文章目录
1 RNN条件生成

RNN可以解决的问题有多种,根据输入输出个数不同分为:
1 一对多:图像描述
2 多对一:文本分类
3 多对多:
实时多对多:输入法、视频解说
输入完成再多对多:机器翻译
条件生成问题:P(y|x)
2 机器翻译
2.1 V1:Encoder-Decoder
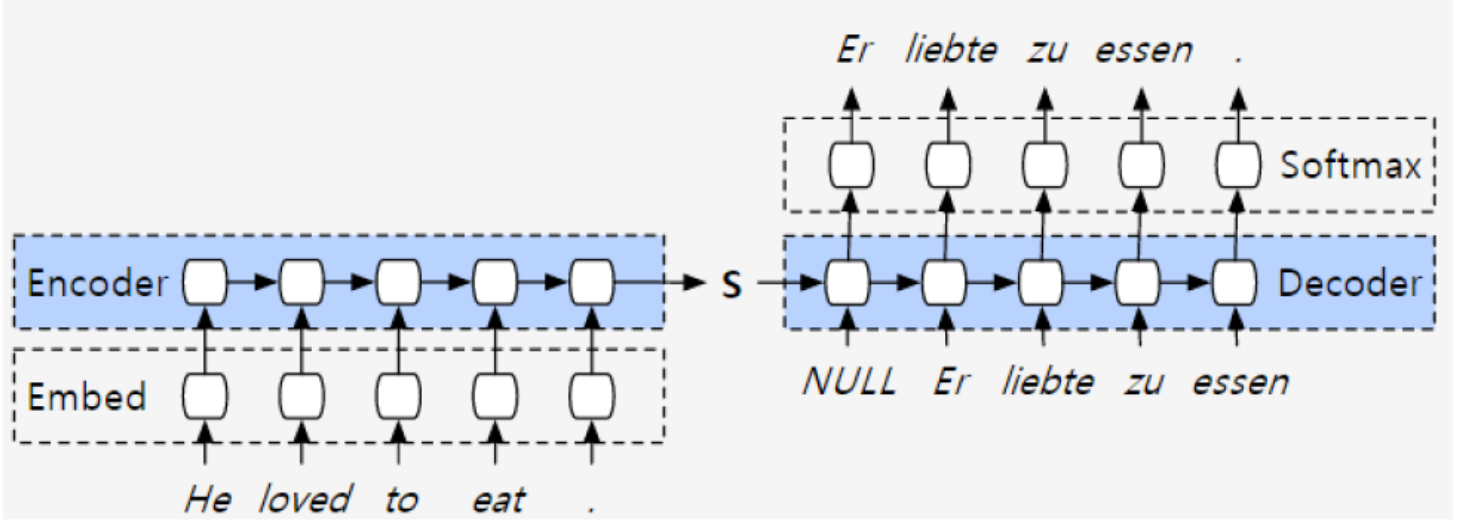
encoder-decoder由2个RNN组成。RNN一般具体指LSTM。在手机上的时候一般使用GRU模型。
第一个RNN做编码的事情。把输入编码为S,最后一个单元的输出作为编码S。
第二个RNN做解码的事情。把S输入,得出第一个词,第一个作为输入得到第二次输出…
decoder一个向量,之后做一个全连接softmax预测下一个词。
缺点:向量S一般是固定长度,例如1024,2048,能够存储的信息有限。
RNN中有忘记门,长度越长,前面输入RNN的信息就越被稀释。
2.2 V2:Attention-based Encoder-decoder
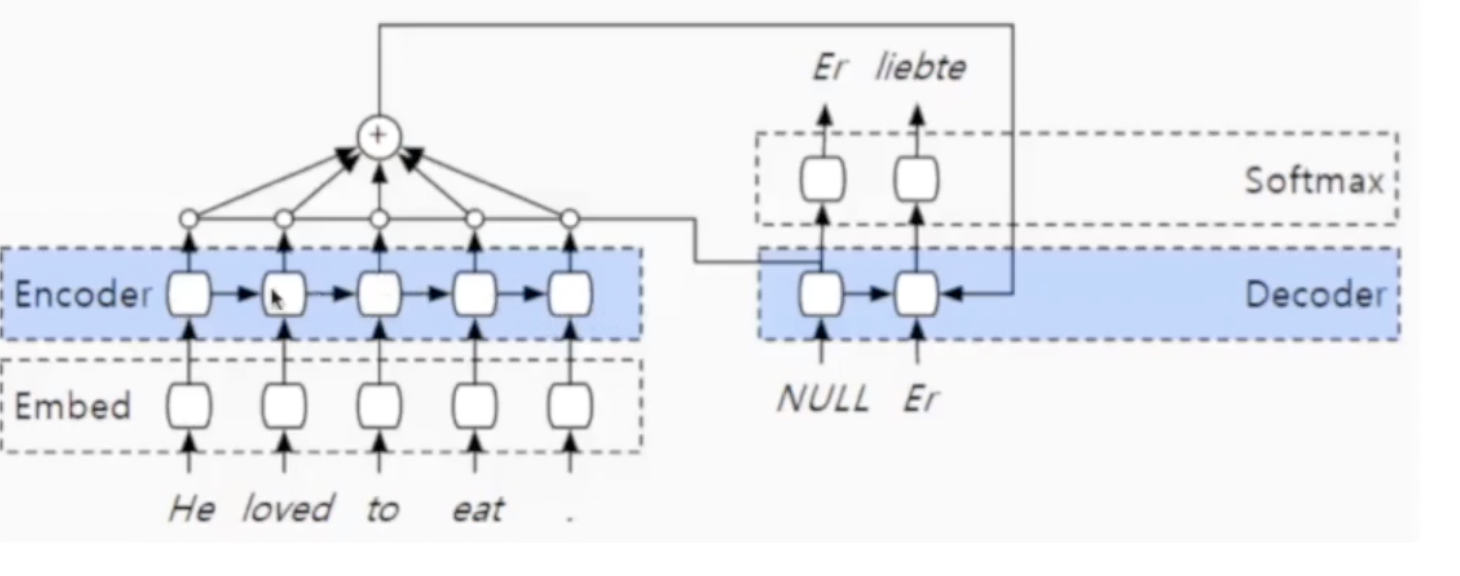
这个网络是在前一个的基础上添加了Attention机制。
首先每一步的输出都以加权的方式参与到计算中得到attention。
第二:输出的attention参与到decoder的第二步计算中。在计算decoder第二步输出的时候参与的对象有3个:第一步的输出结果、第一步到第二步的隐状态hi,以及attention。
第三,第二步计算得到的hi,会再次参与attention的计算。计算之后attention参与到decoder的第三步中。
具体Attention层
Attention的计算:LSTM每一步的输出向量 a = [ a 1 , a 2 , . . . a n ] a=[a_1,a_2,...a_n] a=[a1,a2,...an]
decoder每一步的中间状态hi
a l p h a = [ t a n h ( w 1 ∗ a j + w 2 ∗ h i ) alpha = [tanh(w1*aj+w2*hi) alpha=[tanh(w1∗aj+w2∗hi) for j in r a n g e ( n ) ] range(n)] range(n)]
attention加权:alpha*a
global attention 计算量大,提出local attention。

2.3 V3:bi-directional encode layer
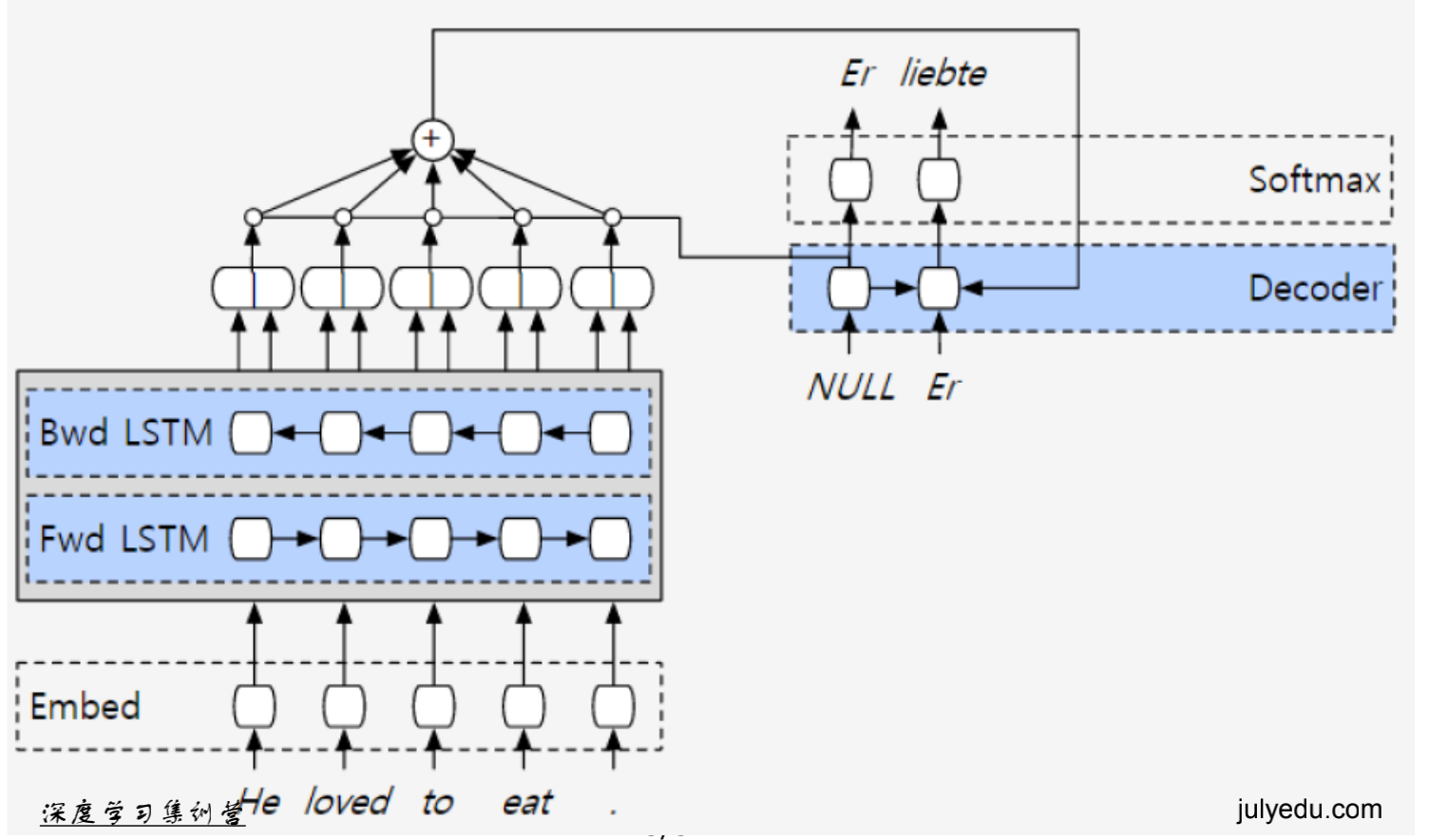
使用双向RNN做encode。
2.4 V4:Residual Encode layer
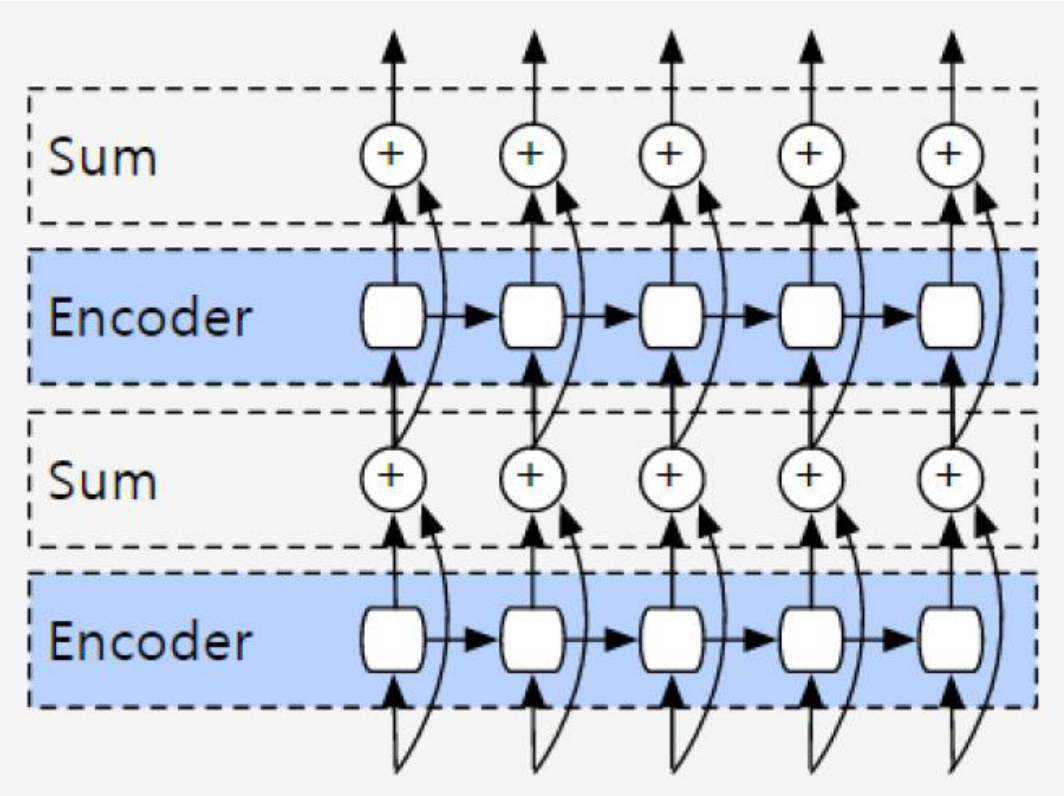
最后得到谷歌的机器翻译网络:

3 Attention
除了global attention,local attention,还有self attention、hierarchical attention。
3.1 self attention
可以理解为source=target的情况下,捕捉词与词之间的关系。这可以用于知识图谱抽取关系,实体词等。
3.2 hierarchical attention
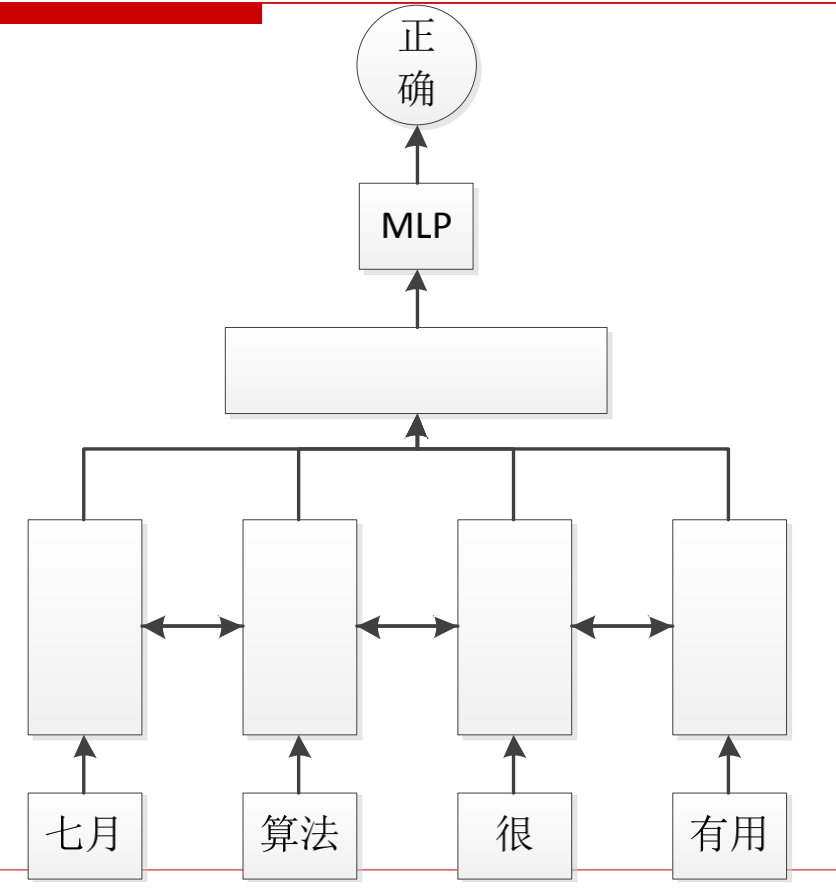
一种是在文本分类中。第一层词取得embedding,第二层是双向LSTM。对第二层的输出做合并,可以使用拼接、average或者max,拼接过程中加入attention。将输出作为第三层的输入,送入MLP中,得到正确的分类。
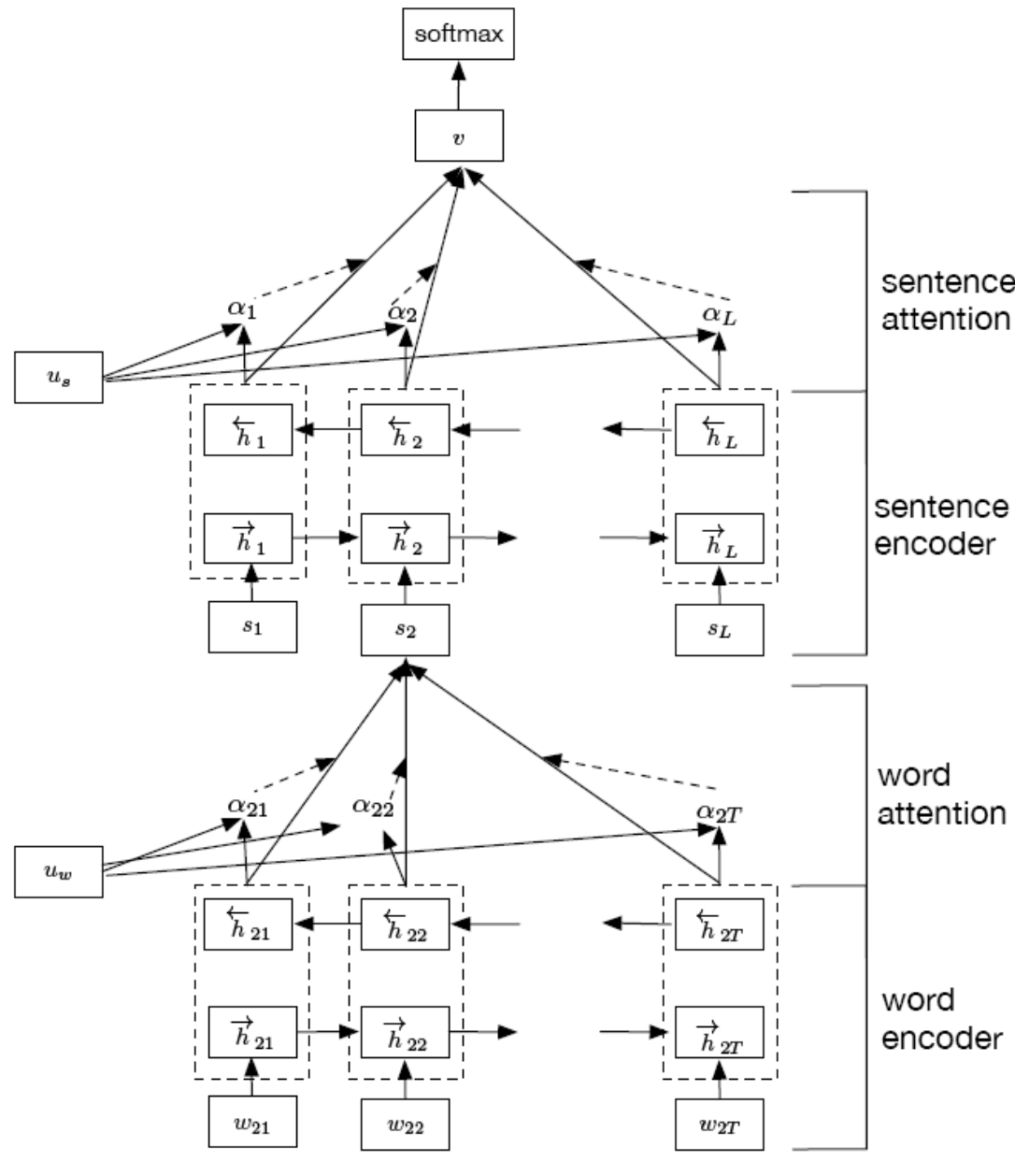
在对文章分类过程中,一种策略是先看句子是什么情况,再看句子中的词是什么情况。
对每个句子中的词都会做一个RRN。例如图中是对第二句话S2做RNN。
输入层是词。第二层是双向LSTM,对词做encode。输出结果以及上一个句子的encoder输出,加入attention,得到输出是句子编码。一个层级完成。
上一个层级是句子。不同的句子之间算一个RNN。得到所有句子的编码。
之后做decoder,做分类。
attention 就是一个加权,看哪个对象权重高。
embedding就是把用one-hot形式表示的词向量,通过table projection的方式表示为一个固定维度的稠密向量。例如词库中有40万词,那就是把一个40万维的词向量映射为一个300维的词向量。
4 图像生成文本
4.1 问题引入
1 图像检索
2 盲人导航:引导盲人自拍
3 少儿教育-看图说话
数据集:AI Challenger: 图像中文描述数据
评测:BLEU score
4.2 模型变迁
4.2.1 M—RNN
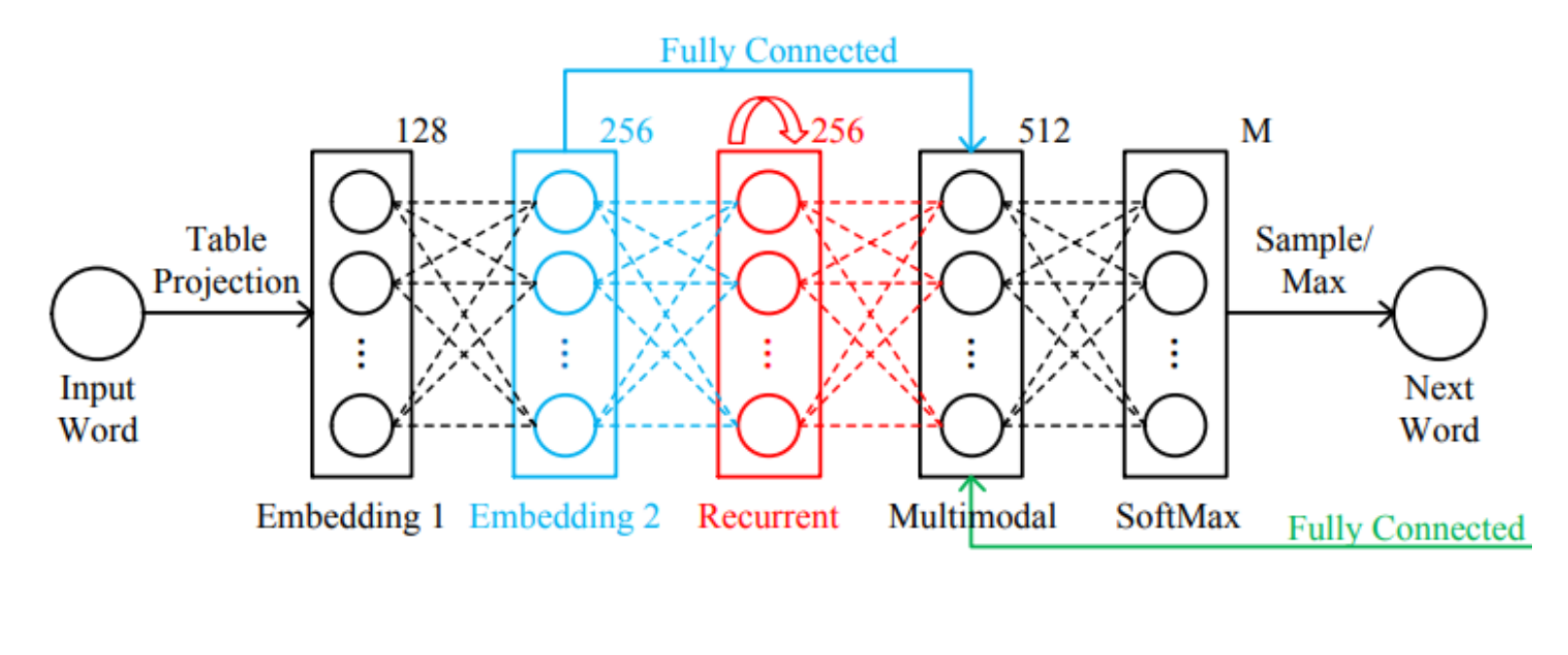
1 输入词生成embedding
2 对embedding做全连接生成256维度的词表达
3 Embedding输入到RNN生成更加抽象的embedding
4 256维度的embedding、RNN的embedding以及图像特征同时输入给multimodal。此处的图像特征是AlexNet的第七层输出。
5 最后:输出交给分类层做softmax,预测出下一个词。
4.2.2 Neural Image Caption
模型show and tell,是斯坦福大学李飞飞实验室提出的。
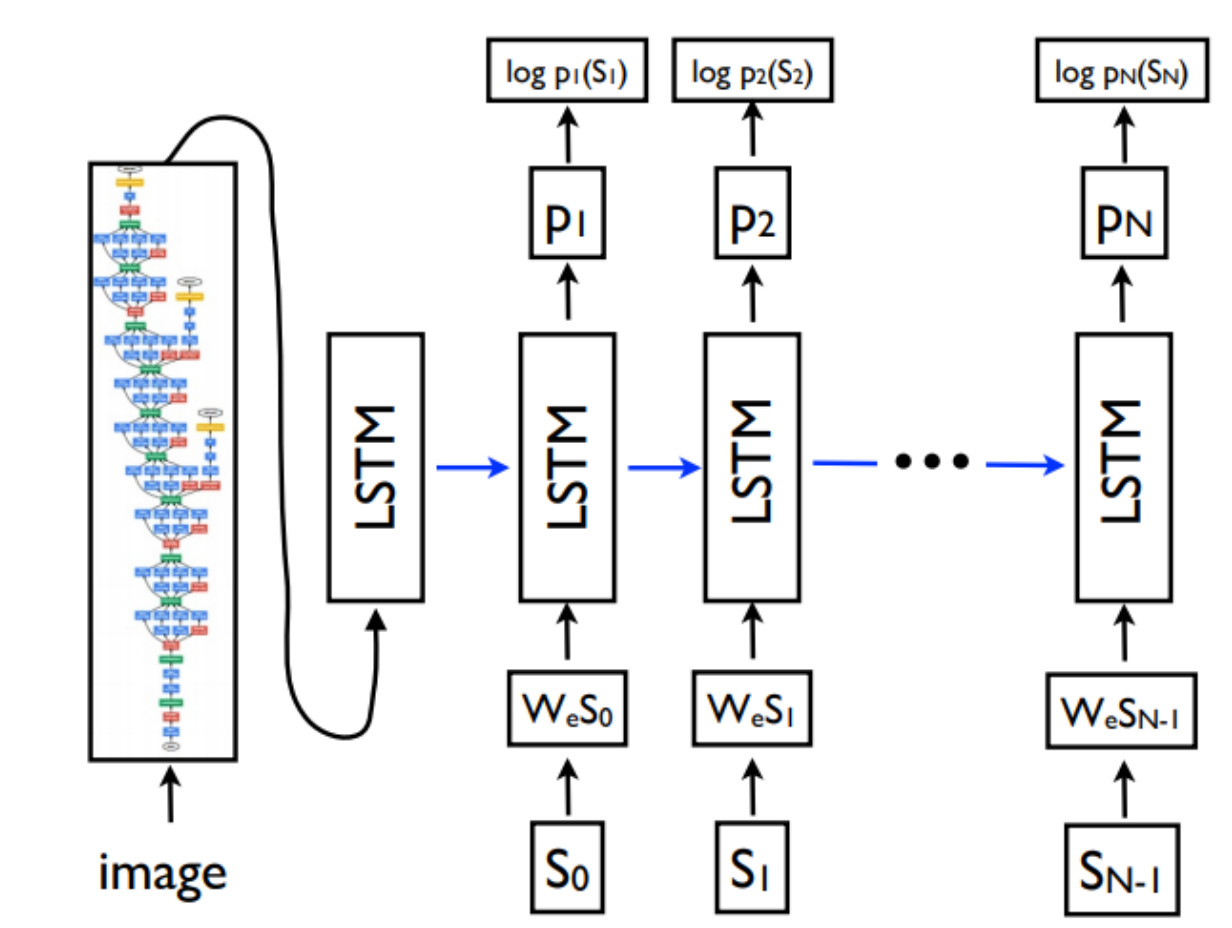
1 图像特征使用更强大的CNN提取,例如googlenet、residual等
2 图像特征只提取一次
3 用LSTM生成文本
4.2.3 attention based
- show attend and tell
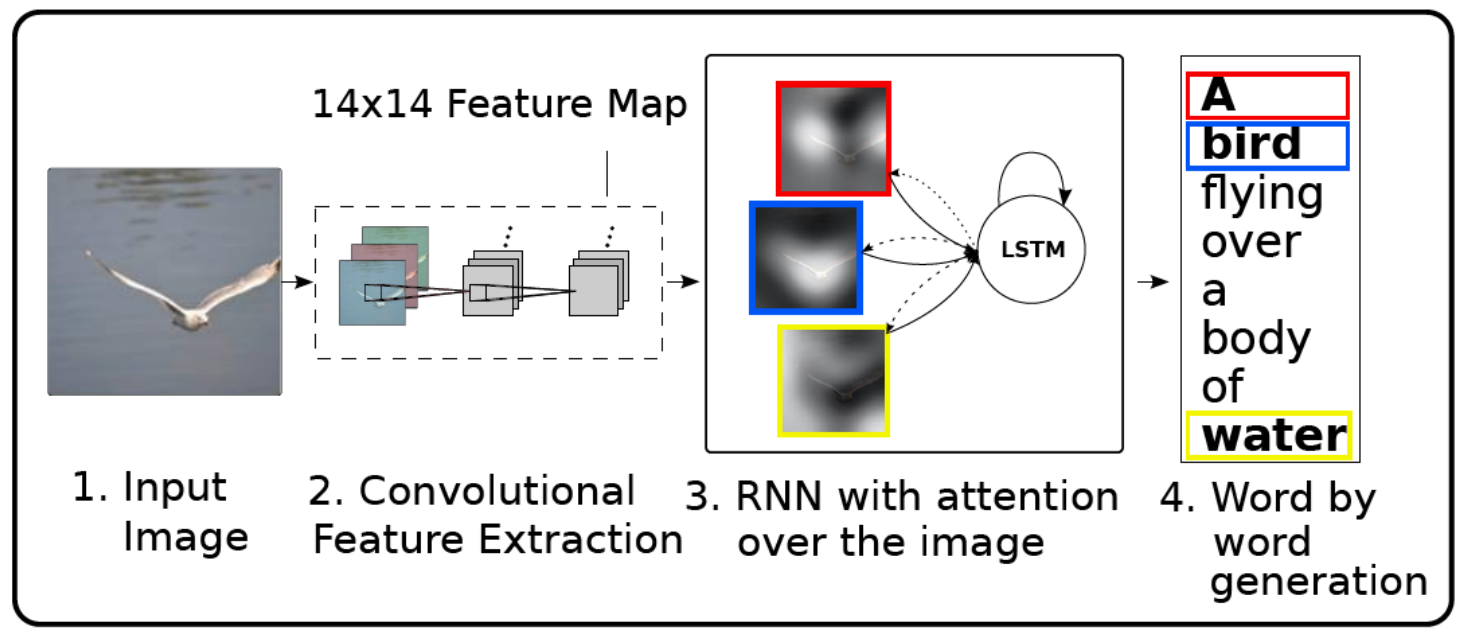
1 输入图片,不获取CNN的全连接层,而是使用某个卷积层的feature。
卷积层有位置信息, 每个位置的值都对应原图中的一个区域。每个channel对应位置相同。例如在一个MxMxC的特征中,对(i,j)这个位置对应原图中的某一块区域,不同channel的(i,j)的值都对应原图中的同一块区域。
我们把不同channel,同一个位置的值抠出来,当做一个向量,代表这个区域的特征表达,最后会得到MxM个位置信息。
2 将这MxM个特征送入RNN网络中,会为不同位置的特征赋予不同的注意力。不同位置的图可能会输出不同的词:bird、water、over。

a对应图片中每个位置的权重
e t i e_{ti} eti是通过对第i个位置的信息和上一步记忆做函数变换
α t i \alpha _{ti} αti表示t时刻位置i的权重(注意力)
14x14x256(怎么会有256个通道?)
问题:一个LSTM同时做了两件事情:attention和分类。这会导致同样大小的区块存了更多的内容。
- top down attention
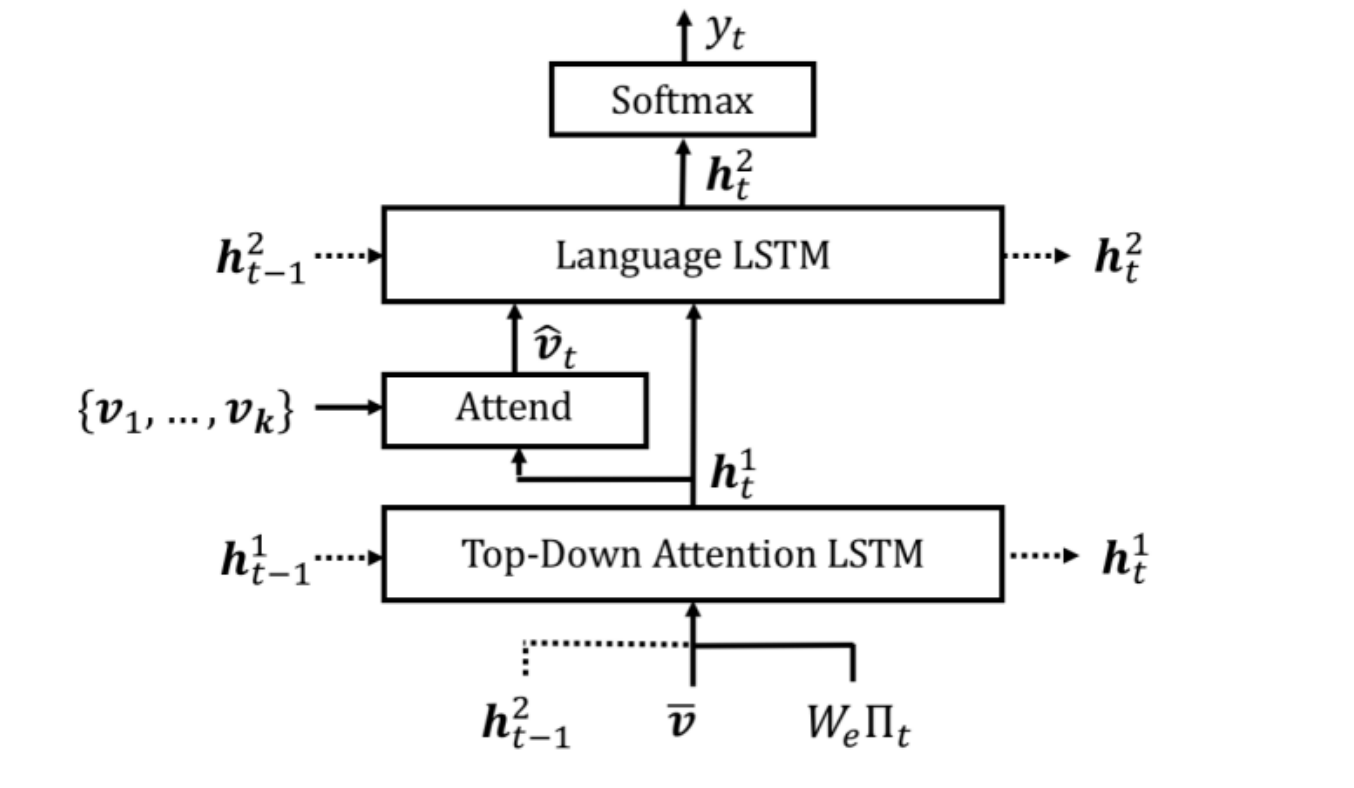
第一层top-down attention LSTM负责学习attention。输入是上一时刻第二层LSTM的记忆 h t − 1 2 h_{t-1}^2 ht−12、图像的全局信息(所有feature map的平均) v v v,输入词语的embedding。
这一层的输出与图像特征做加权学习到attention。
第二层language LSTM 是用于分类预测的。输入是attention以及第一层的输出。
此外这个模型的特点是对原始图片使用selective detection,选取了不同的原始区域作为特征提取。在上一个模型中使用的是一样大小的特征区域,这会影响效果。