深度卷积网络及其实例分析
经典网络
LeNet-5
1. 网络结构
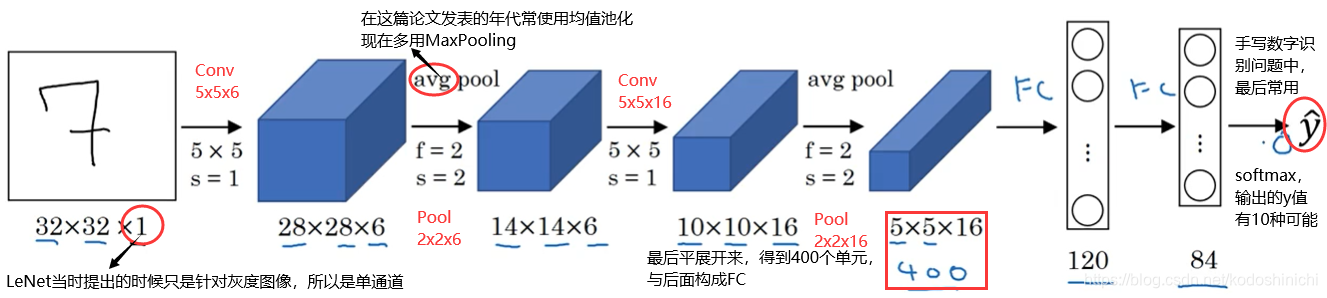
2. 网络模式
从这个网络中可以看到卷积网络的一般特点,以及现在也经常使用的搭建模式。
- 随着网络层数的加深,数据的尺寸(长x宽)会逐渐缩小,但数据的信道会逐渐增多
- 深度卷积神经网络往往会按照【conv-…-conv-pool-conv-…-conv-pool-FC-FC】的模式进行搭建,即多个卷积层后跟一个池化层,最后连接若干全连接层得到模型的输出。
LeNet-5
1. 网络结构
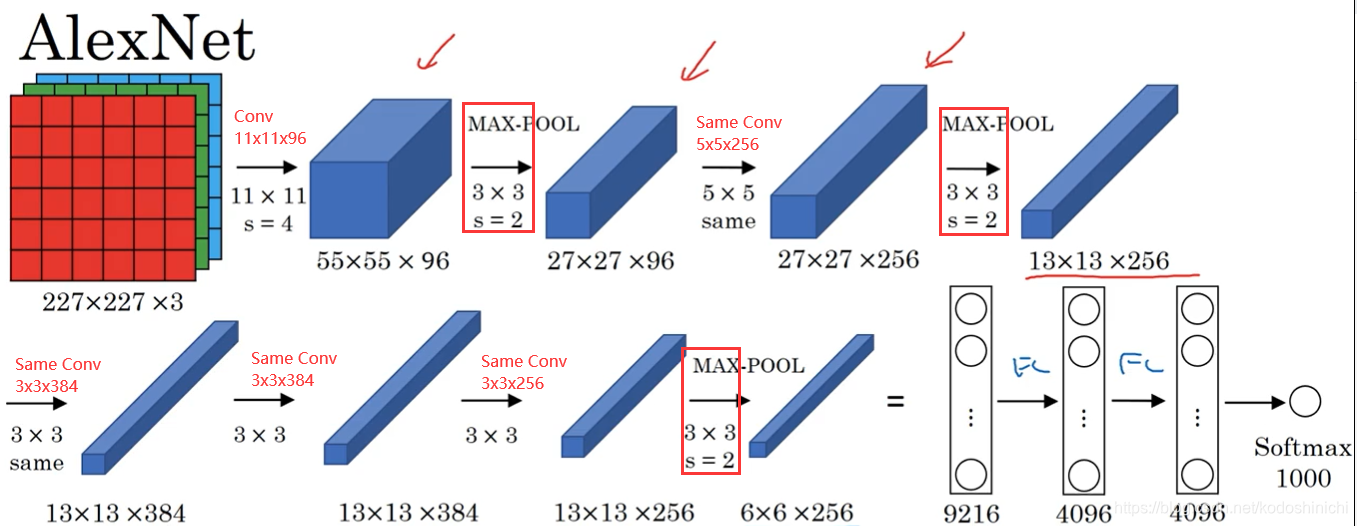
2. 网络模式
AlexNet的网络构建理念与LeNet差不多,但是显然AlexNet更加复杂。
- 比起LeNet网络,AlexNet有更加大量的网络参数
- 在论文的实现与讨论中,实际上还加入了LRU(局部响应归一化层),但这项技术在现在被认为作用甚微。
VGG-16
1. 网络结构
相较之前讨论的网络结构,这是一种只需要专注于构建卷积层的网络。
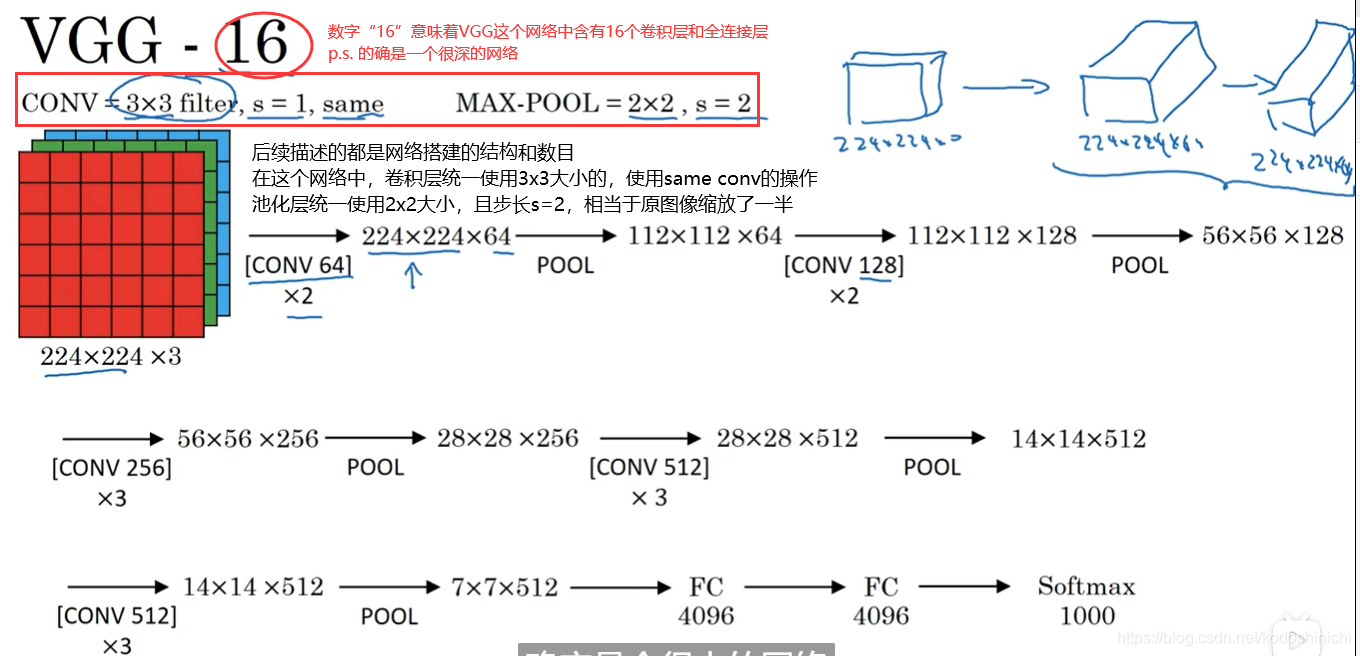
2. 网络模式
- 网络的确很大,总共包含约1.38亿个参数
- 但是VGG-16的网络结构并不复杂,结构很规整——几个卷积层后面跟着可以压缩图像大小的池化层
- 卷积层的过滤器数量变化也存在一定的规律:从64变成128,再到256和512;在每一组卷积层进行过滤器数目的翻倍操作。
- 因为网络结构按照【若干卷积-池化】这样组织得很规整,且每一组卷积都会进行过滤器数目的翻倍,每一次池化都会折半数据的大小,这就使得——图像缩小的比例和信道增加的比例是有规律的。
残差网络
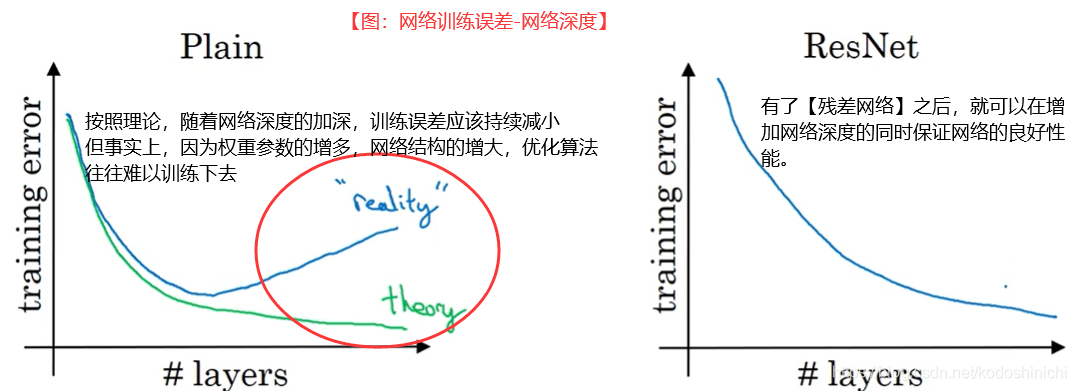
事实上,搭建深层的神经网络并不是那么容易的事情,因为梯度消失和梯度爆炸现象的存在。因此我们提出了【远跳连接】
远跳连接:可以从某一个网络层获取激活值,然后迅速反馈给另外一层,甚至反馈给神经网络的更深层;
我们可以利用远跳连接构建可以训练深度网络的ResNets。
残差网络的定义与结构
“使用残差块可以构建一个很深的神经网络,因此ResNet就是将若干个残差快堆积在一起,形成一个深度神经网络”
1. 残差块
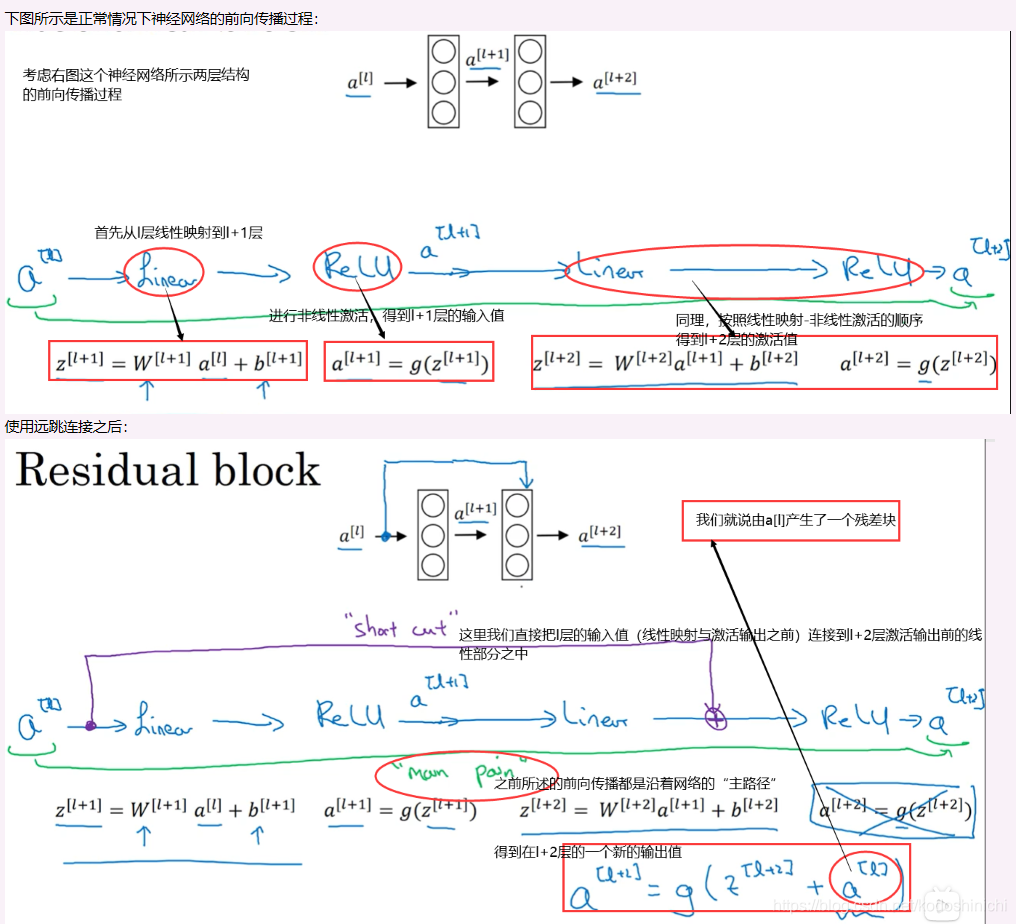
2. 残差网络

3. 残差网络的优势
过去的深度神经网络,随着网络的进一步加深,大量的参数会使得网络变得臃肿,难以使用优化算法进行训练。
残差网络的出现可以解决这个问题,它使得输入X的激活值可以到达更深层处的网络中,以应对深度神经网络的梯度消失和梯度爆炸的问题。
为什么残差网络具有良好性能?
1. 残差网络可以高效地学习得到恒等式
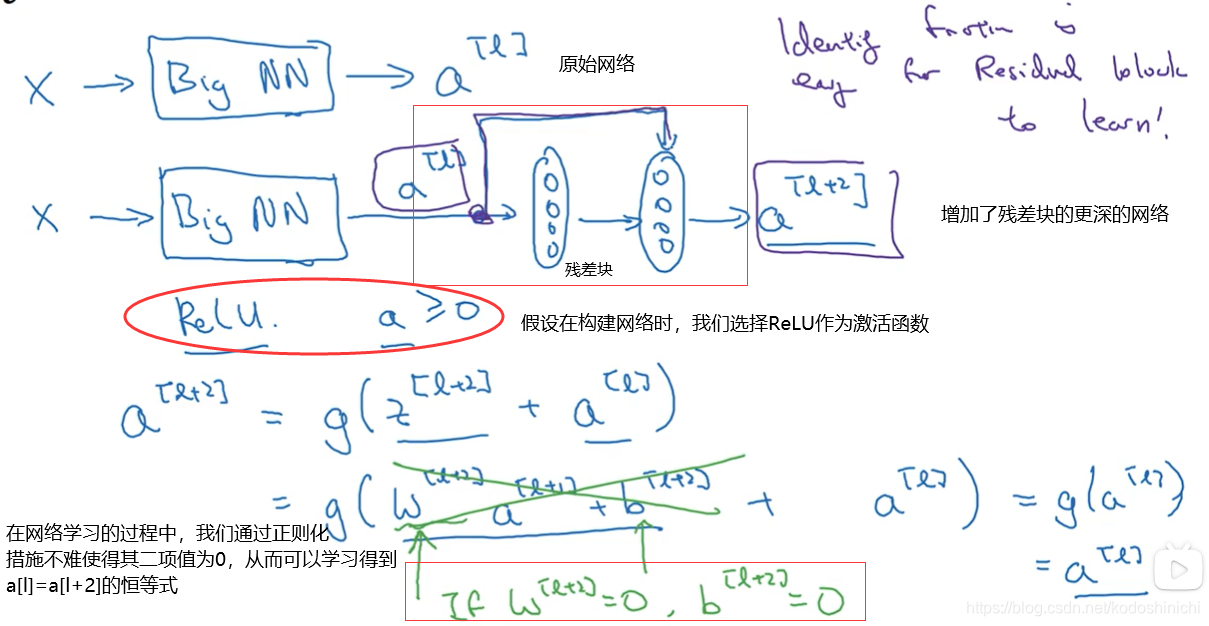
2. 效率之外
残差块中包含的隐层单元也会学习到更多隐含信息,其效果可能会更优于【恒等函数】
1x1卷积
1. 计算机制
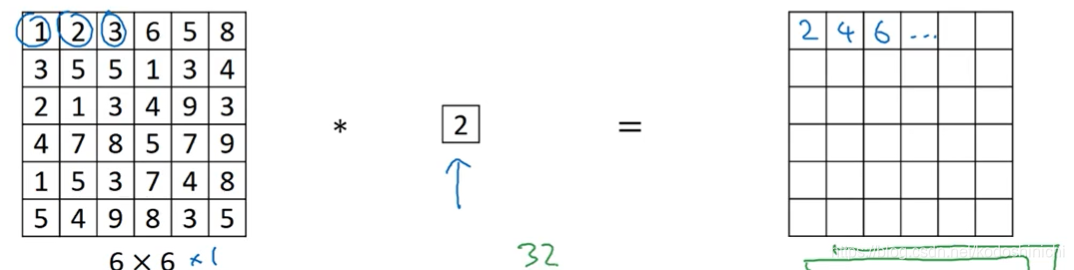
- 对于单通道的数据而言,1x1卷积只是对所有的width×height个数据单元逐一进行数乘运算
- 对于多通道的数据(widthxheightxchannel),进行1x1卷积则相应需要1x1xchannel大小的卷积核,每次卷积——逐一遍历widthxheight个单元,每个单元将所有通道内的channel个数据组成的数据向量和卷积核相应的数据向量进行点乘运算。
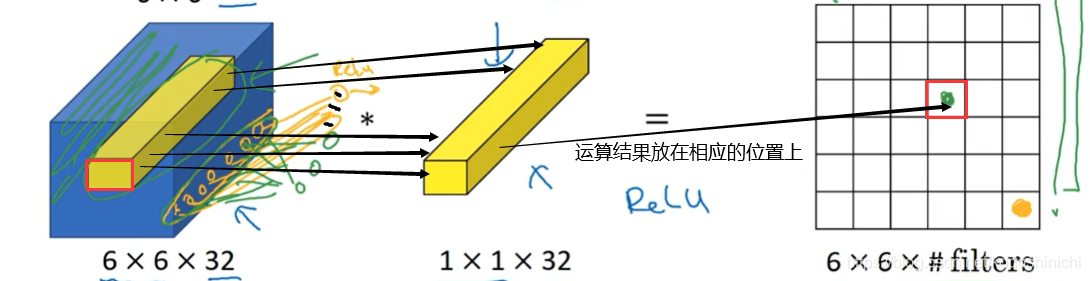
1x1卷积通常又被称作是network in network,因为每一个卷积核都可以看做是一个全连接层的神经元,原数据传来channel个输入数据,和该神经元的channel个权重进行运算后进行输出;若改变卷积核的个数,则相当于改变了该层神经元的数目,改变了输出的个数。
2. 计算意义
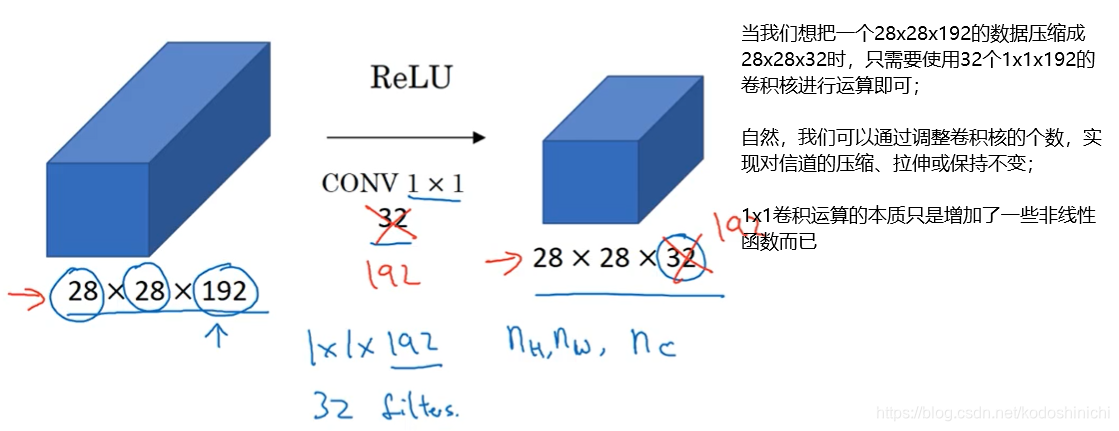
简言之,通过在神经网络中引入1x1卷积的概念,可以轻松地改变数据的深度。
前面讲述卷积的相关知识时,我们已经知道了通过卷积运算和池化运算,可以方便调整传入数据的宽度和长度;现在我们又学习到通过1x1卷积可以方便对传入数据的深度进行压缩或拉伸。
迁移学习
所谓迁移学习,可以下载别人已经训练好的开源的权重参数,将其作为自己神经网络上的初始化参数,用【迁移学习】将公共数据集上的知识迁移到自己的问题上。
现假设我们需要针对猫的图像做一个三分类的问题:
- 当我们所拥有的数据集较小时:
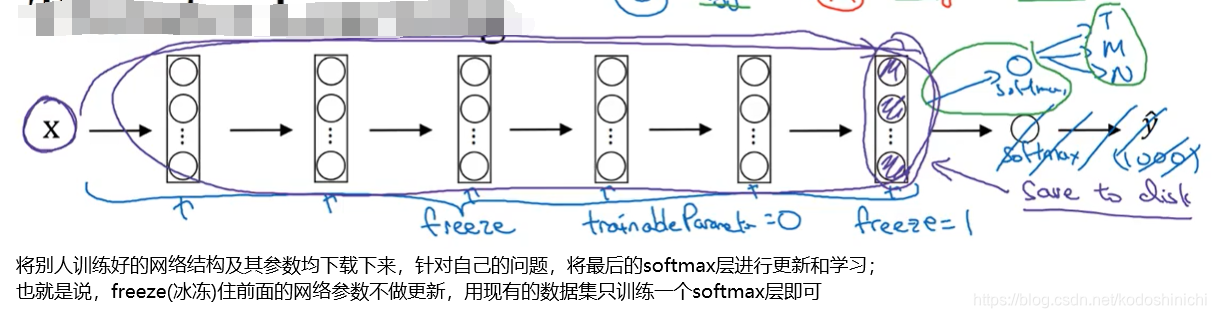
在这一步还有一个可用的trick——因为网络结构从输入直到最后的softmax之前都是固定不变的,所以我们可以预先将每个原始数据丢到网络中,学习出其在最后softmax层之前的映射值作为该原始数据的特征向量,并存储在硬盘中;
之后进行训练,可以直接从硬盘中读取特征向量作为输入进行网络的学习。
- 当所具有的数据集较大时:
“一个基本规律是——当你具有的数据量越多,所需冷冻的网络层数就越少,可以训练的网络层数和参数相应越多”
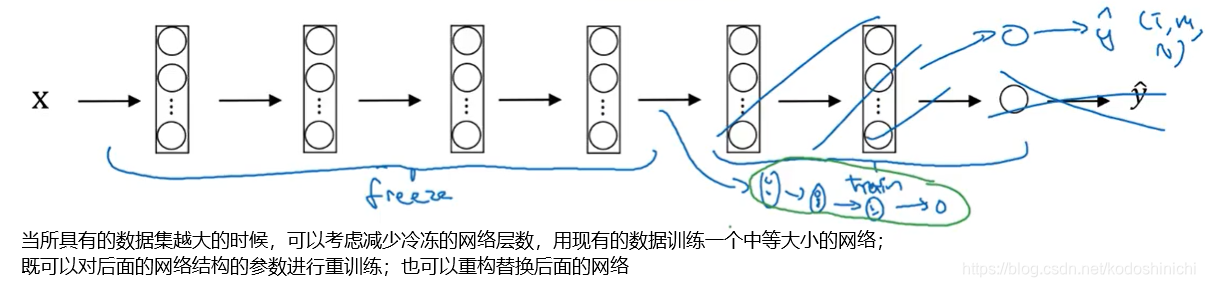
- 当数据集很大时,我们可以将别人预训练好的网络结构及参数作为初始化,然后重新训练整个网络。