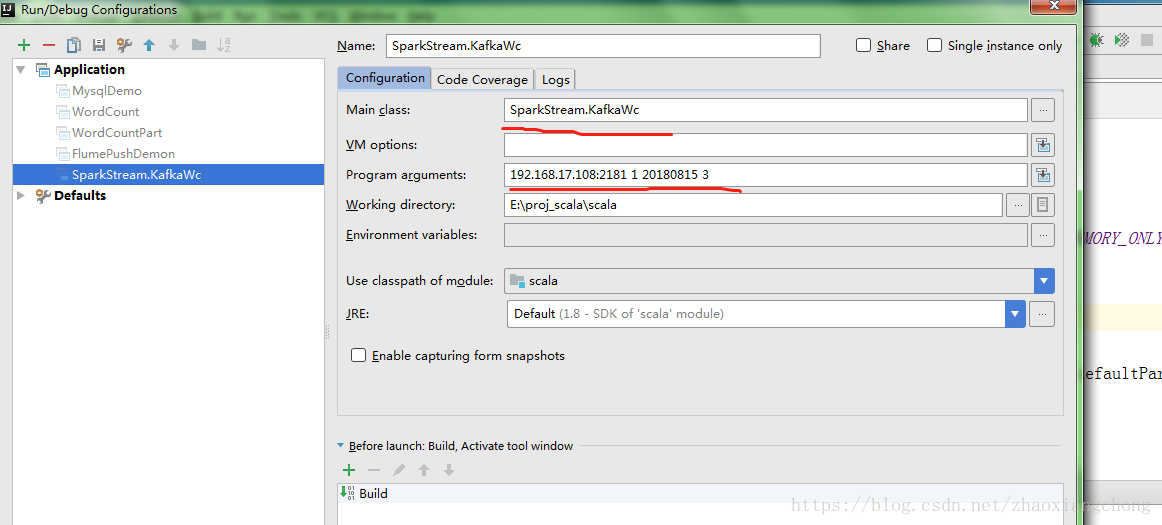
说明: 1 main class 中选择的是所要运行的类
2 “192.168.17.108:2181 1 20180815 3” 对应代码中的是
//接收命令行中的参数
val Array(zkQuorum, groupId, topics, numThreads)=args
第一个参数: “192.168.17.108:2181” 是zookeeper的地址
第二个参数: “1” 是对应的groupid
第三个参数: “20180815” 指的是kafka的生产者对应的topic的名称
第四个参数: “3” 指的是消费者用多少个线程来消费这个topic
第二步: 在idea中运行kafka对接sparkstream的程序,截图如下所示:

从截图中可以看到,本机已经启动了3个线程来接收kafka的topic 20180815。因为此时还没有往kafka中打数据,所以ss的运行结果还是空的
说明: 1 本地上checkpoint的缓存目录,在运行ss之前,一定要删除掉
第三步: 在kafka中创建 topic 20180815
[root@hadoop ~]# kafka-topics.sh --create --zookeeper hadoop:2181 --topic 20180815 --partitions 1 --replication-factor 1
Created topic "20180815".
说明: topic一定要创建一个新的,不要复用以前创建好的topic。否则,往kafka中打数据时,会报错,ss会接收不到数据
第四步: 调用kafka的生产者脚本,将kafka作为一个数据源来为ss提供数据
kafka-console-producer.sh --broker-list hadoop:9092 --topic 20180815

从截图中可以看到,鼠标显示的是等待输入的状态。这就说明,kafka的生产者脚本已经调度成功。当然此时如果查看ss的运行结果,还是没有空的,因为kafka的生产者此时并没有数据,这是可以理解的
第五步: 在kafka的生产者窗口中,输入”bei jing huan ying ni”, 截图如下所示:

说明: 单词之间用空格隔开是为了和ss保持一致,依据实际情况而定
第六步: 查看本地idea中的ss的运行结果, 截图如下所示:
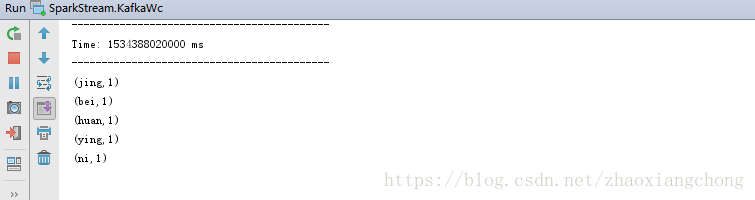
从截图中可以看到,单个时间段内的单词已经统计完毕
第七步: 验证ss程序中的单词累加的功能,输入”shang hai huan ying ni”, 截图如下所示:

第八步: 查看本地idea中的ss的运行结果, 截图如下所示:

从截图中可以看到, huan,ying,ni这三个单词都是两次,其余的四个单词是一个。这符合kafka的生产者提供的数据,程序验证完毕。
总结点: 1 idea中的程序的参数的设置方法
2 kafka的生产者作为sparkstreaming的数据源的核心点
val lines = KafkaUtils.createStream(ssc, zkQuorum ,groupId, topicMap, StorageLevel.MEMORY_ONLY)