前言
在Keras中,我们最常用到的是使用Sequencial 模型来搭建神经网络模型。
Sequencial搭建模型特别的简单、直接,但是缺点是这种途径无法搭建非线性的模型(例如残差网络),无法搭建多个输入、多个输出的模型。
本博客就是介绍如何使用Keras里面函数式API 搭建非线性、多输入输出的神经网络模型。
Keras 函数式API
Keras 函数式API——翻译前叫做 Keras functional API—— 是指可以将Keras里面创建的层(layer)或者模型(Model) 当做一个函数,这种函数可以接受张量作为参数,输出被处理后的张量。
例如:
dense = layers.Dense(64, activation="relu")
那么dense可以作为一个函数来使用了,因此如下的调用是合法的:
x= dense(inputs)
其中inputs 也是一个张量。
Keras 把每一个函数式API都当做一个神经网络运算图里面的节点来处理,每创建一个函数式API就往当前的计算图添加了一个新的节点,而节点与节点之间的边则是通过张量来联系起来的。
当把所需的计算节点和计算图构建好后,再调用 keras.Model 来指定好模型的输入、输出就可以啦。调用keras.Model 主要是为了方便使用Model对象的fit函数来给模型灌入数据。
接下来,我们举几个例子说明如何用Keras functional API来构建复杂的模型。
构建简单的残差网络
首先,构建计算图:
inputs = keras.Input(shape=(32, 32, 3), name="img")
x = layers.Conv2D(32, 3, activation="relu")(inputs)
x = layers.Conv2D(64, 3, activation="relu")(x)
block_1_output = layers.MaxPooling2D(3)(x)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(block_1_output)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
block_2_output = layers.add([x, block_1_output])
#block_1_output 直接跳过两个卷积层
x = layers.Conv2D(64, 3, activation="relu", padding="same")(block_2_output)
x = layers.Conv2D(64, 3, activation="relu", padding="same")(x)
block_3_output = layers.add([x, block_2_output])
#block_2_output 直接跳过两个卷积层
x = layers.Conv2D(64, 3, activation="relu")(block_3_output)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(256, activation="relu")(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(10)(x)
调用keras.Model 函数,将模型的输入输出指定好。
model = keras.Model(inputs, outputs, name="toy_resnet")
model.summary()
计算图:

模型训练的时候,调用fit函数给喂进去数据就可以了。
多输入,多输出模型
假如说,我们有如下这么一个模型道路交通流量拥堵模型:
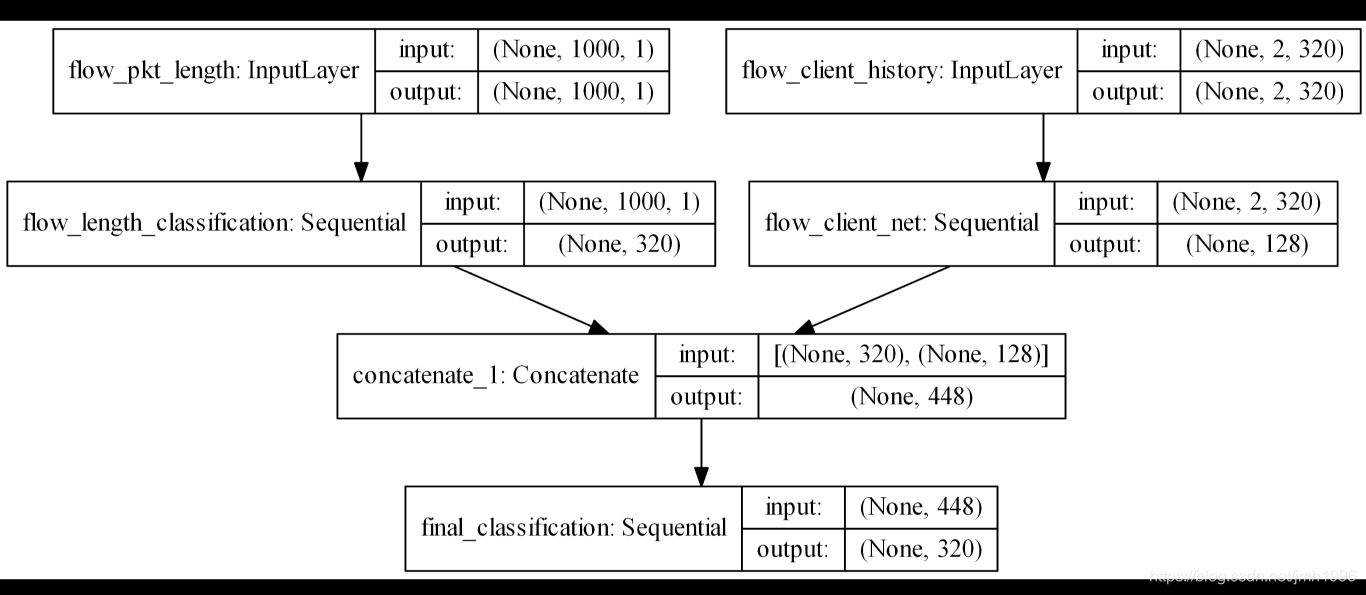
这个模型会有两个输入,一个是交通流量的历史信息,另外一个是交通流量的长度信息。
这两个输入分别要走不同的神经网络做特征提取。长度信息走flow_length_classification分支,而历史信息的走flow_client_net 这一支。最后,再把两部分信息concate起来,做最后的分类。
而且,我们还想把flow_length_classification 的输出也做为一项输出。
我们应该如何搭建呢?
搭建计算图:
with self.session.as_default():
with self.graph.as_default():
self.flow_pkt_length = Input(shape=(self.flow_length,1),name='flow_pkt_length')
self.flow_client_history = Input(shape=(self.frame_length,self.nb_classes),name='flow_client_history')
self.flow_length_vector = self.flow_sidechannel_extractor(self.flow_pkt_length)
self.flow_client_history_vector = self.flow_client_extractor(self.flow_client_history)
vectors = Concatenate()([self.flow_length_vector, self.flow_client_history_vector])
self.flow_label = self.flow_final_classification(vectors)
调用keras.Model函数,将输入输出串起来:
self.model = Model(inputs=[self.flow_pkt_length,self.flow_client_history],
outputs=[self.flow_length_vector,self.flow_label],name='FP-Net')
因为有两个输出,compile模型的时候需要给每个输出指定相应的loss和metrics:
with self.session.as_default():
with self.graph.as_default():
#使用Adamx 训练方法
OPTIMIZER = Adamax(lr=1e-4,
beta_1=0.9,
beta_2=0.99,
epsilon=1e-8,
decay=0)
self.model.compile(optimizer=OPTIMIZER,
#评价指标,使用准确率作为评价指标
metrics={
'flow_length_classification': "accuracy",
'final_classification': "accuracy"
},
#两个loss,第一部分是基于流的包长序列的loss,第二部分是基于包长序列和客户端历史信息的loss
loss={
'flow_length_classification': "categorical_crossentropy",
'final_classification': "categorical_crossentropy"
},
#两个loss的权重,
loss_weights={
'flow_length_classification': 0.3,
'final_classification':0.7,
})
值得注意的是,我们在指定loss和metrics的时候 用的是字典,其中key表示输出tensor的名字,这个名字是我们搭建模型给定的。'flow_length_classification’和’final_classification’两个子网络的名字,而不是子网络最后一层tensor的名字,因为我的模型里面两个子网络用Sequencial搭建的。
训练的时候,我们这样喂数据:
self.model.fit({
'flow_pkt_length': X_train_pkt_length,
'flow_client_history': X_train_client_history
},{
'flow_length_classification' : y_train,
'final_classification': y_train
},validation_data=({
'flow_pkt_length': X_valid_pkt_length,
'flow_client_history': X_valid_client_history
},{
'flow_length_classification' : y_valid,
'final_classification': y_valid
}
),
epochs = 50,
batch_size=128,
verbose=2
)
我们喂数据,也是通过tensor字符串模型来喂输入数据的。'flow_pkt_length’和’flow_client_history’是两个keras.Input 的名字。