目录
2: 如果是一直执行不完,有可能是数据库异常liquibaselock锁住了。
介绍
Liquibase是一个用于数据库重构和迁移的开源工具,通过日志文件的形式记录数据库的变更,然后执行日志文件中的修改,将数据库更新或回滚到一致的状态。它的目标是提供一种数据库类型无关的解决方案,通过执行schema类型的文件来达到迁移。其优点主要有以下:
- 支持几乎所有主流的数据库,如MySQL, PostgreSQL, Oracle, Sql Server, DB2等;
- 支持多开发者的协作维护;
- 日志文件支持多种格式,如XML, YAML, JSON, SQL等;
- 支持多种运行方式,如命令行、Spring集成、Maven插件、Gradle插件等。
安装
- 下载、解压Liquibase: https://download.liquibase.org
- 安装java(配置环境变量)
- 下载数据库驱动包放到Liquibase目录下的lib
使用
使用情况有两种,一种是在一个完全新的项目中使用,另一种是在老项目中使用(也就是数据库中已经有了历史的表结构和数据,需要反向生成changeLog)。
对于老项目要用liquibase的两种方案:
一:可以整理出该项目数据库里当前的ddl(可能不只是ddl,有些表数据也应该维护到liquibase的,这个要看具体的项目需求),维护到一个初始化的changeLog里当作初始化脚本,这样就可以在新环境里执行初始化脚本(**这种情况要特别特别注意在changeSet里指定context,并且执行的时候也一定要指定contexts,避免在老环境里执行初始化脚本**)。
二:liquibase有专门的反向生成changeLog的命令generateChangeLog。(至于好用不好用我还没试过,等我试过了再补充上来。。。。。)
- liquibase在项目中构建目录
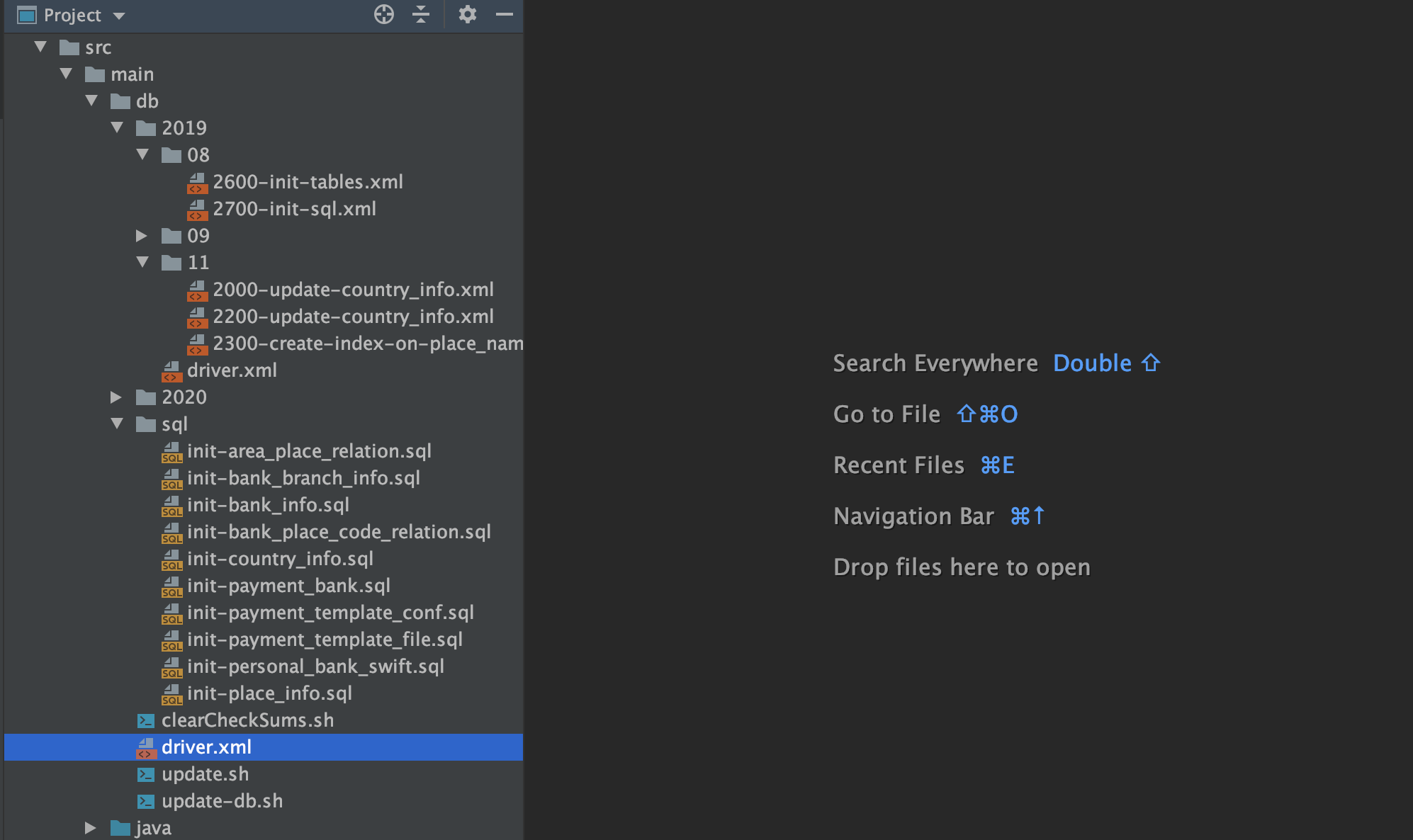
- src/main/db/sql/init-personal_bank_swift.sql
定义一个sql文件,这个sql文件可以直接被另一个changeLog里的changeSet引用执行
INSERT INTO personal_bank_swift (bank_code, clearing_code, swift_code, create_by, create_at, updated_by, updated_at) VALUES
('bank_code2300', '012', 'BKCHHKHHXXX', null, null, null, null),
('bank_code2302', '009', 'CCBQHKAXXXX', null, null, null, null),
('bank_code2304', '041', 'LCHBHKHHXXX', null, null, null, null),
('bank_code2305', '040', 'DSBAHKHHXXX', null, null, null, null),
('bank_code2306', '032', null, null, null, null, null);- src/main/db/2019/08/2600-init-tables.xml
- changeLog:xml (**就是liquibase里的changelog概念,是可以多层嵌套引用其他changelog的**)
- include: 引用changelog的标签
- file: 引用changelog文件的质地
- changeSet: 一个changeLog可以包含多个changeSet标签,每个changeSet都由id和author以及filepath属性进行唯一标识,当 Liquibase执行数据库changeLog时,它按顺序读取 changeSet,并针对每个changeSet检查databasechangelog表,以查看是否运行了 id/author/filepath的组合。如果已运行,则将跳过changeSet,除非存在真正的runAlways标签。运行changeSet中所有更改后,Liquibase将 databasechangelog中插入带有 id/author/filepath的新行以及changeSet的MD5Sum。每个changeSet 的事物是单独的,最佳做法是确保每个changeSet都尽可能原子性更改,以避免失败的结果使数据库中剩下的未处理的语句处于unknown 状态。
- author:作者
- id:changeSet的id(**最好用2019082600-01这种日期的格式,这样更清楚一点,如果是一个目标库可能会被多个项目的liquibase执行到的话,这个id会被写到同一个databasechangelog表 里,可以在日期前面加上项目名或者项目名的缩写来区分,比如reference-2019082600-01)
- runAlways:执行每次运行时设置的更改,即使更改之前已运行
- context:可以用于灵活控制脚本在哪些环境中执行,我们系统一般定义的是环境(比如team2,uat,prod),多个的话可以用 , or and分割,也支持!prod取反的形式 (**如果定义了context,执行时候就一定要指定contexts,不指定的话会取执行所有的sql,context就失效了)
- comment: changeSet的说明。
- preConditions:将执行changeSet之前必须通过的前提条件。可用于在做不可恢复的内容之执行数据健全性检查
- rollback:描述如何回滚changeSet的 SQL 语句或重构标签
- createTable: 创建表的标签
- tableName:表名
- column: 表字段的标签
- name:字段名
- type: 字段类型
- remarks: 字段备注
- constraints:字段约束
- primaryKey: true代表是主键
- nullable: true,false
- unique: true,false
- createIndex: 创建索引的标签
- indexName:索引名
- tableName:创建索引的表名
- column: 索引字段的标签(多个代表联合索引)
- name:字段名
- addColumn: 增加字段的标签
- tableName:增加字段的表名
- column: 增加的字段
- name:字段名
- type: 字段类型
- sql: sql标签,内容可以直接是sql语句
- endDelimiter: 要应用于语句末尾的分隔符。默认值为;,可以设置为''。
- splitStatement: true,false
- stripComments: 设置为 true以在执行之前删除 SQL中的任何注释,否则为 false。如果
- 未设置,则默认值为false
- comment:注释
- sqlFile: 引用sql文件的标签
- path:引用sql文件的地址
<?xml version="1.1" encoding="UTF-8" standalone="no"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd">
<!--第一种标签建表方式-->
<changeSet author="future_zwp (generated)" id="reference-2019082600-00" context="team2,uat,prod">
<createTable tableName="personal_bank_swift">
<column name="id" type="serial">
<constraints primaryKey="true"/>
</column>
<column name="bank_code" type="text" remarks="银行编码"></column>
<column name="clearing_code" type="text" ></column>
<column name="swift_code" type="text" ></column>
<column name="create_by" type="text" ></column>
<column name="created_at" type="timestamp"></column>
<column name="updated_by" type="text" ></column>
<column name="updated_at" type="timestamp"></column>
<column name="pt" type="text"></column>
</createTable>
<rollback>
<dropTable tableName="personal_bank_swift"/>
</rollback>
</changeSet>
<changeSet author="future_zwp (generated)" id="reference-2019082600-01" context="team2,uat,prod">
<createIndex indexName="idx_bank_info_bank_clearing" tableName="personal_bank_swift">
<column name="bank_code"/>
<column name="clearing_code"/>
</createIndex>
</changeSet>
<changeSet author="future_zwp (generated)" id="reference-2019082600-02" context="team2,uat,prod">
<createIndex indexName="idx_personal_bank_swift_swift_code" tableName="personal_bank_swift">
<column name="swift_code"/>
</createIndex>
</changeSet>
<!--第二种sql建表方式,所有的sql语句都支持,学习成本低,更灵活-->
<changeSet author="zhaowenpeng" id="reference-2019082600-03" context="team2,uat,prod">
<sql splitStatements="true">
drop table if exists personal_bank_swift;
create table personal_bank_swift
(
id serial primary key,
bank_code text,
clearing_code text,
swift_code text,
create_by text,
create_at timestamp(6),
updated_by text,
updated_at timestamp(6)
);
comment on column personal_bank_swift.bank_code
is '银行编码';
create index idx_bank_info_bank_clearing on personal_bank_swift(bank_code,clearing_code);
create index idx_personal_bank_swift_swift_code on personal_bank_swift(swift_code);
</sql>
</changeSet>
<!--引用sql文件-->
<changeSet author="zhaowenpeng" id="reference-2019082600-04" context="team2,uat,prod">
<sqlFile path="sql/init-personal_bank_swift.sql"></sqlFile>
</changeSet>
</databaseChangeLog>- src/main/db/2019/driver.xml
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.3.xsd">
<include file="2019/08/2600-init-tables.xml"/>
</databaseChangeLog>- src/main/db/driver.xml
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.3.xsd">
<include file="2019/driver.xml"/>
<include file="2020/driver.xml"/>
</databaseChangeLog>本地执行changeLog
- src/main/db/update.sh (这个文件只用本地执行,idea可以安装bashSupport,右击文件都可以执行)
contexts值与changeSet的context值对应(不满足的话不会执行changeSet),changeLogFile会取读取执
行同包目录下的driver.xml
#!/usr/bin/env bash
liquibase \
--driver=org.postgresql.Driver \
--changeLogFile=driver.xml \
--url=jdbc:postgresql://118.31.105.14:3546/team2_reference_data \
--username=team2_app \
--password=8sVG98uziKfAEqzM \
--contexts=team2 \
update执行完成:

Jenkins执行步骤
- src/main/db/maycur/update-db.sh
#!/bin/bash
DB_HOST="127.0.0.1"
DB_PORT="3306"
DB_TYPE="mysql"
DB_NAME="maycur-pro"
DB_USER="maycur"
DB_PASSWORD="Maycur@2018"
DB_DRIVER="com.mysql.jdbc.Driver"
OPERATOR="update"
CONTEXTS=''
function help_info() {
echo "Please use the canonical setttings: "
echo "./update-db.sh -h <DB_HOST> -p <DB_PORT> -d <DB_NAME> -u <DB_USER> -w <PASSWORD> -t <DB_TYPE> \
-o <OPERATOR>"
echo "ATTENTION! DB_TYPE alternatives would be *mysql* or *postgresql*, nothing more"
exit 1
}
while [[ $# -gt 0 ]]
do
case "$1" in
"-h")
shift
echo "DB_HOST: $1"
DB_HOST=$1
;;
"-p")
shift
echo "DB_PORT: $1"
DB_PORT=$1
;;
"-d")
shift
echo "DB_NAME: $1"
DB_NAME=$1
;;
"-u")
shift
echo "DB_USER: $1"
DB_USER=$1
;;
"-w")
shift
#echo "DB_PASSWORD: $1"
DB_PASSWORD=$1
;;
"-t")
shift
echo "DB_TYPE: $1"
DB_TYPE=$1
if [ "$DB_TYPE" = "mysql" ]; then
DB_DRIVER="com.mysql.jdbc.Driver"
elif [ "$DB_TYPE" = "postgresql" ]; then
DB_DRIVER="org.postgresql.Driver"
else
help_info
fi
echo "DB_DRIVER: $DB_DRIVER"
;;
"-c")
shift
echo "CONTEXTS: $1"
CONTEXTS=$1
;;
"-o")
shift
OPERATOR=$1
;;
*)
shift
;;
esac
shift
done
echo "NOW COMES the EXECUTION..."
/opt/liquibase/liquibase \
--driver=$DB_DRIVER \
--changeLogFile=driver.xml \
--url="jdbc:$DB_TYPE://$DB_HOST:$DB_PORT/$DB_NAME?useSSL=false&useUnicode=yes" \
--username=$DB_USER \
--password=$DB_PASSWORD \
--contexts=$CONTEXTS \
$OPERATOR
if [ $? -eq 0 ]; then
echo "Congratulations! Things are all set, you are good to go!"
else
echo "Oops! Something just went wrong. You're gonna have to take a look at it"
exit 1
fi- jenkins上创建project,配置configure
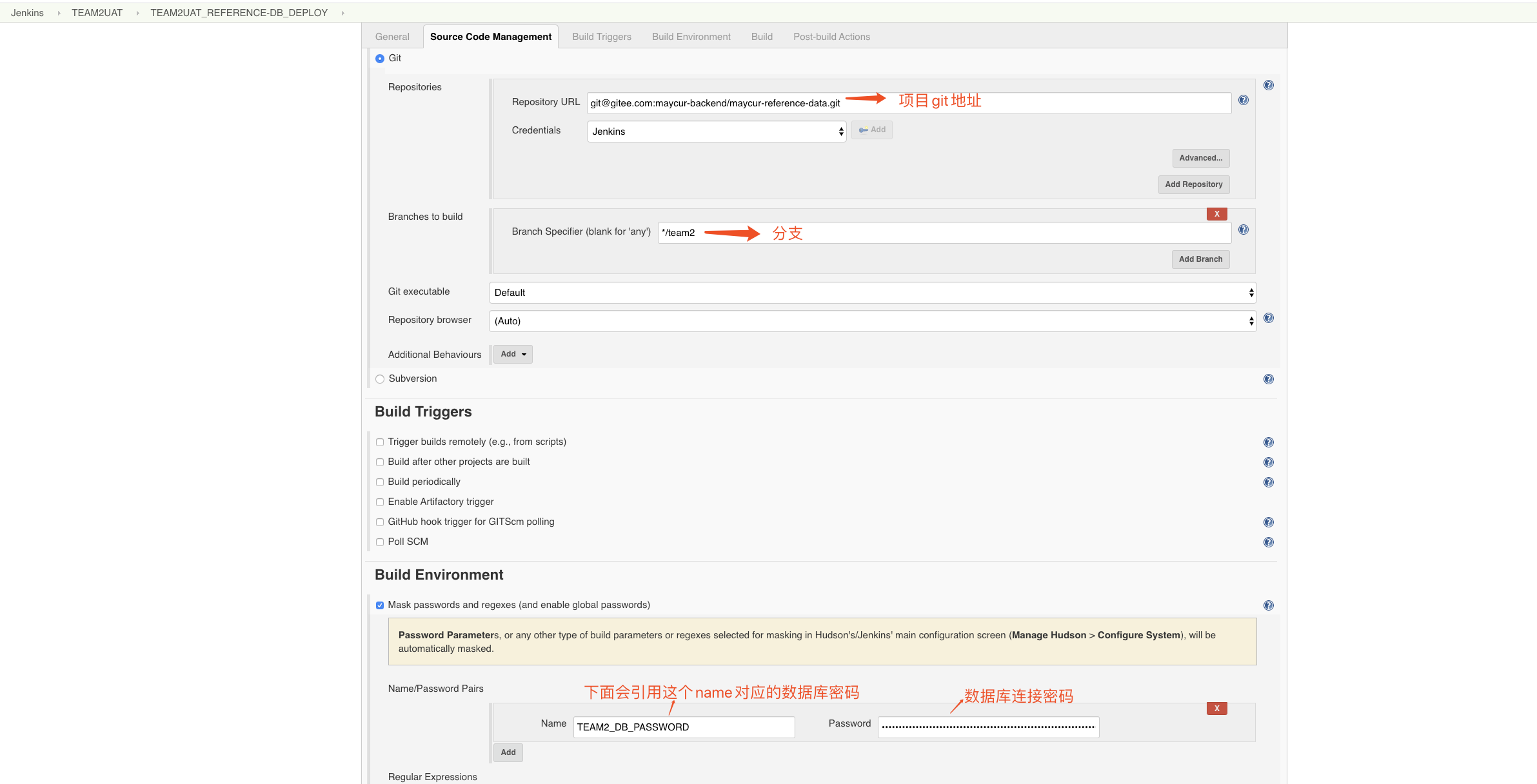
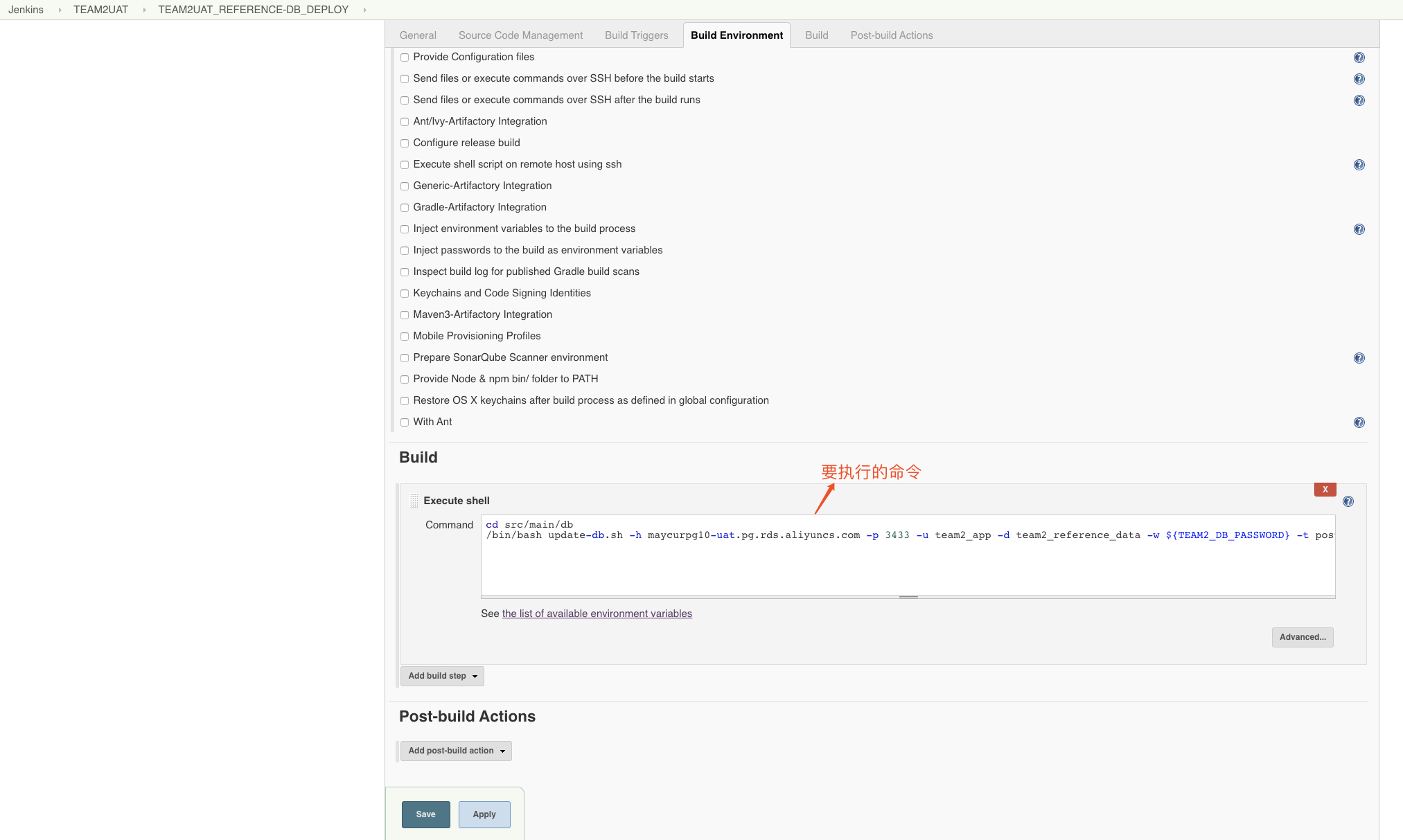
cd src/main/db
/bin/bash update-db.sh -h maycurpg10-uat.pg.rds.aliyuncs.com -p 3433 -u team2_app -d team2_reference_data -w ${TEAM2_DB_PASSWORD} -t postgresql -c team2 -o update- 保存执行就可以了(执行前一定要确定服务器是不是安装了liquibase和需要的数据库驱动jar包是不是放在liquibase目录下的lib文件夹了)
update-db.sh参数说明:
cd src/main/db 这个是要进入到update-db.sh存在的目录
-h 数据库连接host
-p 数据库连接port
-u 数据库连接用户名
-d 数据库库名
-w 数据库连接用户密码(这里引用的是jenkins里配置的name)
-t 数据库类型
-c 指定contexts,需要配合changeSet里的context去有条件的执行sql
-o update、clearCheckSums
第一次执行完成后目标数据库会多出两张表:
DATABASECHANGELOG 表
Liquibase 使用 databasechangelog 表来跟踪已运行的changeSet。
该表将每个更改设置作为一行进行跟踪,由存储changelog文件的路径的id、author和filename列的组合标识。
| 列 | 标准数据类型 | 描述 |
ID |
VARCHAR(255) |
changeSet中的id属性值 |
AUTHOR |
VARCHAR(255) |
changeSet中的author属性值 |
FILENAME |
VARCHAR(255) |
changelog的路径。这可能是一个绝对路径或一个相对路径,具体取决于changelog如何传递到 Liquibase。为获得最佳结果,它应该是一个相对路径 |
DATEEXECUTED |
DATETIME |
执行changeSet的日期/时间。与 ORDEREXECUTED 一起使用以确定回滚顺序 |
ORDEREXECUTED |
INT |
执行changeSet的顺序。除 DATE EXECUTED外,还用于确保顺序正确,即使数据库日期时间支持较差的精度也是如此。 注: 仅在单个更新运行中保证值增加。有时它们会在零处重新启动。 |
EXECTYPE |
VARCHAR(10) |
changeSet是如何执行的描述。可能的值有EXECUTED, FAILED, SKIPPED, RERAN, 和 MARK_RAN |
MD5SUM |
VARCHAR(35) |
执行changeSet时的校验。用于每次运行,以确保changelog文件中的 changSet 没有意外更改 |
DESCRIPTION |
VARCHAR(255) |
changeSet生成的可读的描述 |
COMMENTS |
VARCHAR(255) |
changeSet的comment标签的值 |
TAG |
VARCHAR(255) |
changeSet的跟踪对应于标签操作。 |
LIQUIBASE |
VARCHAR(20) |
用于执行changeSet的 Liquibase 版本 |
**该表没有主键。这是为了避免对密钥长度进行特定于数据库的任何限制。
DATABASECHANGELOGLOCK表
Liquibase 使用 databasechangeloglock 表确保一次只运行一个 Liquibase 实例。
因为Liquibase 只是从 databasechangelog 表读取以确定需要运行的changeSet,因此,如果同时对同一数据库执行多个 Liquibase实例,则会发生冲突。如果多个开发人员使用相同的数据库实例,或者集群中有多个服务器在启动时自动运行 Liquibase,则可能会发生这种情况。
| 列 | 标准数据类型 | 描述 |
ID |
INT |
锁的 ID。目前只有一个锁,但将来是有用的 |
LOCKED |
INT |
如果 Liquibase正在针对此数据库运行,则设置为"1"。否则设置为"0" |
LOCKGRANTED |
DATETIME |
获取锁的日期和时间 |
LOCKEDBY |
VARCHAR(255) |
被谁锁住的描述 |
**如果 Liquibase 未干净地退出,则锁住的行可能会保留为锁定状态。您可以通过运行UPDATE DATABASECHANGELOGLOCK SET LOCKED=0清除当前锁
常见错误:
1: 修改了历史的脚本文件,执行会报下列错误
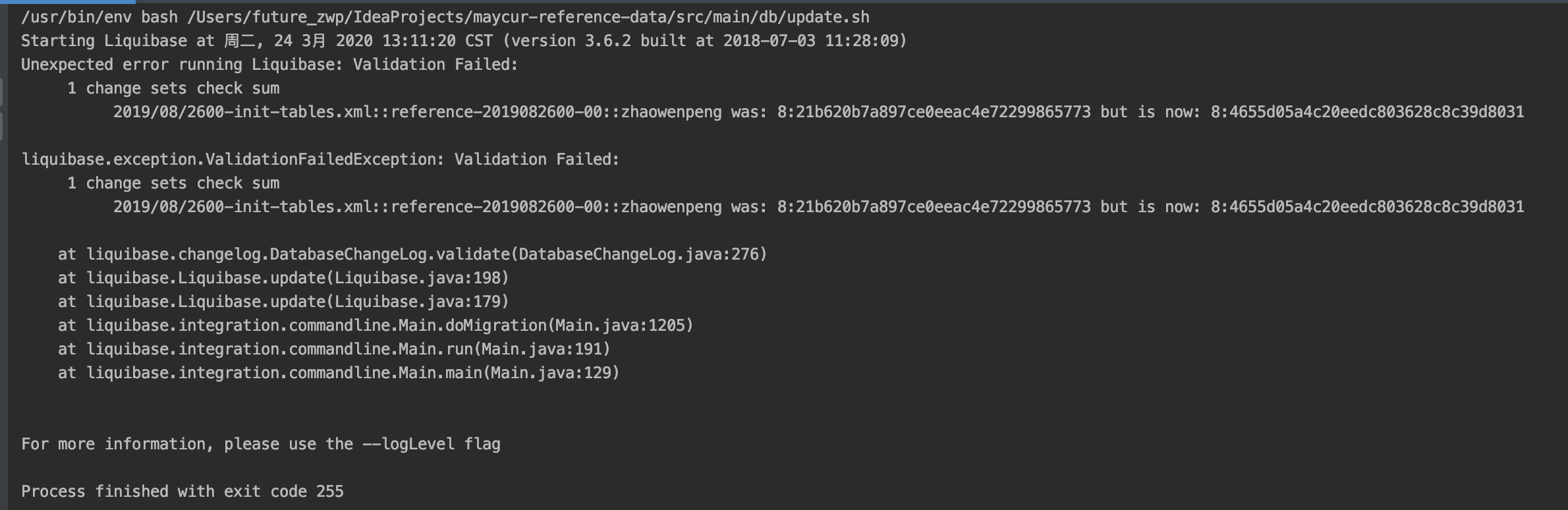
此时如果需要忽略此脚本的改动,可以将src/main/db/update.sh里的update值改为clearCheckSums执行一遍,再重新执行脚本就可以了
2: 如果是一直执行不完,有可能是数据库异常liquibaselock锁住了。
此时可以连接执行脚本的数据库,select * from databasechangeloglock;
如果发现locked是锁住的状态下,停止脚本,将locked改成0后再重新执行脚本即可。

ps:文件package优化
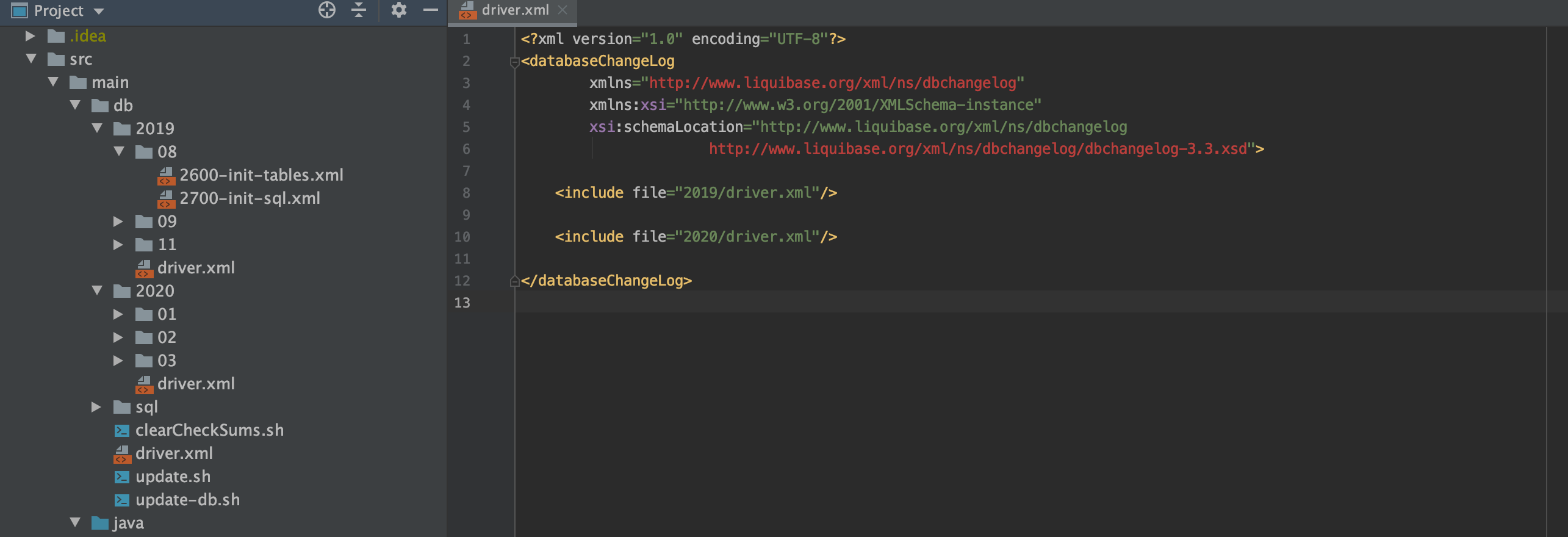
1. 场景一:
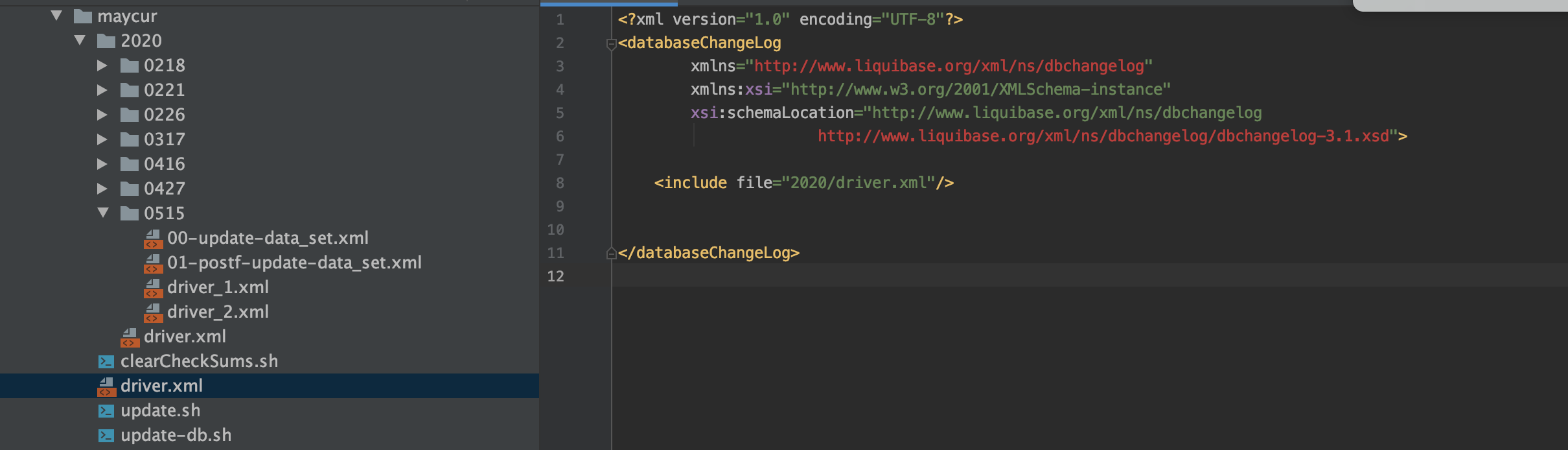
如果把所有xml文件都放到一个package下的话,时间久了会导致文件结构不太优美,driver.xml里的内容也会很长,每次新增一个脚本的话要拉到文件的最下面添加,体验极其不好,所以一开始就定义一个可持续扩展的文件结构就很重要了。解决方案如图:过一年新增一个年份的目录就可以了
- 创建db目录
- 在db目录下创建年份的目录
- 在年份目录下创建月份目录和年份级别的driver.xml
- 在月份目录下创建要执行的脚本
- 在年份目录下创建年份级别的driver.xml(include该年份目录下所有月份里的xml文件)
- 在db目录下创建db级别的driver.xml(include该db目录下所有年份里的driver.xml文件)
- 执行的时候执行db目录下的driver.xml就可以了
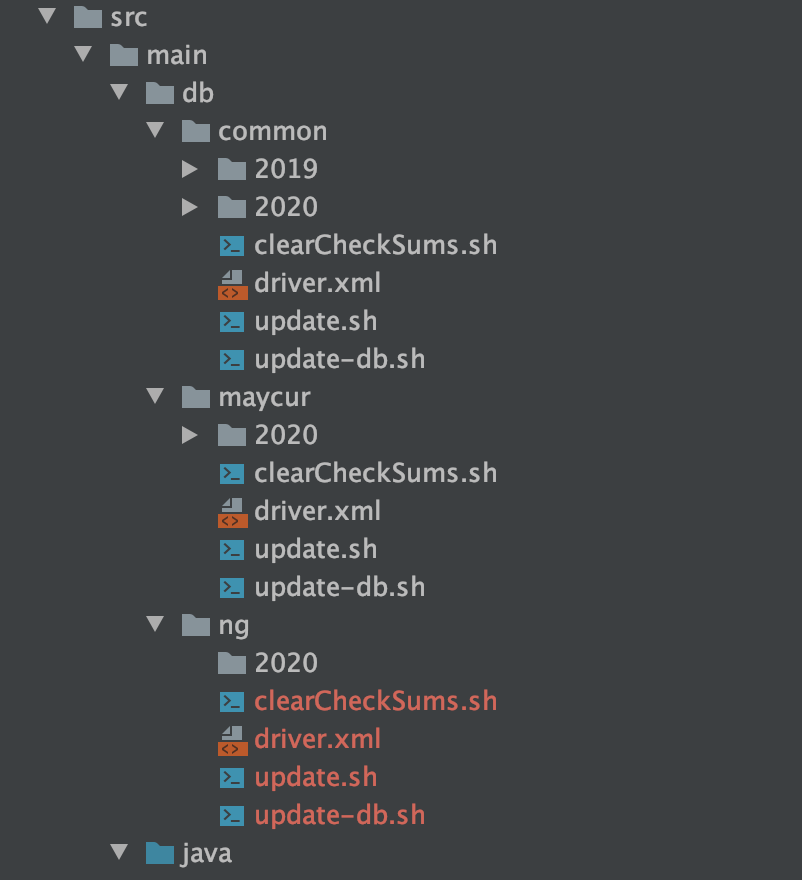
2. 场景二:
我们有两个产品线maycur和ng,两个产品线都用到了同一个项目,但是因为一些产品线的差异使得有些sql脚本在两个产品线里会有不一致的情况,这时就要区分执行了。这个方案的策略是将执行的文件分类,将两个产品线都可以执行的文件放到common文件夹里,将只用在maycur执行的文件防弹maycur文件夹里,将只在ng执行的文件放到ng文件夹里。common、maycur、ng、三个目录下都有单独的driver.xml和update.sh。这样的话部署时就可以区别部署了:
- maycur:执行common、maycur目录下的update.sh
- ng: 执行common、ng目录下的update.sh
3. 场景三:
有时候可能因为某个特定环境数据库的版本问题一些维护在liquibase的sql会执行失败,这个时候不会修改liquibase维护的脚本,一般会采取修改sql的方案直接在数据库执行去达到目的。但这个方案也会伴随着一些问题产生(这个sql所在的changSet会一直执行不成功,无法向下执行),这个时候我们就要考虑怎么去忽略掉这个脚本。
- 方案一(不是很建议):
手动插入一条执行记录到目标库里的databasechangelog表中,每个changeSet都由id和author以及 filepath属性进行唯一标识,所以这三个值一定要严格对应要忽略的脚本(也可以从执行成功的数据库里copy出对应sql的那条databasechangelog的记录来插入,要注意contexts、liquibase版本这些不匹配的值要更改一下)。因为md5的值可能会不一样,这个时候要执行clearCheckSums后再重新执行脚本。
- 方案二(建议使用):
一个changeSet可能有多个sql脚本,我们这个场景很可能只改了一个sql,这个时候我们可以把对应的那条sql随便改个无意义的sql(比如:select 1)去执行一遍liquibase,这个时候databasechangelog表就有了对应的执行记录,这个时候我们就可以把那条sql再改回去,重新clearCheckSums下就好了。
4. 场景四:
我们报表服务会有很多大数据量的表,而每次发版时候使用liquibase对这些表进行DDL操作的时候,因为polardb的特性,会执行特别长的时间,好不容易liquibase执行完了,还要去跑全量的初始化数仓任务(这个操作会先清空表数据),这样就导致了发版时间进一步延长。为了解决这个问题我们总结了一个方案。
发版步骤:
1、将update.sh里changeLogFile指定2020/0515/driver_1.xml后执行update.sh
2、数仓跑相关的数仓初始化任务
3 将update.sh里changeLogFile指定driver.xml后执行update.sh
4、部署前后端服务
(第一步、第二步因为都是操作临时表,所以可以提前执行)
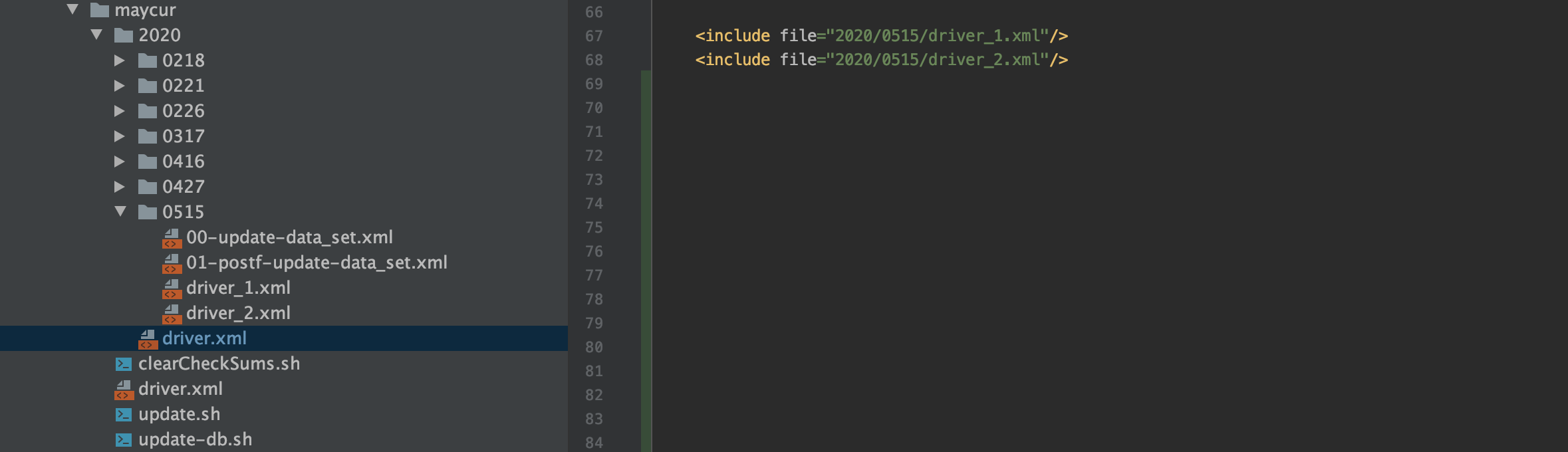
- 每个版本我们创建一个package,如0515。
这个包下创建driver_1.xml、driver_2.xml两个文件
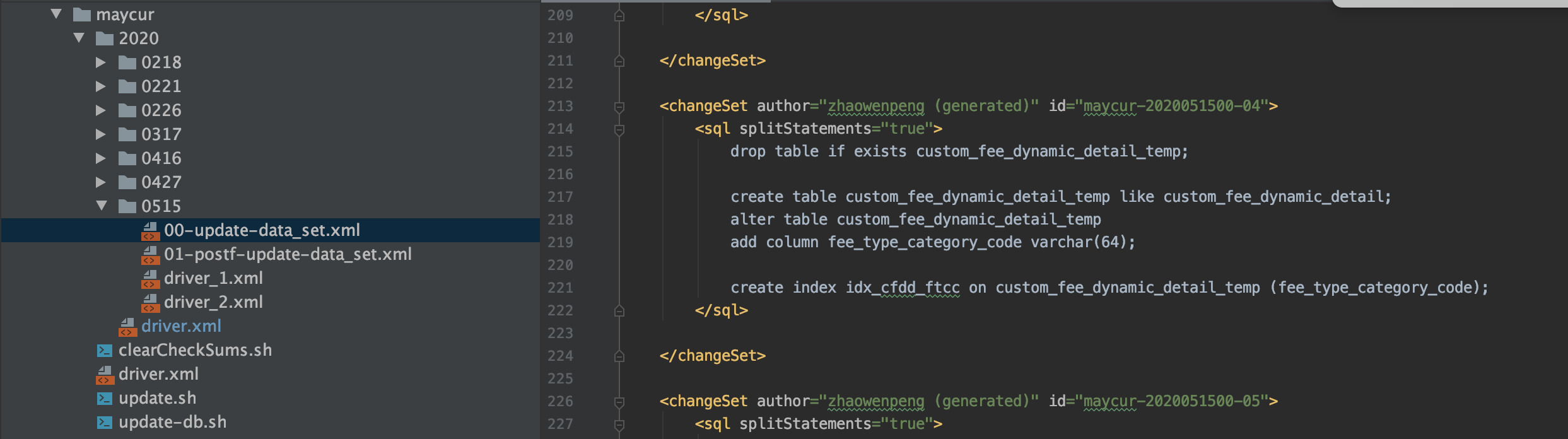
1、driver_1.xml里面include第一步要执行的xml文件,如下图,当我们想对custom_fee_dynamic_detail表进行加字段的时候,我们会创建出一个custom_fee_dynamic_detail_temp的临时表,然后在custom_fee_dynamic_detail_temp表上进行加字段操作。数仓的初始化任务输出就可以指定输出到custom_fee_dynamic_detail_temp
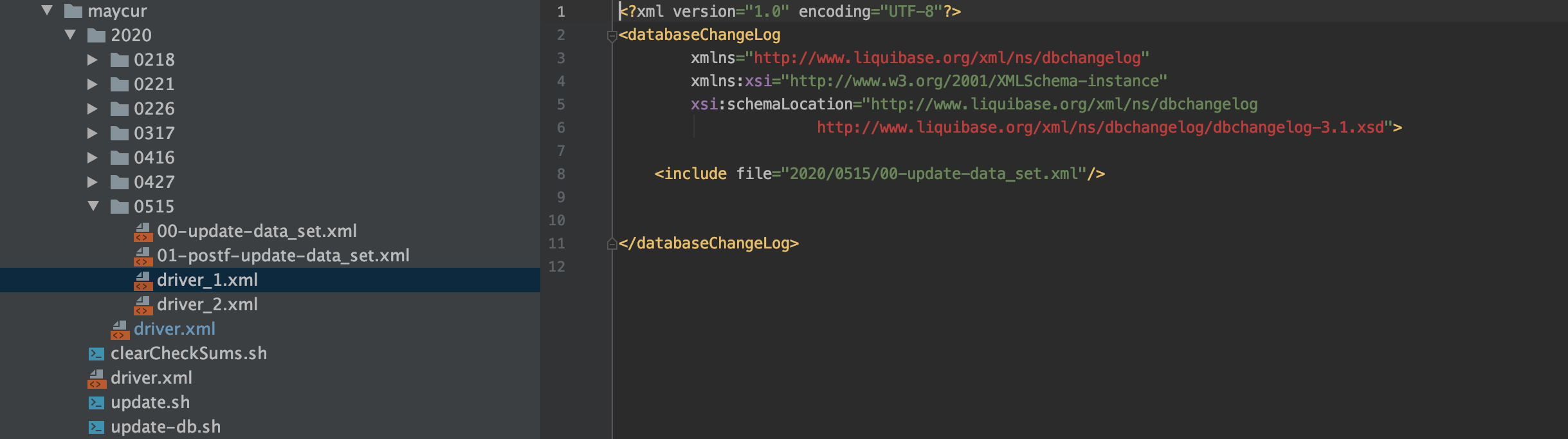
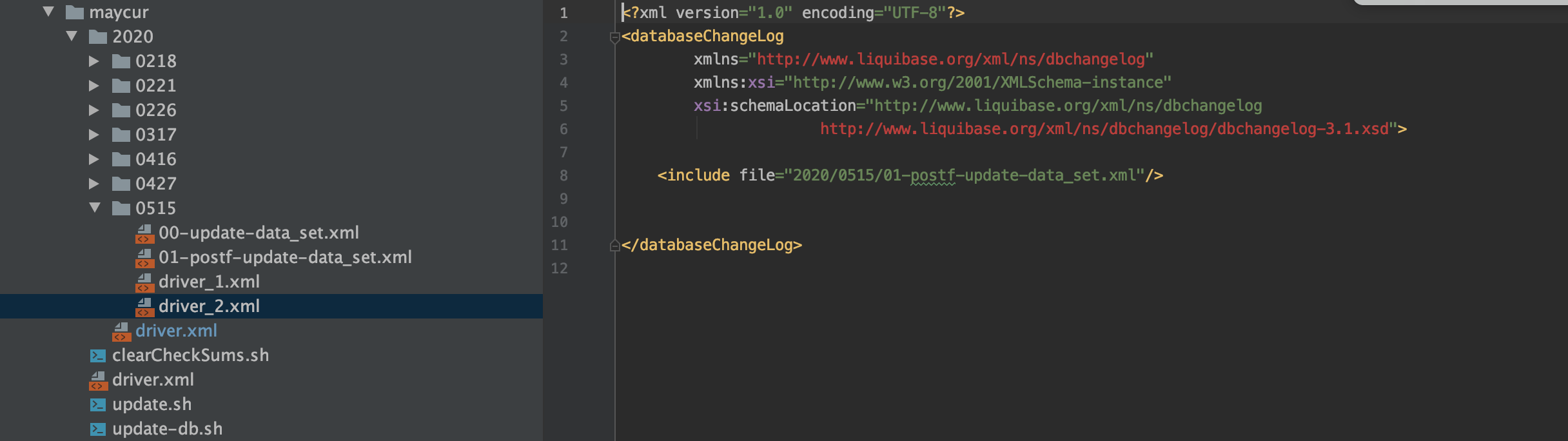
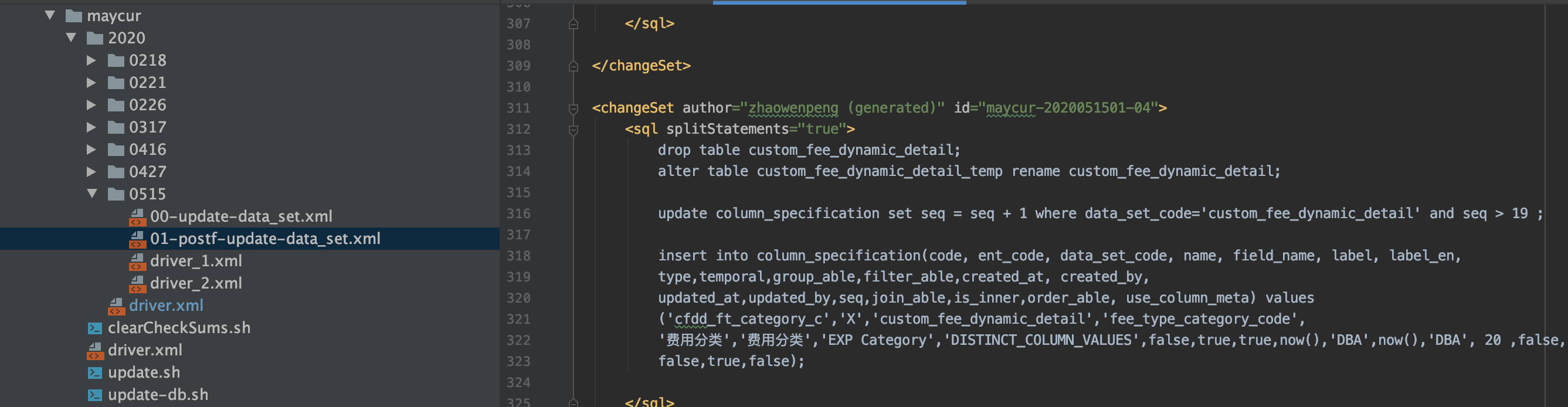
2、driver_2.xml里面可以include第二步要执行的xml文件,如下图,当数仓的初始化任务指定输出到custom_fee_dynamic_detail_temp后,我们会drop掉旧数据结构的表custom_fee_dynamic_detail,然后我们会把custom_fee_dynamic_detail_temp临时表rename回custom_fee_dynamic_detail,再然后别的地方就可以引用新的数据结构的custom_fee_dynamic_detail表
- 2020包下的driver.xml
- maycur包下的driver.xml