在阅读前,建议看:t检验、t分布、t值
先深入理解 t t t检验、 t t t分布、 t t t统计量的数学意义
在编程的时候,不少语言或者编程包只有现成的双侧T检验的函数,我想知道怎么根据双侧T检验的 p p p 值来得到单侧T检验的 p p p 值。或者更广一点来说,单侧T检验 p p p 值与双侧T检验的 p p p 值是什么关系?
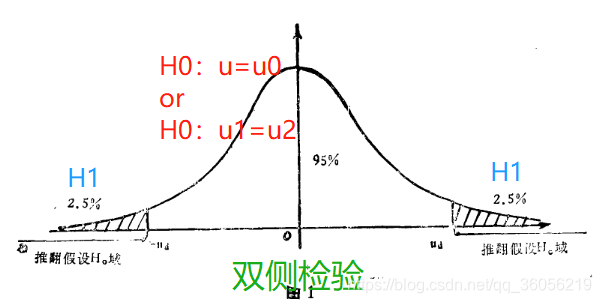
双侧T检验
零假设 H 0 : μ = 0 H0:μ=0 H0:μ=0,对立假设 H 1 : μ ≠ 0 H1:μ≠0 H1:μ=0。
简单理解:
我们假设了 H 0 : μ = 0 H0:μ=0 H0:μ=0,并要去检验此假设下H0成立的概率高不高。
因为是双侧,如下图所示,只要算出来的 t t t统计量- t s c o r e tscore tscore在95%的区域中,都是能够证明H0成立的。
P − v a l u e P-value P−value
-
在原假设为真时,检验统计量的观察值>=其计算值的概率:
双侧检验为分布中两侧的面积之和 -
P P P越小,拒绝 H 0 H0 H0 的理由越充分。 P P P可看作 H 0 H0 H0是正确的概率,或拒绝了 H 0 H0 H0会犯错的概率,所以 P P P越小说明,犯错的风险越小。
-
对某一给定的样本, P P P越小,说明犯第一类错误(弃真)的概率越小,如果 P < = α ( 可 接 受 的 最 大 第 一 类 错 误 风 险 ) P<=α(可接受的最大第一类错误风险) P<=α(可接受的最大第一类错误风险),则拒绝原假设 H 0 H0 H0;相反如果 P > α P>α P>α,则认为第一类错误(弃真)的风险太大,于是接受原假设 H 0 H0 H0。
-
决策规则: P < α P<α P<α,拒绝 H 0 H0 H0


单侧T检验
零假设 H 0 : μ < = 0 H0:μ<=0 H0:μ<=0,对立假设 H 1 : μ > 0 H1:μ>0 H1:μ>0。

简单理解:
我们假设了 H 0 : μ < = 0 H0:μ<=0 H0:μ<=0,并要去检验此假设下H0成立的概率高不高。
因为是右侧检验(拒绝域在右边),如下图所示,只要算出来的 t t t统计量- t s c o r e tscore tscore在95%的区域中,都是能够证明H0成立的。
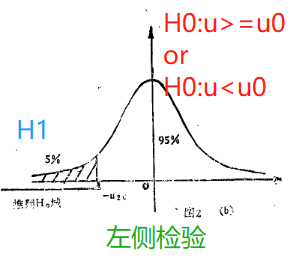
零假设 H 0 : μ > = 0 H0:μ>=0 H0:μ>=0,对立假设 H 1 : μ < 0 H1:μ<0 H1:μ<0。
简单理解:
我们假设了 H 0 : μ > = 0 H0:μ>=0 H0:μ>=0,并要去检验此假设下H0成立的概率高不高。
因为是左侧检验(拒绝域在左边),如下图所示,只要算出来的 t t t统计量- t s c o r e tscore tscore在95%的区域中,都是能够证明H0成立的。

单尾、双尾T检验的p值关系
双 侧 检 验 的 p 值 = 双 侧 分 布 中 两 端 面 积 的 总 和 双侧检验的p值=双侧分布中两端面积的总和 双侧检验的p值=双侧分布中两端面积的总和
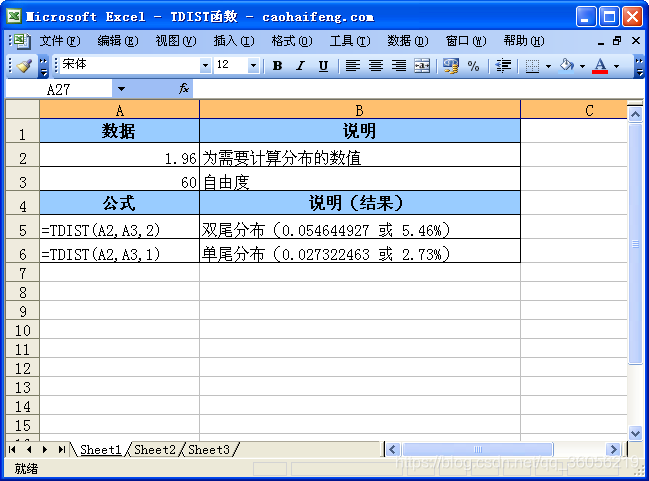
Excel-TDIST函数
在Excel中使用TDIST函数 计算 p 值 p值 p值:
T D I S T ( x , d e g r e e s f r e e d o m , t a i l s ) TDIST(x,degrees_freedom,tails) TDIST(x,degreesfreedom,tails)
X:为需要计算分布的数字。Degrees_freedom:为表示自由度的整数。Tails:指明返回的分布函数是单尾分布还是双尾分布。如果tails= 1,函数 TDIST 返回单尾分布。如果tails= 2,函数 TDIST 返回双尾分布。
TDIST函数适用于:Excel2003、Excel2007、Excel2010、Excel2013、Excel2016。
- 如果任一参数为非数值型,函数 TDIST 返回错误值 #VALUE!。
- 如果
degrees_freedom< 1,函数 TDIST 返回错误值 #NUM!。 - 参数
degrees_freedom和tails将被截尾取整。 - 如果
tails不为 1 或 2,函数 TDIST 返回错误值 #NUM!。 - 如果 x < 0,TDIST 返回错误值 #NUM!。 当 x < 0 时要使用 TDIST:
T D I S T ( − x , d f , 1 ) = 1 – T D I S T ( x , d f , 1 ) = P ( X > − x ) TDIST(-x,df,1) = 1 – TDIST(x,df,1) = P(X > -x) TDIST(−x,df,1)=1–TDIST(x,df,1)=P(X>−x)
T D I S T ( − x , d f , 2 ) = T D I S T ( x , d f , 2 ) = P ( ∣ X ∣ > x ) TDIST(-x,df,2) = TDIST(x,df,2) = P(|X| > x) TDIST(−x,df,2)=TDIST(x,df,2)=P(∣X∣>x)。 - 如果 tails = 1, T D I S T = P ( X > x ) TDIST = P( X>x ) TDIST=P(X>x),其中 X 为服从 t 分布的随机变量。
- 如果 tails = 2, T D I S T = P ( ∣ X ∣ > x ) = P ( X > x o r X < − x ) TDIST = P(|X| > x) = P(X > x\ or\ X < -x) TDIST=P(∣X∣>x)=P(X>x or X<−x)。
上述第5-7点对于x<0时的p值讨论,针对左侧检验和右侧检验都是一样的,同样适用!
TDIST函数 计算可知:
- p 双 侧 = T D I S T ( x , d f , 2 ) = T D I S T ( − x , d f , 2 ) = P ( ∣ X ∣ > x ) = P ( X > x o r X < − x ) p双侧=TDIST(x,df,2)=TDIST(-x,df,2)= P(|X| > x) = P(X > x \ or\ X < -x) p双侧=TDIST(x,df,2)=TDIST(−x,df,2)=P(∣X∣>x)=P(X>x or X<−x)
- 当 t t t统计量>0时, p 单 侧 = p 双 侧 / 2 = P ( X > x ) p单侧=p双侧/2=P(X >x) p单侧=p双侧/2=P(X>x)
- 当 t t t统计量<0时, p 单 侧 = 1 − p 双 侧 / 2 = P ( X > − x ) p单侧=1-p双侧/2=P(X > -x) p单侧=1−p双侧/2=P(X>−x)
Python-ttest等函数
H 0 : μ = μ 0 , H 1 : μ ≠ μ 0 H0:μ=μ0,H1:μ≠μ0 H0:μ=μ0,H1:μ=μ0
T检验涉及的函数:ttest_1samp进行双侧检验
# 导入包
from scipy import stats
import numpy as np
# 1.单一样本T检验-ttest_1samp
# step1:生成数据,生成50行×2列的数据
np.random.seed(120) # seed 保证每次运行得到的结果是一样的
rvs=stats.norm.rvs(loc=41000,scale=5000,size=20) # 均值为5,方差为10,50行×2列的数据
# step2:检验两列数的均值差异是否显著
stats.ttest_1samp(rvs,40000)
返回结果 :Ttest_1sampResult(statistic=2.481538955443869, pvalue=0.02260211710111142)
此处的 t t t 统计量statistic=2.481538955443869, p 双 侧 p双侧 p双侧pvalue=0.02260211710111142
t t t 统计量在双尾和单尾检测中的区别:
- t t t 统计量不管是双尾检验还是单尾检验,算出来的 t t t 值都是一样的,唯一的区别在于双尾中的是 ∣ t ∣ |t| ∣t∣ ,而单尾中的 t t t 是包含+、-符号的。
- 另一区别在于,查 t t t 分布表得出的临界值是不一样的。
双尾查的是 t − α / 2 ( d f ) t-α/2(df) t−α/2(df) ,对比的是 p 双 侧 p双侧 p双侧 和 t − α / 2 ( d f ) t-α/2(df) t−α/2(df) ;
单尾查的是 t − α ( d f ) t-α(df) t−α(df),对比的是 p 单 侧 p单侧 p单侧 和 t − α ( d f ) t-α(df) t−α(df)
1)当 t t t统计量>0时, p 单 侧 = p 双 侧 / 2 = P ( X > x ) p单侧=p双侧/2=P(X >x) p单侧=p双侧/2=P(X>x)
2)当 t t t统计量<0时, p 单 侧 = 1 − p 双 侧 / 2 = P ( X > − x ) p单侧=1-p双侧/2=P(X > -x) p单侧=1−p双侧/2=P(X>−x)
更多应用:【DA】常见的假设检验
总结
单侧检验和双侧检验是等价的。没有谁更严格之说。
选择单尾和双尾检验时,就先根据实际问题确定正确的H0和H1,这样验证的思路也会更清晰。
实际上,同一个单尾检验问题,根据关注点的不同(提问方向的不同),既可以用左侧检验,也可以用右侧检验。两种检验得到的 t t t 统计量的值是一样的,区别在于拒绝域在哪一侧。