爬虫 scrapy框架
安装命令:
命令: sudo apt-get install scrapy
或者: pip/pip3 install scrapy
流程:
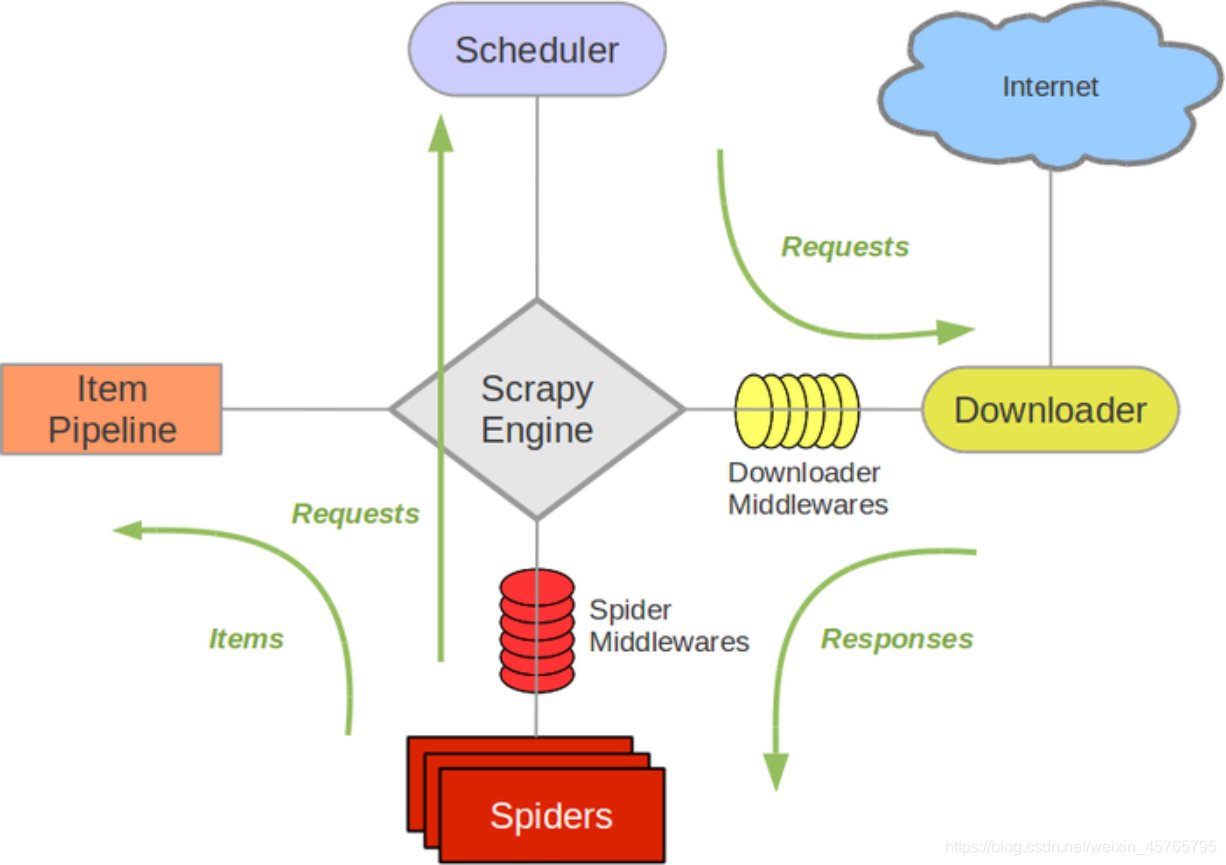



项目开发流程:
提示:终端使用命令
1、创建项目: scrapy startproject <项目名字>
2、生成爬虫: scrapy genspider <爬虫名字例如:OIE> <域名例如:OIE.int>
3、提取数据: 根据网站结构在spider中实现数据采集相关内容
4、保存数据: 使用pipeline进行数据后序处理和保存
创建项目:
创建scrapy项目的命令: scrapy startproject <项目名字> 例如:scrapy startproject myspider
1、 框架生成结果
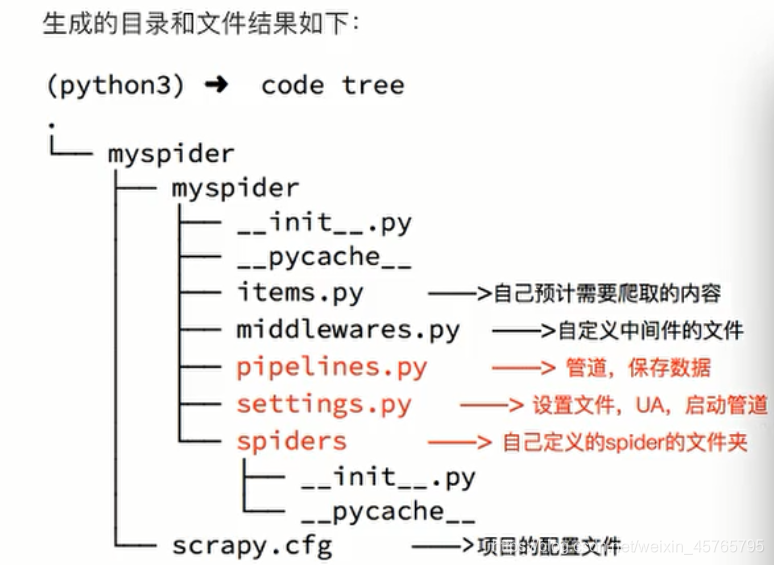
2、 总结:

3、 创建爬虫
3.1 scrapy genspider 爬虫名字 允许爬虫
3.2 爬虫文件介绍
三个参数:
name
allowed_domains
start_urls 设置起始的url,我们只需要设置就好,通常会被自动的创建成请求发送
一个方法:
parse方法 解析方法,通常用于起始url对应响应的解析
完成爬虫:
1、 修改起始的URL
2、检查修改允许的域名
3、 在parse方法中实现爬虫逻辑
4、在pipelines.py文件中定义对数据的操作
这里举例逻辑对数据的一些操作:
例如:连接数据库,从数据库读取数据后在进行xpath操作等
一些代码案例:
class OieSpider(scrapy.Spider):
name = 'oie'
# 2.检查修改allowed_domains
allowed_domains = ['oie.int']
# 1.修改start_url
start_urls = ['https://www.oie.int/wahis_2/public/wahid.php/Diseaseinformation/Immsummary']
def parse(self, response):
# 创建所有URL储存数组
result_nums = []
# 连接数据库
connect = pymysql.connect(
host='localhost', # 数据库地址
port=3306, # 数据库端口
user='root', # 数据库用户名
password='', # 数据库密码
database='state_of_an_illness', # 数据库表名
charset='utf8', # 编码方式
use_unicode=True)
# 通过cursor执行增删查改
cursor = connect.cursor()
result = cursor.execute("""SELECT URL FROM bird_flu""")
for i in range(result):
result_nums.append(cursor.fetchone())
connect.commit()
# 储存所有子路由内的每条数据
result_node = []
count = 0
for i in result_nums:
保存数据:
提示:爬虫里一般都使用yield不使用return,当前方法parse方法返回后,进入pipelines.py文件进入process_item方法传参给item
1、 定义一个管道
2、重写管道类的process_item方法
3、 process_item方法处理完item之后必须返回给引擎
这里举例逻辑对数据的一些操作:
class OiePipeline(object):
"""
定义代理ip的类,这是开放代理的应用
"""
PROXIES = [
'221.180.147.30:8088'
]
def __init__(self):
# 连接数据库
self.connect = pymysql.connect(
host='localhost', # 数据库地址
port=3306, # 数据库端口
user='root', # 数据库用户名
password='', # 数据库密码
database='state_of_an_illness', # 数据库表名
charset='utf8', # 编码方式
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
for i in item:
print("item:", i, "\n")
self.cursor.execute(
"""insert into bird_flu(status, state, URL)
value (%s, %s, %s)""", # 纯属python操作mysql知识,不熟悉请恶补
(item[i][0], # item里面定义的字段和表字段对应
item[i][1],
i,))
# 提交sql语句
self.connect.commit()
return item # 必须实现返回
运行scrapy:
命令:在项目目录下执行 scrapy crawl 爬虫名字 例如: scrapy crawl itcast
或者:运行管理表 ,当重新执行后没有报错则执行,会显示有没有问题: scrapy crawl itcast --nolog

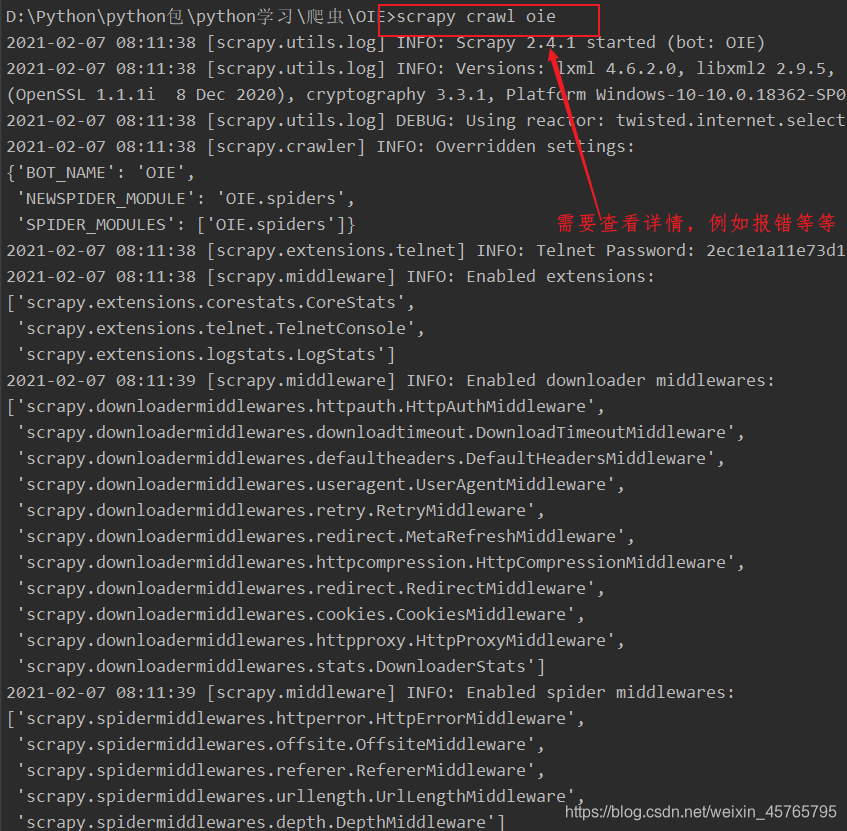
如果加上–nolog则会关闭日志和一些错误信息也不会提示
建模:
\
1、 为什么建模
1.1 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查
1.2 配合注释一起看可以清晰的指导要抓取哪些字段,灭有定义的字段不能抓取,在目标字段少的时候可以使用字典代替
1.3 使用scrapy的一些特定组件需要item做支持,如scrapy的ImagesPipeline管道类,百度搜索了解更多
2、如何建模
例如:
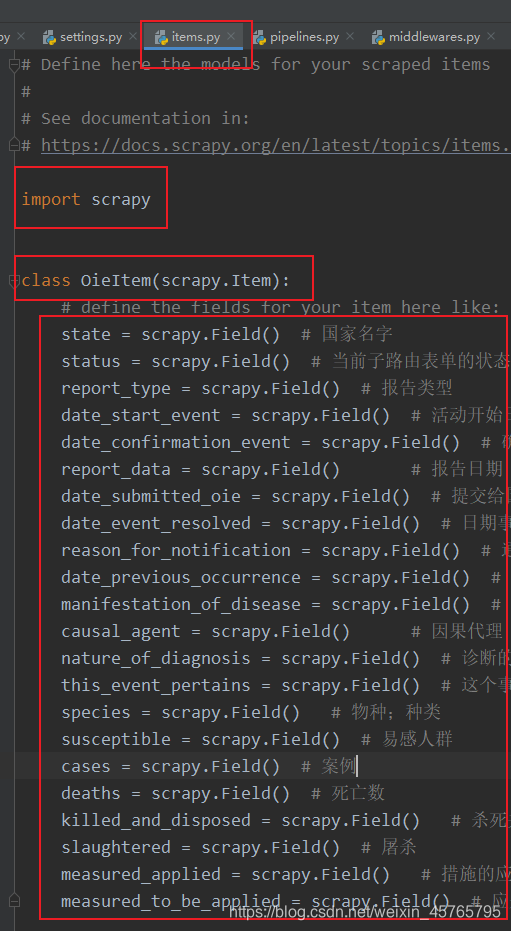
3、 如何使用模板
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同

欢迎积极留言探讨问题~