一个模式灵活的JSON数据存储,比如Couchbase,提供了一个很大的优势,允许应用程序开发人员以最适合应用程序需求的方式管理模式演化和引用完整性。 无需关闭数据库或获得数据库管理员的许可来更改模式,应用程序只需开始在新模式中写入数据,应用程序逻辑会根据需要处理新的和旧的数据模式。
然而,这种灵活性是有代价的,超出了编写更复杂的应用程序代码的需要。 如果没有正式的模式定义,人们就很难知道编写应用程序代码、查询或定义索引所需的数据结构细节:
- 数据存储中有多少不同的文档模式?
- 字段出现的频率如何?
- 每个领域的数据是什么样的? 类型? 格式? 范围?
沙发基座4。5引入了一个新的基于web的查询界面。

该界面包括“桶分析”面板,在该面板中,如果您单击桶名称旁边的三角形,将会出现类似模式的内容:
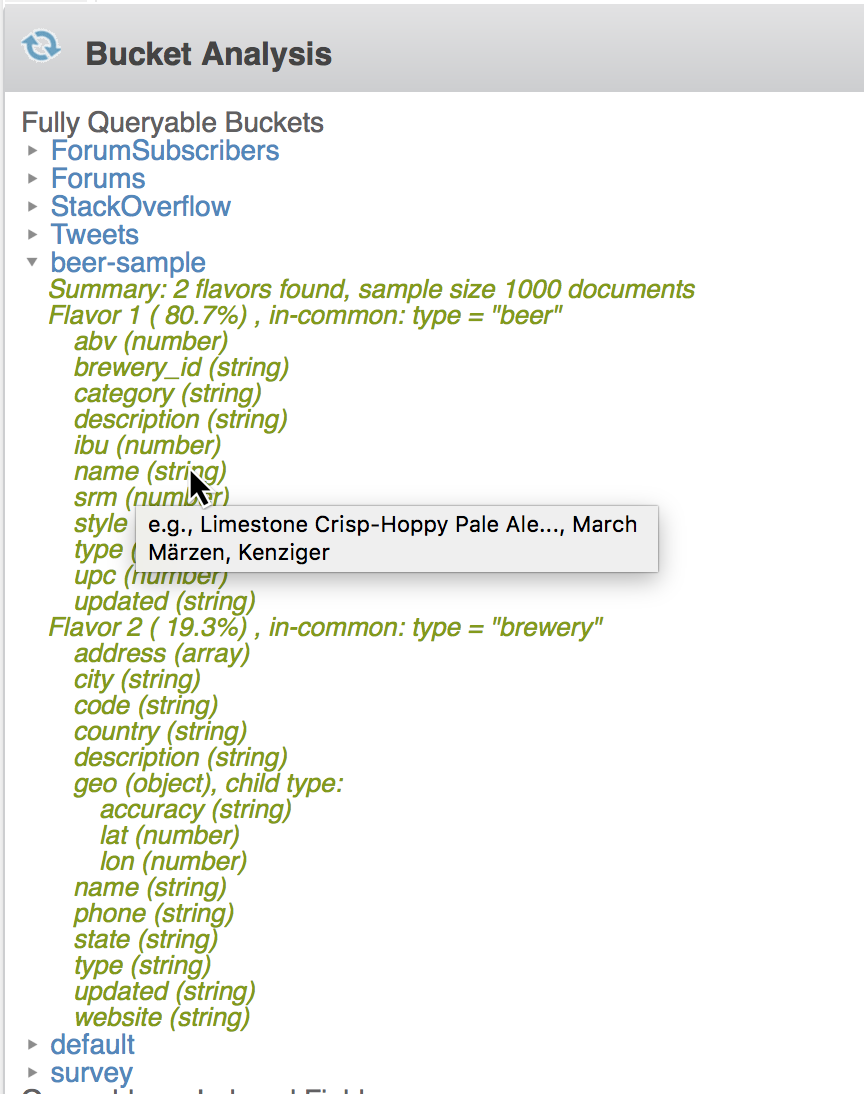
当Couchbase没有或没有强制模式时,这怎么可能呢? 在幕后,这个面板使用的是N1QL的exist命令,它从一个桶中随机抽取文档样本,并推断这些文档存在什么模式。 上面的例子看了啤酒样本桶(在Couchbase的每个实例中都有)。 请注意:
- 推断发现不是一个而是两个具有不同字段集的模式,这些模式被称为“风格”。 两种风格之间有一些共同的字段(描述、名称和类型),但是两种风格之间有更多的字段不同。
- 将鼠标悬停在字段名上会显示该字段的一些示例值。
- 因为infer跟踪每个字段的一些样本值,所以它知道哪些字段对于有味道的文档只有一个不同的值。 在这种情况下,它只看到名为“type”的字段的一个值,因此它将该字段列为每个风格中所有文档的“共有”内容。 在使用Couchbase进行数据建模时,使用“类型”字段是一种常见的模式,但是这个名称没有语义,它可以被称为“类型”、“种类”或“类别”或任何东西。 CONDENSE命令帮助用户了解进行数据建模的人采取了什么方法。
可以作为一个常规的N1QL命令来运行EXPRESS,以获得关于桶的文档的更多细节。 CONDENSE是如何工作的?
- EXPRESS从桶中的随机文档样本开始。 默认情况下,它要求1000个文档,但可能会指定不同的样本大小。
- EXPENDER从每个文档中提取一个模式(字段名,类型),维护一个到目前为止所有不同模式的哈希表。 如果两个模式具有完全相同的字段和类型,则它们是相同的。 如果有许多不同的模式,维护所有不同的模式可能会很昂贵——理论上一个桶中的每个文档都可能有不同的模式——但实际上大多数业务数据遵循常规模式,并且没有很多不同的模式。 维护每个字段的样本值是为了帮助用户理解字段的格式,尽管为了节省空间,长值被截断为32字节。 当两个相同的模式被组合时,每个模式的样本值被组合,直到指定的最大值(默认情况下最多存储5个样本值)。 EXCENSE还跟踪与每个模式匹配的不同文档的数量。
- 一旦找到所有不同的模式,类似的模式就被合并到模式“风格”中。 如果共享顶级字段的分数大于“相似性度量”(默认为0),则认为两个模式相似。6)。 如果一个字段是简单类型,如果两个模式都有一个名称和类型相同的字段,则认为是共享的。 如果字段具有对象类型,则在子类型上递归考虑相似性。 如果您将相似性度量设置为0,那么所有模式都将合并到一个类似于通用关系的模式中。 在另一个极端,相似性度量为1。0意味着每个不同的模式都将成为自己的风格。 风格在一个重要的方面不同于模式:有了模式,字段要么存在要么不存在。 有了一种风味,一个场可以在某些时候出现,因此风味会跟踪每个场出现的频率。
- 每种风格都使用JSON文档来描述,该文档的格式是IETF JSON模式标准草案的扩展(http://json-schema)。org)。 扩展添加了描述样本值的字段,以及每个字段出现的频率。
让我们看一个例子:对于“啤酒样本”桶的EXPENDER的输出。 请注意,这是一个风格数组,每个风格都遵循json-schema格式。 在顶层,每种口味都有一个“#”字段,它指示样本中有多少文档符合这种口味。 在模式描述中,每个字段都有一个名称和类型,还有“#docs”和“%docs”表示字段出现的频率。 每个字段还包括样本值。
运行EXCEPT命令的格式如下:
最常见的参数有:
- sample_size -推断模式时使用多少文档(默认为1000)。
- num_sample_values -为每个字段保留多少样本值(默认为5)。
- 相似性度量——两个模式必须有多相似才能合并成同一个风格(默认为0。6)。
例如,要使用2000个文档的随机样本来推断啤酒样本的模式,并为每个字段维护10个样本值,您可以使用:
EXPENDER的输出非常详细,对以下方面非常有用:
- 了解存在哪些字段及其数据格式。
- 识别不同的模式版本,并找出每个版本存在多少个文档。
- 数据清理,识别很少使用或应该一直存在但没有使用的字段。
应该注意的是,基于随机抽样的推断是不确定的:每次运行它时,你可能会得到稍微不同的结果。 如果相对于指定的样本大小,某些文档模式很少出现,那么您可能也不会选择它们。 然而,总的来说,它是一个强大的工具,可以帮助人们理解在他们的灵活模式数据存储的文档中存在什么模式。