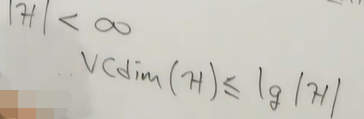Statistical Learning
Theorem
该Theorem的提出和表示很大程度上是对PAC准则的一个借鉴,不了解PAC准则的读者建议先去该系列上一篇文章《【AI数学基础|寒假集训课】Statistical Learning(1)》中的【PAC准则】部分了解一下。
- 表达一
【定理】
p.s. 其中【保持一致】的含义就是指模型在这m个训练数据上是无差错的

【意义】
①如果训练出来的模型想要达到一个给定的精度(δ,ε),那么所需的训练数据规模有一个下界
②如果给定了一定数量规模的训练数据,那么可以推断出模型能够达到的精度下界
- 表达二
【定理】
p.s. 表达一和表达二是完全等价的,将Pr[err(h)>ε]≤δ,改写成Pr[err(h)≤ε]>1-δ
故在1-δ的确信度下,可以得到err(h)≤ε,将表达一中m和δ、ε的不等式进行变形,就可以得到表达二中errd(hA)与δ、m、ε的关系

- 一些注意事项
- ①机器学习的三个准则
在该系列上一篇文章《【AI数学基础|寒假集训课】Statistical Learning(1)》中讲到机器学习的三个准则有:充足的数据、与训练数据保持一致的假设和简易的假设。
在上述定理中对该三个条件均有体现——在一致性的假设下,给定了足够大的m个数据样本,就能得到模型精确度的相关估计。
- ②模型复杂度的直观估计
根据定理中m的下界表达式,也可以得出——如果我们训练的模型越复杂(ln|H|的值就会越大),要想或的准确的预测准则,就需要更大的数据样本(m的下界也就相应增大了)。

Theorem的证明
- 问题重述
我们的目标是对上文提出的定理进行证明,但是上文定理的描述只是“针对学习算法A,存在学到的一个假设”;在这个部分,我们把定理描述得更趋向一般化。
【定理描述的关联】
该一般化后的定理除了将“存在性条件”加强到“一般性”以外,其余描述都是相同的。
如果我们能够证明这个一般性的定理成立,那么也就说明了所有一致性的假设都可以满足我们规定的概率准则,换句话说也就可以找到某一个假设满足概率准则,从而证明了原定理成立。


- 逻辑语言表示

- 证明过程
- 注意分辨什么是随机变量,什么不是随机变量
- 将所有一致性的假设统一组成了一个集合B
- 多次使用了不等式的放缩,用到了集合的基、m的不等式来辅助,以及使用了(1+e)x≤ex的结论

Theorem的无限化推广
在本文第一部分有关Theorem的描述和证明都是建立在假设空间有限(|H|<∞)的前提下,该部分通过引入增长函数将有限空间复杂度因子转换成无限空间的有限训练集的增长函数(worst bound)。
- 实例——阈值函数预测
在讲述PAC准则时我们曾演算过这个例子的概率准则,当时这个问题是定义在假设空间无限大的情况下,现如今我们只给定有限个(m=4)训练数据点。
在数轴上给定四个点,通过这四个点我们只能得到5种不同的预测模式:

更一般来说,如果我们在这个无限大的假设空间中我们有n个点,那么我们就应该能得到最多n+1种预测模式;但如果不考虑这里的问题情景,有n个点,对每个点进行正或负的二值预测,那么纯理论计算来说我们会得到2n种假设模式;n+1和2n相比已经是很大程度的缩小了。
给定一个M大小的数据样本,通过对这些数据样本的不同标记可以形成一种有效的假设空间,用以代替完整的假设空间。
-
增长函数

πH(m)被称为增长函数,在上面的实例中,πH(4) = 1+4 = 5,πH(S)如下所示:
{<+,+,+,+>,<-,+,+,+>,<-,-,+,+>,<-,-,-,+>,<-,-,-,->} -
Theorem表示

根据老师的讲述(没有证明),对于任意一个假设空间,其增长函数只可能呈现两种情况——
对于假设空间的增长函数的求解,可以用于判断什么时候可以进行学习;
- 在nice case下学习是可行的,根据上文的概率推导准则,我们可以快速降低模型的泛化错误;
- 但是在worst case下学习是不可行的。

- VC维度
在第3点的讨论中,我们给出了在nice case的情况下,增长函数是呈多项式增长的,即O(md),其中可证d的值就是所谓的【VC维度】
- ①scatter
对于当前我们处理的假设空间H,给定一个大小为m的样本集:
如果样本集中对m个样本所有可能的标签标记情况都能被假设空间H满足,就说这个样本集S可以被假设空间H scatter
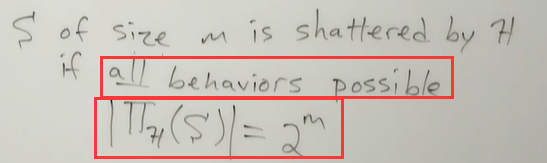
- ②VC dim
VC维度就是可以被当前假设空间H scatter的样本集的最大size
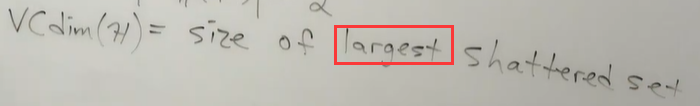
- EXs:
VC dim=2
VC dim = n+1;VC dim = n;


- ③特点:
- VC维度的值常常和分界线的方程中的参数个数相同,也存在不等的情况;
- 如果假设空间H是有限的,其VC维度的上界就是该假设空间的复杂性度量
p.s. 因为大小为lg|H|的样本,按照二分类的标签,最多也只有|H|种不同的标记方式