引入包和超参数设置
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
test_rate = 0.3
mmin_samples_split = 200
mmin_samples_leaf = 5
tree_num = 5
加载数据
feature = pd.read_csv(load_boston()['filename'], header=1)
feature
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222 | 18.7 | 396.90 | 5.33 | 36.2 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 501 | 0.06263 | 0.0 | 11.93 | 0 | 0.573 | 6.593 | 69.1 | 2.4786 | 1 | 273 | 21.0 | 391.99 | 9.67 | 22.4 |
| 502 | 0.04527 | 0.0 | 11.93 | 0 | 0.573 | 6.120 | 76.7 | 2.2875 | 1 | 273 | 21.0 | 396.90 | 9.08 | 20.6 |
| 503 | 0.06076 | 0.0 | 11.93 | 0 | 0.573 | 6.976 | 91.0 | 2.1675 | 1 | 273 | 21.0 | 396.90 | 5.64 | 23.9 |
| 504 | 0.10959 | 0.0 | 11.93 | 0 | 0.573 | 6.794 | 89.3 | 2.3889 | 1 | 273 | 21.0 | 393.45 | 6.48 | 22.0 |
| 505 | 0.04741 | 0.0 | 11.93 | 0 | 0.573 | 6.030 | 80.8 | 2.5050 | 1 | 273 | 21.0 | 396.90 | 7.88 | 11.9 |
506 rows × 14 columns
train_data,test_data = train_test_split(feature,test_size = test_rate, random_state = 42)
valid_data = test_data[0:50]
len(train_data)
354
len(test_data)
152
随机森林模型
def show_multi_curve(true_label, predict_labels):
x = np.array(range(len(true_label)))
plt.plot(x, true_label, label='true label', color = 'g',linewidth=3)
plt.plot(x, np.mean(predict_labels, axis=0), color = 'r', label='mean results',linewidth=3)
for i in range(len(predict_labels)-1):
plt.plot(x, predict_labels[i], color = '#656156',linestyle='--')
plt.plot(x, predict_labels[-1], color = '#656156',label='predicted results',linestyle='--')
plt.axis()
plt.xlabel('point')
plt.ylabel('value')
plt.legend(bbox_to_anchor=(1.4, 1), borderaxespad=0, loc='upper right')
plt.show()
return mean_squared_error(true_label,
np.mean(predict_labels, axis=0)), np.mean([
mean_squared_error(
p, np.mean(predict_labels, axis=0))
for p in predict_labels
])
def show_2curve(pianzhis, fangchas):
x = np.array(range(1,1+len(pianzhis)))
plt.plot(x, pianzhis, label='bias', color = 'g')
plt.plot(x, fangchas, color = 'r', label='variance')
plt.xlabel('tree num')
plt.ylabel('value')
plt.legend(bbox_to_anchor=(1.3, 1), borderaxespad=0, loc='upper right')
plt.show()
def fit():
rf = RandomForestRegressor(max_features=0.92,
random_state=1,
criterion='mae',
oob_score=True,
warm_start=True,
min_samples_split=mmin_samples_split,
min_samples_leaf=mmin_samples_leaf,
n_estimators=tree_num,
verbose=2)
rf.fit(train_data[train_data.columns[:-1]], train_data['MEDV'])
total_predict = rf.predict(test_data[test_data.columns[:-1]])
true_label = list(valid_data['MEDV'])
predict_labels = [rf.estimators_[i].predict(valid_data[valid_data.columns[:-1]]) for i in range(tree_num)]
print('total mse', mean_squared_error(test_data['MEDV'], total_predict))
print('test_rate-------------------', test_rate)
print('min_samples_split-------------------', mmin_samples_split)
print('min_samples_leaf-------------------', mmin_samples_leaf)
print('tree_num-------------------', tree_num)
return show_multi_curve(true_label, predict_labels)
fit()
building tree 1 of 3
building tree 2 of 3
building tree 3 of 3
total mse 36.12915935672515
test_rate------------------- 0.3
min_samples_split------------------- 200
min_samples_leaf------------------- 5
tree_num------------------- 3
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 0.0s finished
/home/wangjn/anaconda3/envs/torch/lib/python3.7/site-packages/sklearn/ensemble/_forest.py:832: UserWarning: Some inputs do not have OOB scores. This probably means too few trees were used to compute any reliable oob estimates.
warn("Some inputs do not have OOB scores. "
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 0.0s finished

(26.358311111111107, 9.882888888888887)
pianzhis = []
fangchas = []
for m in range(1, 401):
tree_num = m
pianzhi, fangcha = fit()
pianzhis.append(pianzhi)
fangchas.append(fangcha)
print(pianzhis, fangchas)
show_2curve(pianzhis, fangchas)
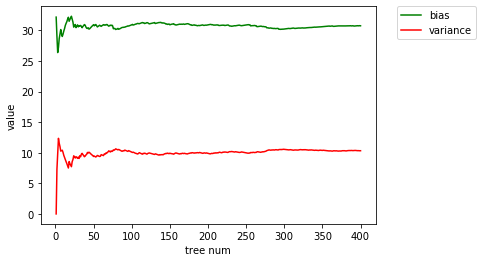
结论与分析
方差用来度量模型决策的不一致性,也就是训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响,方差较大的模型往往相对问题过于复杂,容易造成过拟合问题;偏置则衡量了模型是否适合目标问题也就是是否存在欠拟合现象,即学习算法的期望预测与真实结果的偏离较大或者说学习算法本身的拟合能力不足,比如用一个线性模型去建模非线性问题,由于拟合能力不足,就会得到偏置项很大的结果。在实际选择模型时,需要根据问题和任务,权衡方差和偏置,争取能使得最终总的误损最小。一般来说,偏置与方差是有冲突的,偏置越小,方差就可能越大,这是因为在训练不足时,模型的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏置主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率。
由此可见,在实际中,为了缩小预测的误损,可以从方差和偏置两个方面着手进行改进。(1)在选择模型方面,简单的模型会有一个较大的偏置和较小的方差,复杂的模型则偏置较小方差较大,可以根据自己的需求选择复杂度合适的模型,同时尽可能增加数据集的大小;(2)除此之外,还可以通过对多个模型进行集成来缩小模型的偏置和方差,Bagging算法是采用Bootstrap方法从原始数据集生成一系列新的数据集,然后在每个数据集上分别训练一个预测模型,最后取所有模型预测结果的均值,事实上,把模型的误差分解成偏置分量和方差分量后,取平均可以将误差中来自方差项的贡献抵消掉,集成了多个决策树的随机森林算法也有这种效果,而Boosting则是一种迭代算法,它可以从多个效果仅比随机猜测稍好的基分类器(弱学习器)出发得到较好的结果,其基本原理是被一个基分类器误分类的点在训练序列中的下一个基分类器时将会被赋予更高的权重,而一旦所有基分类器都训练完毕,它们的预测就会通过加权投票进行组合,由于每一次迭代都根据上一次迭代的预测结果对样本进行权重调整,所以随着迭代不断进行,误差会越来越小,所以模型的偏置会不断降低。(3)还可以使用K折交叉验证调整模型预测的偏置和方差,设K表示总共分为几折,当K较大时,每次划分的训练集就越大,估计模型的期望就越接近整个数据集的真实模型值,因此模型偏置就越小。
为了检验上述理论的正确性,我还以随机森林为模型做了下述实验。实验采用的数据集是波士顿房价数据集,该数据集针对回归问题。每个类的观察值数量是均等的,共有 506 个样本,13 个特征和1个目标值,每条数据包含房屋以及房屋周围的详细信息,具体有城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等。
实验中我采用了随机森林来进行回归分析,在保持其他条件不变的情况下,我将随机森林中包含的决策树的数目从1一直增加到400,将每个决策树视为一个单独的模型,并计算每一种参数下的偏置和方差。在树的增长过程中,偏置是先减后增,方差是先增后减,在偏置减而方差增的阶段,模型处于欠拟合,在偏置增而方差减的阶段,模型处于过拟合。