需求
给定两个json格式文件,base,rely,比对两个json差异并将结果保存到excle
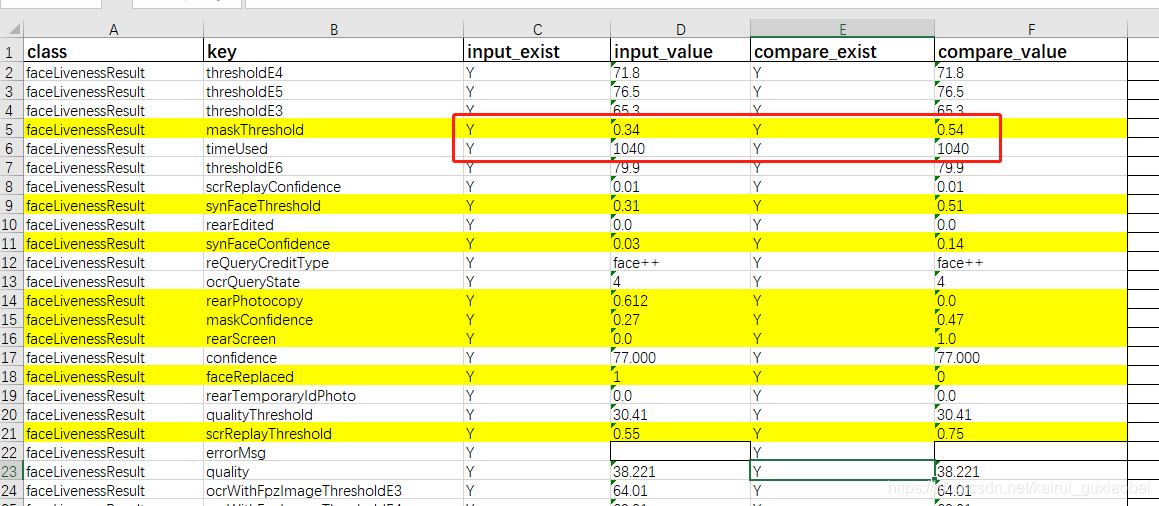
形如:记录key是否存在,并比较value值 不相等的标黄色。
代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/7/29 10:44
# @Author : zhouwang
# @Site :
# @File : demo.py
# @Software: PyCharm
import os
import json
import openpyxl
from openpyxl.styles import PatternFill
from gevent import monkey
monkey.patch_all() # 必须写在最上面,这句话后面的所有阻塞全部能够识别了
import gevent # 直接导入即可
import threading
threadLock = threading.Lock()
def get_by_test(json_path,key,value):
"""
key,value 是否存在json中。
:param json:
:param key:
:param value:
:return: 是否存在状态,若存在返回对应value值
"""
base_json = os.path.join(os.getcwd(), json_path)
with open(base_json, 'rb') as f:
base_info = json.loads(f.read())
if key in base_info:
if value in base_info[key]:
status="Y"
Value=str(base_info[key][value])
else:
status = "N"
Value = ''
else:
status="N"
Value=''
return status,Value
def json_to_excle(path):
"""
{a:{a1:,a2:,a3:}}====>[[a,a1],[a,a2],[a,a3]]
:param path:
:return:
"""
with open(path, 'rb') as f:
base_info = json.loads(f.read())
lis = []
for i in base_info.keys():
#判断字典类型
if isinstance(base_info[i], dict):
for j in base_info[i].keys():
lis.append([i, j])
return lis
def write_excle(path,row,column,sheetname,value,fill=None):
#判断文件是否存在
p1 = os.path.exists(path)
if not p1:
#不存在新建
wb = openpyxl.Workbook()
else:
# 打开文件
wb = openpyxl.load_workbook(path)
# 修改当前工作表的名称
sheet = wb.active
# 修改工作表的名称
sheet.title = sheetname
sheet = wb[sheetname]
#搞点颜色
if fill:
sheet.cell(row=row, column=column, value=value).fill=fill
else:
sheet.cell(row=row, column=column, value=value)
#保存文件
wb.save(filename=path)
def b_comp_r(basepath,relypath,resultpath,sheetname,fill):
"""
两个json比较 ,默认base作为结果记录对象
:param basepath:
:param relypath:
:param resultpath:
:count 线程数量
:return:
"""
#读base
baseResult=json_to_excle(basepath) #[[a,a1],[a,a2],[a,a3]]
#结果比较
for i in range(len(baseResult)):
print(i)
statusa,Valuea=get_by_test(basepath, key=baseResult[i][0], value=baseResult[i][-1])
statusr, Valuer = get_by_test(relypath, key=baseResult[i][0], value=baseResult[i][-1])
#写入excle
if str(Valuea)==str(Valuer):
g1 = gevent.spawn(write_excle, resultpath,row=i+2, column=1, sheetname=sheetname, value=baseResult[i][0], fill=None)
g2 = gevent.spawn(write_excle, resultpath,row=i + 2, column=2, sheetname=sheetname, value=baseResult[i][-1], fill=None)
g3 = gevent.spawn(write_excle,resultpath, row=i + 2, column=3, sheetname=sheetname, value=statusa, fill=None)
g4 = gevent.spawn(write_excle, resultpath,row=i + 2, column=4, sheetname=sheetname, value=Valuea, fill=None)
g5 = gevent.spawn(write_excle,resultpath, row=i + 2, column=5, sheetname=sheetname, value=statusr, fill=None)
g6 = gevent.spawn(write_excle, resultpath,row=i + 2, column=6, sheetname=sheetname, value=Valuer, fill=None)
else:
g1 = gevent.spawn(write_excle, resultpath, row=i + 2, column=1, sheetname=sheetname, value=baseResult[i][0],fill=fill)
g2 = gevent.spawn(write_excle, resultpath, row=i + 2, column=2, sheetname=sheetname,value=baseResult[i][-1], fill=fill)
g3 = gevent.spawn(write_excle, resultpath, row=i + 2, column=3, sheetname=sheetname, value=statusa,fill=fill)
g4 = gevent.spawn(write_excle, resultpath, row=i + 2, column=4, sheetname=sheetname, value=Valuea,fill=fill)
g5 = gevent.spawn(write_excle, resultpath, row=i + 2, column=5, sheetname=sheetname, value=statusr,fill=fill)
g6 = gevent.spawn(write_excle, resultpath, row=i + 2, column=6, sheetname=sheetname, value=Valuer,fill=fill)
gevent.joinall([g1, g2, g3, g4, g5, g6])
def bisector_list(tabulation:list,num:int):
"""
将列表平均分成几份
:param tabulation: 列表
:param num: 份数
:return: 返回一个新的列表
"""
new_list = []
'''列表长度大于等于份数'''
if len(tabulation)>=num:
'''remainder:列表长度除以份数,取余'''
remainder = len(tabulation)%num
if remainder == 0:
'''merchant:列表长度除以分数'''
merchant = int(len(tabulation) / num)
'''将列表平均拆分'''
for i in range(1,num+1):
if i == 1:
new_list.append(tabulation[:merchant])
else:
new_list.append(tabulation[(i-1)*merchant:i*merchant])
return new_list
else:
'''merchant:列表长度除以分数 取商'''
merchant = int(len(tabulation)//num)
'''remainder:列表长度除以份数,取余'''
remainder = int(len(tabulation) % num)
'''将列表平均拆分'''
for i in range(1, num + 1):
if i == 1:
new_list.append(tabulation[:merchant])
else:
new_list.append(tabulation[(i - 1) * merchant:i * merchant])
'''将剩余数据的添加后面列表中'''
if int(len(tabulation)-i*merchant)<=merchant:
for j in tabulation[-remainder:]:
new_list[-1].append(j)
return new_list
else:
'''如果列表长度小于份数'''
for i in range(1, len(tabulation) + 1):
tabulation_subset = []
tabulation_subset.append(tabulation[i - 1])
new_list.append(tabulation_subset)
return new_list
class myThread (threading.Thread):
def __init__(self, threadID, basepath,relypath,resultpath,sheetname,fill,count, index):
threading.Thread.__init__(self)
self.threadID = threadID
self.count = count
self.index = index
self.basepath=basepath
self.relypath=relypath
self.resultpath=resultpath
self.sheetname=sheetname
self.fill=fill
def run(self):
print ("开启线程: " + str(self.threadID))
# 获取锁,用于线程同步
threadLock.acquire()
b_comp_r_bak(self.basepath,self.relypath,self.resultpath,self.sheetname,self.fill,self.count,self.index)
# 释放锁,开启下一个线程
threadLock.release()
def b_comp_r_bak(basepath,relypath,resultpath,sheetname,fill,count,index):
"""
两个json比较 ,默认base作为结果记录对象
:param basepath:
:param relypath:
:param resultpath:
:count 线程数量
:return:
"""
#读base
baseResult=json_to_excle(basepath) #[[a,a1],[a,a2],[a,a3]]
#结果比较
# lis=bisector_list(baseResult, count)
lis1=bisector_list(list(range(len(baseResult))),count)
print(lis1[index][0])
print(lis1[index][-1]+1)
for i in range(lis1[index][0],lis1[index][-1]+1):
statusa,Valuea=get_by_test(basepath, key=baseResult[i][0], value=baseResult[i][-1])
statusr, Valuer = get_by_test(relypath, key=baseResult[i][0], value=baseResult[i][-1])
#写入excle
if str(Valuea)==str(Valuer):
g1 = gevent.spawn(write_excle, resultpath,row=i+2, column=1, sheetname=sheetname, value=baseResult[i][0], fill=None)
g2 = gevent.spawn(write_excle, resultpath,row=i + 2, column=2, sheetname=sheetname, value=baseResult[i][-1], fill=None)
g3 = gevent.spawn(write_excle,resultpath, row=i + 2, column=3, sheetname=sheetname, value=statusa, fill=None)
g4 = gevent.spawn(write_excle, resultpath,row=i + 2, column=4, sheetname=sheetname, value=Valuea, fill=None)
g5 = gevent.spawn(write_excle,resultpath, row=i + 2, column=5, sheetname=sheetname, value=statusr, fill=None)
g6 = gevent.spawn(write_excle, resultpath,row=i + 2, column=6, sheetname=sheetname, value=Valuer, fill=None)
else:
g1 = gevent.spawn(write_excle, resultpath, row=i + 2, column=1, sheetname=sheetname, value=baseResult[i][0],fill=fill)
g2 = gevent.spawn(write_excle, resultpath, row=i + 2, column=2, sheetname=sheetname,value=baseResult[i][-1], fill=fill)
g3 = gevent.spawn(write_excle, resultpath, row=i + 2, column=3, sheetname=sheetname, value=statusa,fill=fill)
g4 = gevent.spawn(write_excle, resultpath, row=i + 2, column=4, sheetname=sheetname, value=Valuea,fill=fill)
g5 = gevent.spawn(write_excle, resultpath, row=i + 2, column=5, sheetname=sheetname, value=statusr,fill=fill)
g6 = gevent.spawn(write_excle, resultpath, row=i + 2, column=6, sheetname=sheetname, value=Valuer,fill=fill)
gevent.joinall([g1, g2, g3, g4, g5, g6])
if __name__=="__main__":
basepath, relypath,resultpath = os.path.join(os.getcwd(), 'base.json'), os.path.join(os.getcwd(), 'rely.json'),os.path.join(os.getcwd(), 'test_result.xlsx')
sheetname='Sheet1'
fill = PatternFill(start_color='FFFF00', end_color='FFFF00', fill_type='solid')
# b_comp_r(basepath, relypath, resultpath, sheetname, fill)
threads = []
# 创建新线程 threadID, basepath,relypath,resultpath,sheetname,fill,count, index
# for i in range(3):
# thread = myThread(i+1, basepath,relypath,resultpath,sheetname,fill,count, i)
# # 开启新线程
# thread.start()
# # 添加线程到线程列表
# threads.append(thread)
# 等待所有线程完成
# for t in threads:
# t.join()
count = 5
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=5) as t: # 创建一个最大容纳数量为5的线程池
# b_comp_r_bak(self.basepath,self.relypath,self.resultpath,self.sheetname,self.fill,self.count,self.index)
task1 = t.submit(b_comp_r_bak, basepath,relypath,resultpath,sheetname,fill,count,0)
task2 = t.submit(b_comp_r_bak, basepath,relypath,resultpath,sheetname,fill,count, 1) # 通过submit提交执行的函数到线程池中
task3 = t.submit(b_comp_r_bak, basepath,relypath,resultpath,sheetname,fill,count, 2)