号外号外,经过一个多月的艰苦奋斗,终于完成了,图形展示红黑树和具体的步骤的网页。希望网友可以一起讨论,可能是全网唯一个每个步骤都图解出来的动态网页
图形解析-步骤解析红黑树
HashMap源码解析-不定时更新中...
虽尽全力认真学习解读,但是难免还是会有疏漏,请各位大佬莅临指导,指出错误,必定认真修改。及时更新,感谢感谢!!
内容结构整理,请放大或下载查看

1、属性解析
1.1 hash初始长度
- 最主要还是Hash表的内容,默认初始长度为16,扩容需为2的幂,也就是左移一位
/**
* The default initial capacity - MUST be a power of two.
* 这是默认的容量,必须为2的倍数,目前默认为 2^4 = 16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
1.2 负载扩容的因子
- 为啥默认的扩展因子为0.75,说法众说纷纭
- 其中一个如果为0.5,会导致hash表的内容过大,如果为1的话,会导致重复的hash较多,达不到快速读取的效果
- 我个人的看法,16*0.75 = 12 , 16(左移)扩容一倍为32,12左移一位为24
12 二进制 0000 1100 = 8+4 = 12 右移一位 为0001 1000 = 16+8 = 24
实际计算,最佳的扩展因子等于0.6931 1 ,根据上述情况,0.75很方便计算。
/**
* The load factor used when none specified in constructor.
* 默认读取的负载 = 0.75,容量充满75%以及以上是,进行扩容,扩容一倍
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The load factor for the hash table.
* hash表的加载扩充系数
*/
final float loadFactor;
1.3 单链表和二叉树转换
- java8,hash地址碰撞之后,使用的链地址法。
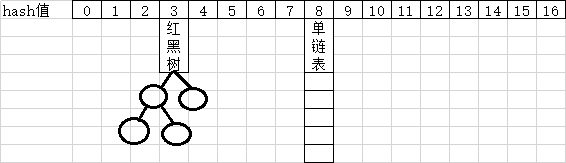
把具体的节点内容详细的展示出来,如图所示

转换的过程,当单链表的长度大于等8时,会转换为红黑树进行存储(ps:实际代码跟踪下来,其实双链表和红黑树共存),当具体的值小于6时,又会拆成单链表。
/**
* jdk1.8中,hash冲突时,数据内容放在链表中,当链表的长度超过8时,则转化为红黑树
* 链表和红黑树的转换阈值,最小应该为2,至少应该等于8
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 修改红黑树为链表的阈值,
*/
static final int UNTREEIFY_THRESHOLD = 6;
1.4 容量最大值和阈值最大值
- 容量默认最大值
/**
* 最大的容量,小于等于2^30
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
- 最大的阈值
/**
* The next size value at which to resize (capacity * load factor).
* 下一次扩容的阈值 (当前容量 * 扩充系数loadFactor)
*/
int threshold;
......
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
1.5 计算hash值,如何映射
- 计算hash值
/**
* 大致的意思,计划hash内容变得比之前简化,高16位和低16位进行异或操作获取hash值,
* 对于容易出现冲突的一点,使用链表和红黑树进行处理
* >> 带符号右移 >>> 无符号右移,高位全部补0
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
......
static class Node<K,V> implements Map.Entry<K,V> {
......
// 获取当前的hash的值
public final int hashCode() {
// key值得hashCode 异或(相同为0不同为1) 值的hashCode
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
......
}
- 如何进行映射
- tab指 hashTable的列表
- n只当前容量大小
tab[(n - 1) & hash]
1.6 hash扩容
具体代码提示,在下文中展示
- 针对原始的链表内容
- 待完成
- 针对链表和红黑树
- 链表:根据新的容量 (n)&hashCode>0,扩容的部分,hash有无高位,无高位归原始hash值链表,有高位归属新的hash值链表
- 红黑树: 根据新的容量 (n)&hashCode>0,扩容的部分,hash有无高位,之后判断是否达到维持红黑树的最小长度,再判断无高位归属原始hash,是转换为链表还是保持红黑树。高位的更新hash其余一致。
1.7 支持不支持null值
null的hash值是0,默认在hash表的第一个
2、实现的接口&继承类的解析
2.1 实现接口 Map<K, V>
java.util.Map<K, V>
size() Map的大小
isEmpty() 是否为空
containsKey(Object) 是否存在当前值
containsValue(Object) 是否存在当前的Key
get(Object) 按照key获取一个值
put(K, V) 插入一个键值对
remove(Object) 按照Ksy移除一个键值对
putAll(Map<? extends K, ? extends V>) 插入一个map内容
clear() 移除所有键值对
keySet() 返回Key的Set列表
values() 返回Value的Collection列表
entrySet() 返回键值对的Set<Entry<K,V>>列表
Entry<K, V> Entry的接口
getKey() 获取key
getValue() 获取值
setValue(V) 设置值
equals(Object) 比较
hashCode() 获取hash值
comparingByKey()比较方法
comparingByValue()
comparingByKey(Comparator<? super K>)
comparingByValue(Comparator<? super V>)
equals(Object)比较
hashCode() 获取hash值
getOrDefault(Object, V) 根据key获取值,如果值不存在,则返回参数中的V
forEach(BiConsumer<? super K, ? super V>)遍历查询
replaceAll(BiFunction<? super K, ? super V, ? extends V>)替换所有内容
putIfAbsent(K, V)如果不存在则插入
remove(Object, Object)按照key和value都匹配的方式删除一个
replace(K, V, V)更改内容,按照key-value两个都匹配的情况更新新value
replace(K, V)更新内容,按照key值去更新value
// jdk8新增的匿名函数
computeIfAbsent(K, Function<? super K, ? extends V>)
computeIfPresent(K, BiFunction<? super K, ? super V, ? extends V>)
compute(K, BiFunction<? super K, ? super V, ? extends V>)
// 合并
merge(K, V, BiFunction<? super V, ? super V, ? extends V>)
2.2 继承接口 AbstractMap<K, V>
java.util.AbstractMap<K, V>
AbstractMap() 构造方法
size() Map的大小
isEmpty() 是否为空
containsValue(Object) 是否存在当前值
containsKey(Object) 是否存在当前的Key
get(Object) 按照key获取一个值
put(K, V) 插入一个键值对
remove(Object) 按照Ksy移除一个键值对
putAll(Map<? extends K, ? extends V>) 插入一个map内容
clear() 移除所有键值对
keySet 属性:Key的Set列表
values 属性:Value的Collection列表
keySet() 返回Key的Set列表
values() 返回Value的Collection列表
entrySet() 返回键值对的Set<Entry<K,V>>列表
equals(Object) 比较两者是否一致,默认对比引用,覆写后可定制
hashCode() 获取hash值
toString() 转换为string字符串
clone() 深复制克隆
eq(Object, Object) 私有,对比两者是否一致
SimpleEntry<K, V> 简单的键值对对象
serialVersionUID 序列化id
key 主键
value 值
SimpleEntry(K, V) 键值构造方法
SimpleEntry(Entry<? extends K, ? extends V>) 键值对象构造方法
getKey() 获取key
getValue() 获取值
setValue(V) 设置值
equals(Object) 比较
hashCode() 获取hash值
toString() 转换为string字符串
SimpleImmutableEntry<K, V> 简单的不能改变的键值对对象
serialVersionUID 序列化id
key 主键
value 值
SimpleImmutableEntry(K, V) 键值构造方法
SimpleImmutableEntry(Entry<? extends K, ? extends V>) 键值对象构造方法
getKey() 获取key
getValue() 获取值
setValue(V) 设置值
equals(Object) 比较
hashCode() 获取hash值
toString() 转换为string字符串
2.3 Cloneable接口
实现类java.long.Cloneable
复写的是Object的方法。
/**
* Returns a shallow copy of this <tt>HashMap</tt> instance: the keys and
* values themselves are not cloned.
* 键值并没有克隆
* @return a shallow copy of this map
*/
// 去除警告提示
@SuppressWarnings("unchecked")
// 重写自Object类
@Override
public Object clone() {
HashMap<K,V> result;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
// 重新初始化
result.reinitialize();
// 插入原来的元素
result.putMapEntries(this, false);
return result;
}
2.4 Serializable序列号接口
实现类import java.io.Serializable;
常规操作,实现接口,并定义序列化标识即可。
private static final long serialVersionUID = 362498820763181265L;
2.5 迭代器实现– 待完成
3、代码分段解析
3.1 存储节点解析
- hash表的结构和链表的结构
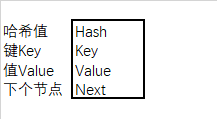
节点的数据结构组成
/**
* hash表的内容,扩容必须为2的幂
*/
transient Node<K,V>[] table;
......
// 初始化table列表
@SuppressWarnings({
"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
......
/**
* 基本的节点
*/
static class Node<K,V> implements Map.Entry<K,V> {
// hash值是不能改变的,否则下一次就找不到这个值了
final int hash;
// 储存的键,键也不能更改,一般建议为Int或者String
final K key;
// 储存的对象
V value;
// 链表的下一个指针
Node<K,V> next;
......
}
3.2 红黑树节点解析
1.红黑树节点展示

/**
* 定义树形节点
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
// 父亲节点
TreeNode<K,V> parent; // red-black tree links
// 左子树
TreeNode<K,V> left;
// 右子树
TreeNode<K,V> right;
// 树形结构中的上一个节点
TreeNode<K,V> prev; // needed to unlink next upon deletion
// 是否是红节点标志
boolean red;
......
}
继承关系,实际链表和树形结构代码中,未使用到LinkedHashMap中间的属性。
Node<K, V> extends Object implements Map.Entry<K, V>
LinkedHashMap.Entry<K, V> extends HashMap.Node<K, V>
class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>
3.2 传输初始化长度转换为2的幂 --待完成
4、算法解析
4.1 链表结构
a.链表生成&插入&链表树转换契机
- 判断条件,什么时候开始生成链表
- 待插入的hash节点不为空
- 插入的key与hash节点的key不相等,证实了hash冲突
- 什么时候插入
- 待插入的hash节点为空
- 待插入的hash节点不为空,但是key相等,覆盖值
- 待插入的hash节点为红黑树,插入红黑树
- 待插入的hash节点为链表,遍历至最后一个
- 如果长度不大于8完成
- 如果长度大于8则转换为红黑树
- 针对值,onlyIfAbsent 为false,直接覆盖value
- onlyIfAbsent 为true,只有原来值为空才覆盖
/**
* 实现map的插入动作和 关联的方法
* Implements Map.put and related methods.
* @param hash hash for key
* @param key the key
* @param value the value to put
* (参数的意译名称onlyIfAbsent ) 如果不存在,标记为真,不能改变值
* @param onlyIfAbsent if true, don't change existing value
* 如果evict 为false 当前的table处于创建模式
* @param evict if false, the table is in creation mode.
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 当前table为空,则进行扩展。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 当前节点的hash值,为空,赋值进当前节点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// 当前的hash节点不为空
Node<K,V> e; K k;
// 当前节点的hash不为空,并且key还相等,则覆盖当前值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 当前节点的hash是树形节点,则插入新值进入树形节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 计算即将插入的新值的的链表长度
for (int binCount = 0; ; ++binCount) {
// 下一个节点为空,插入新值
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果统计的链表的长度大于等于转换阈值,则转换为树形结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 下一个值不为空,则接着循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
/*
e有三个来源
1、覆盖节点,array上的节点
2、树形结构的节点,增加后返回的节点
3、链表节点的最后一个节点
新增的节点如果不为空
*/
if (e != null) {
// existing mapping for key
V oldValue = e.value;
// 如果 缺少标记不为真 或者当前的值为空,重新进行赋值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// linkedHashMap的回调
afterNodeAccess(e);
return oldValue;
}
}
// 内容的修改+1
++modCount;
// 大小尺寸+1,判断是不是要扩展
if (++size > threshold)
resize();
// 目前为空方法
afterNodeInsertion(evict);
return null;
}
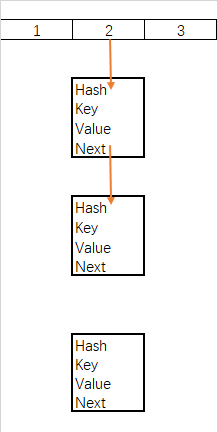
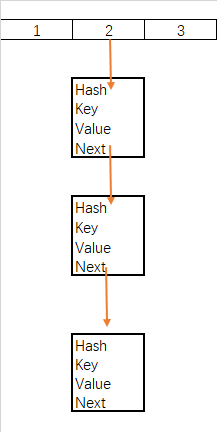
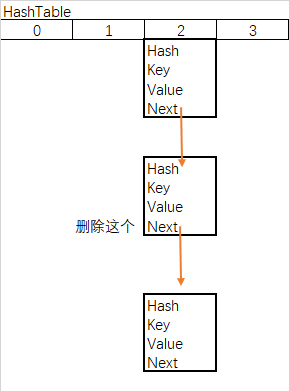
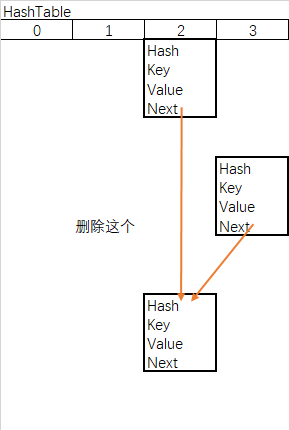
b.链表删除
- matchValue 变量,为真则必须匹配value的值,全都相等才会删除
- movable变量,为false则移除时不会移动其他节点
- 当前节点为根节点,根节点下个顺延
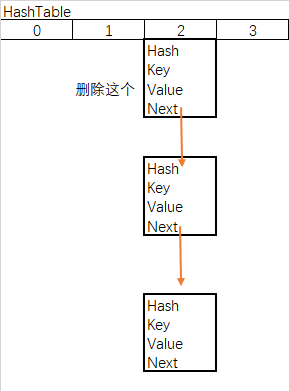
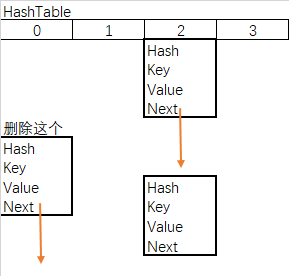
- 当前节点不为根节点,上节点的next指向移除的下节点
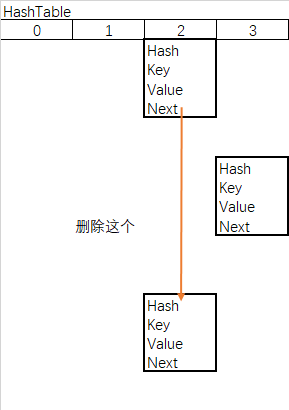
/**
* Implements Map.remove and related methods.
* 如果matchValue为真,只有值相等的时候才会被移除
* @param matchValue if true only remove if value is equal
* movable 如果为false则移除时不会移动其他节点
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
* 移除节点
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// hash表不为空,长度大于0,获取到hash位置处的节点也不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 当hash值相等,key相等,获取到指定节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
// 如果不相等,有没有下一个节点
else if ((e = p.next) != null) {
// 是不是红黑树
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
// 是链表
do {
// 当hash值相等,key相等,获取到指定节点
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// 如果获取到节点,如果匹配值的标记为真,则还需匹配值是否相等
// 相等指引用或者内容是否相等
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 树形节点,清除树节点
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
/*
* node 等于 p 只有在p是根节点的时候
* 所以node = p 等于根节点
*/
else if (node == p)
tab[index] = node.next;
else
/*
* node 不等于 p 只有在树和链表
* 树已经单独做了处理,所以此时的p自始至终是node的上一个节点
*/
p.next = node.next;
++modCount;
--size;
// LinkedHashMap回调
afterNodeRemoval(node);
return node;
}
}
return null;
}
c.链表的查询
- 查询其实不用赘述,获取hash表节点,下一个下一个就可以了
// 已经匹配过hash值了
do {
// 当hash值相等,key相等,获取到指定节点
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
// 对比key之后获取到的对象
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
d.Hash扩容链表的操作
- 扩容什么时候触发
- putMapEntries():使用其他map进行初始化的时候,而且其他map容量大于当前的扩展阈值
- 插入值得时候
- 调整链表为树形结构的时候
- computeIfAbsent() – 待完成
- compute() – 待完成
- merge() – 待完成
- 扩容扩容多少
当前的两倍,容量左移一位,阈值也是左移一位,当阈值大于最大容量是,阈值调整为Int值得最大值。 - 扩容后链表是如何操作的
- 举例

假如有计算后hash分别为0001 1100,0011 1100,0101 1100,0000 1100四个hash值
扩容前:容量为16 阈值为12
- 举例
| 原始二进制 | 0001 1100 | 0011 1100 | 0101 1100 | 0000 1111 |
| 使用长度为16的hash命中函数进行计算,(n-1=15 = 0000 1111) 公式: (n-1)&hash | ||||
| 扩容前 | 0000 1100 | 0000 1100 | 0000 1100 | 0000 1100 |
| 原始二进制 | 0001 1100 | 0011 1100 | 0101 1100 | 0000 1111 |
| 使用旧容量的值进行&运算看是不是等于0,16 即 &0001 0000 | ||||
| &计算之后 | 0001 0000 | 0001 0000 | 0001 0000 | 0000 0000 |
| 计算结果 | >0 | >0 | >0 | =0 |
| 扩展后进行hash命中,即32-1 即 hash&0001 1111 | ||||
| 扩展后 | 0001 1100 | 0001 1100 | 0001 1100 | 0000 1100 |
| 现在的hash位置 | 28 | 28 | 28 | 12 |

/**
* 重新规划尺寸
* @return the table
*/
final Node<K,V>[] resize() {
// 获取当前table
Node<K,V>[] oldTab = table;
// 获取旧table的大小
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 获取旧的重新规划阈值
int oldThr = threshold;
int newCap, newThr = 0;
// 如果旧的table(oldCap)大小大于0
if (oldCap > 0) {
// oldCap 大于数值上限,就等于int的最大值
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// oldCap左移一位赋值给newCap,newCap小于最大值,并且oldCap大于等于最小值
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 新的临时阈值 为旧的阈值左移一位
// 如果初始值为16 阈值为12 二进制为1100
// 新的大小为32 阈值为24 1100 左移一位为 1 1000 正好是24
newThr = oldThr << 1; // double threshold 两倍的阈值
}
// 初始容量赋值给阈值,
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// zero initial threshold signifies using defaults
// 如果是零位初始值,则进行初始化
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果阈值等于0
if (newThr == 0) {
// 新的容量 * 负载系数
float ft = (float)newCap * loadFactor;
// 新容量小于最大容量并且新的阈值小于最大容量 是否成立,成立则设置新阈值,都超了,阈值为int的最大值
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 设置新阈值
threshold = newThr;
@SuppressWarnings({
"rawtypes","unchecked"})
// 获取新的列表数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 老的数据不为空的话执行遍历
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 遍历的当前节点不为空
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 查看当前节点下有无节点,如果没有更新hash值并赋值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 如果当前节点是树形节点,应该也是对树形节点的一个更新
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// preserve order
// 如果是链表
// 低位的hash链表
Node<K,V> loHead = null, loTail = null;
// 高位的hash链表
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
// 获取下一个节点
next = e.next;
// 如果当前的hash&旧的长度内容为0的话,证明无需替换
if ((e.hash & oldCap) == 0) {
// 赋值尾节点和头节点
// 如果尾结点为空,证明没有链表,否则增加至下一个
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
// 证明hash需要更换
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 低位链表尾结点不为空,赋值尾结点下一个节点为空
if (loTail != null) {
loTail.next = null;
// 低位hash,还是存在在当前的链表中
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 高位hash重新赋值
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
4.2 红黑树结构
a.红黑树的规则
R-B Tree,全称是Red-Black Tree,又称为“红黑树”,它一种特殊的二叉查找树。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。2
红黑树的特性:2
(1)每个节点或者是黑色,或者是红色。2
(2)根节点是黑色。2
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]2
(4)如果一个节点是红色的,则它的子节点必须是黑色的。2
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。2
注意:
(01) 特性(3)中的叶子节点,是只为空(NIL或null)的节点。2
(02) 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。2
b.红黑树左旋
- 文字描述:
- 当前节点左旋
- 当前节点成为当前节点右节点的左节点
- 当前节点右节点的左节点成为当前节点的右节点




重新理顺:

java代码源码
// Red-black tree methods, all adapted from CLR
// 左旋
/**
当前节点左旋,
当前节点成为右子树的左节点,
右子树的左节点成为当前节点的右节点
*/
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root, TreeNode<K,V> p) {
// r 当前节点的右节点 右 pp 当前节点的父节点,父 rl当前节点的右节点的左节点,右子左
TreeNode<K,V> r, pp, rl;
if (p != null && (r = p.right) != null) {
// 右 = 右子左 右子树的左节点成为当前节点的右节点
if ((rl = p.right = r.left) != null)
rl.parent = p;//右子左的父亲为当前节点
if ((pp = r.parent = p.parent) == null) // 当前节点为root转换后右节点就是root
(root = r).red = false;
else if (pp.left == p) // 当前节点是父节点的那个节点,r就成为新的
pp.left = r;
else
pp.right = r;
r.left = p; // 当前节点成为原右节点的左节点
p.parent = r;
}
return root;
}
c.红黑树右旋
文字描述:
- 当前节点左子树右节点成为当前节点的左节点
- 当前节点成为左子树的右节点




java源码
// 右旋
/**
当前节点右旋
当前节点成为左节点的右节点,原来左节点的右节点成为当前节点的左节点
*/
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> l, pp, lr;
// p当前节点 l左子树 pp 父节点 左子的右节点
// 当前节点不为空 当前节点左子树不为空
if (p != null && (l = p.left) != null) {
// 当前节点的左节点,成为原左节点的右节点
if ((lr = p.left = l.right) != null)
// 原左节点右节点的父引用为当前节点
lr.parent = p;
// 原左子树父引用修改为当前的父引用
if ((pp = l.parent = p.parent) == null)
// 如果为根节点,颜色修改为黑色
(root = l).red = false;
// 当前节点在父类位置是什么旋转之后的原右节点就是什么位置
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
// 当前节点成为原左子树的右节点
l.right = p;
// 当前节点父引用修改为原左节点
p.parent = l;
}
return root;
}
d.红黑树生成
- 红黑树生成的时机
请参考4.1.a 链表生成&插入&链表树转换契机 - 链表转换为树形结构的实际过程
1、转换Node链表为TreeNode双链表
2、转换的双链表取代原来的tab[hash]位置
3、按照hash值大大小,插入红黑树。并进行平衡
对比当前节点,准备插入的值,左侧小于自己,右侧大于自己。逐级寻找后进行插入。
hash值相等,对比两个key的值,区分出一个大小。
4、树形结构的root移动至链表的顶部
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
* 调整长度过大的链表为树形结构
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 链表为空或者链表的长度小于维持树形结构最小的阈值
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// ?
resize();
// 获取到hash内容,值不为空
else if ((e = tab[index = (n - 1) & hash]) != null) {
// e 当前的hash位置的链表
// 树形结构
// tl上级节点
// hd为根节点
TreeNode<K,V> hd = null, tl = null;
do {
// 获取到树形节点
TreeNode<K,V> p = replacementTreeNode(e, null);
// 上级节点为空
if (tl == null)
// 给根节点
hd = p;
else {
// 当前节点的父引用为上级节点,父节点的下个节点为当前节点
p.prev = tl;
tl.next = p;
}
// 保存上级节点
tl = p;
} while ((e = e.next) != null);
/**
* 上述代码实现了变更Node节点链表为TreeNode节点双链表
*/
if ((tab[index] = hd) != null)
// 根节点转换
hd.treeify(tab);
}
}
/**
* Forms tree of the nodes linked from this node.
* 形成节点树,从当前Node节点开始
* 遍历所有节点
* root节点修改为黑色
* 获取key,计算hash插入应该插入的点,树节点都是左侧小于自己,右侧大于自己的hash
* 插入后进行红黑树平衡
* 最后结束后移动root节点到链表的第一个
*/
final void treeify(Node<K,V>[] tab) {
// 定义root节点
TreeNode<K,V> root = null;
// 进行遍历处理定义的x不等于空,当前节点为x
for (TreeNode<K,V> x = this, next; x != null; x = next) {
// 获取链表的下一个
next = (TreeNode<K,V>)x.next;
// 对当前节点树,左右子树置空
x.left = x.right = null;
if (root == null) {
// 如果root等空的话,进行初始化
x.parent = null;
x.red = false; // 定义为黑色
root = x; // 赋值当前内容为x
}
else {
// 已经存在root节点了
// 获取key
K k = x.key;
// 计算hash
int h = x.hash;
Class<?> kc = null;
// 开始循环遍历 寻找应该插入的节点
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
//通过hash进行大小对比,用来确定插入左边还有右边
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
// 当hash值相等的时候,使用key值进行对比并且分出大小
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
// dir<=0 给 p节点进行赋值,并且新赋值的节点为空的话
if ((p = (dir <= 0) ? p.left : p.right) == null) {
// 设置新增节点的父节点
x.parent = xp;
if (dir <= 0)
// 小于等于,放左边
xp.left = x;
else
// 大于放右边
xp.right = x;
// 应该是进行红黑树平衡操作,
root = balanceInsertion(root, x);
break;
}
}
}
}
// 移动根节点至最前面
moveRootToFront(tab, root);
}
- 插入时平衡请看下文插入节点
e.插入节点
- 节点插入
- 1、对于当前节点来说,左侧是小于自己的,右侧是大于自己的
- 2、插入的节点的hash,小于当前节点遍历左边,反之遍历右边,为空则插入。
- 3、hash值相等,key相等的不操作
- 4、hash值相等,key不相等的,使用key分出大小并进行插入。
- 如果两个key都实现对比接口comparable,则进行对比
- 如果没有对比接口使用tieBreakOrder,对比系统唯一级别的hash码
/**
/**
* Tree version of putVal.
* 插入tree的值
* 写入树形节点的值
*
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
// kc key的类
Class<?> kc = null;
boolean searched = false;// 寻找标记
// 获取根节点
TreeNode<K,V> root = (parent != null) ? root() : this;
// 开始进行遍历
for (TreeNode<K,V> p = root;;) {
// dir 比较的大小 ph putHash pk putKey
int dir, ph; K pk;
// 计算hash大小 使用dir进行标记
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
// 如果hash相等并且key相等,并且key是不等于空的。返回当前节点
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
// 现在hash相等,key不相等,两种情况,要么key是null,要么key类型不相等
else if ((kc == null &&
// 获取key对象有没有实现对比接口 有的话不为空
(kc = comparableClassFor(k)) == null) ||
// 对比两个key值的大小,如果pk值为空,Pk值未实现对比函数
(dir = compareComparables(kc, k, pk)) == 0) {
// 针对这种hash相等,key类型不一致的情况,只寻找一次
if (!searched) {
// 寻找标记为假,则进行
TreeNode<K,V> q, ch;
searched = true;// 设置寻找标记为真
// 查询并返回找到的key的内容
// 找到对象,说明对象存在,则直接返回
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
// hash值相等,key不相等,对比key的类型一致的话,对比其系统级别的唯一hash码大小
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
// 保留xp作为当前节点,根据dir的大小选择左右子树,并且为空的时候,插入
if ((p = (dir <= 0) ? p.left : p.right) == null) {
// xpn获取链表的下一个节点
Node<K,V> xpn = xp.next;
// 定义新的树节点
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
// 根据dir 判断,增加至左右子树
if (dir <= 0)
xp.left = x;
else
xp.right = x;
// xp的下个节点为x
xp.next = x;
// x的父节点,上个节点都等于xp
x.parent = x.prev = xp;
// 下个节点不为空的话,(链表)下个节点的上个节点指向x
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
// 平衡并且移动root至顶端
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
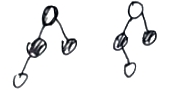
- 红黑树新增时平衡调整
- 新增的节点首先设置为红色
- 如果当前节点是root设置当前节点为黑色
- 左右指左旋右旋
// 新增时平衡树形节点
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
// x为新增节点,root为根节点
x.red = true;// 新增节点为红色
// xp x的父 xpp x父的父 xppl xpp的左 xppr xpp的右
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
// x父节点为空的话,x设为黑色,结束
if ((xp = x.parent) == null) {
x.red = false;
return x;

}
// 父节点为黑色 ,父父节点为空,返回即可
else if (!xp.red || (xpp = xp.parent) == null)

- 默认之前的结构是合适的。不存在父亲节点为红色,父父节点为空的情况
return root;
// 父节点为父父左
if (xp == (xppl = xpp.left)) {
// 父父右不为空并且为红色
if ((xppr = xpp.right) != null && xppr.red) {
// 父父右改为黑色
xppr.red = false;
// 父改外黑色
xp.red = false;
// 父父改为红色
xpp.red = true;
x = xpp; // 新增节点等于父父节点
}
else {
// 父父右为空,或者父父右为红色,新增节点是不是父右节点
if (x == xp.right) {
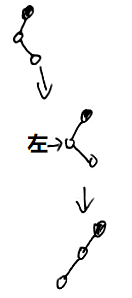
// 是的话左旋
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
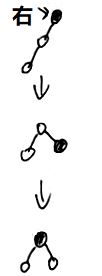
// 不是的话右旋
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
// 父节点为父父右
else {
if (xppl != null && xppl.red) {
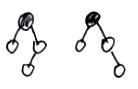
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {

root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
- 整体插入内容图解

f.删除节点
- 删除部分代码思路
- 首先判断是否有必要维持红黑树,无必要转换为单链表
- 双链表节点首先删除当前节点
- 判断判断当前节点有无左右子树
- 无左或者无右,则直接删除并替换
- 左右都有,则获取右子树最深最左侧的子节点,与自己替换。
- 再次判断有无右节点,无直接删除,有的话顶上即可。
图中,P为待删除的节点,S为右子树/或者右子树最深处的左子树,然后PS互换。包括颜色。

- 再次判断有无右节点,无直接删除,有的话顶上即可。
/**
* Removes the given node, that must be present before this call.
* This is messier than typical red-black deletion code because we
* cannot swap the contents of an interior node with a leaf
* successor that is pinned by "next" pointers that are accessible
* independently during traversal. So instead we swap the tree
* linkages. If the current tree appears to have too few nodes,
* the bin is converted back to a plain bin. (The test triggers
* somewhere between 2 and 6 nodes, depending on tree structure).
* 移除树形节点 操作比典型的红黑树操作更加混乱,数据量较少时我们会移除树形结构
*/
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {
int n;
// 如果树形节点为空,返回
if (tab == null || (n = tab.length) == 0)
return;
// 获取需要删除的内容的index
int index = (n - 1) & hash;
// 获取索引的节点,并且赋值给根节点
TreeNode<K,V> first = (TreeNode<K,V>)tab[index], root = first, rl;
TreeNode<K,V> succ = (TreeNode<K,V>)next, pred = prev;
// 如果上一个节点为空
if (pred == null)
// 对于链表来说,上一个为空,直接删除并顺延值下一个即可
// 获取下一个节点 赋值给first 并且赋值给tab[index]内容
tab[index] = first = succ;
else
// 链表,移除当前节点,上一个的下一个指针指向自己的下一个
pred.next = succ;
if (succ != null)
// 当下一个值的上一个对象不为空,则下节点的上指针赋值
succ.prev = pred;
// 然后开始对树形结构进行操作
if (first == null)
return;
// 如果根节点的父引用不为空,则根节点更新为原来的父引用对象
if (root.parent != null)
root = root.root();
// 如果根节点为空,或者
if (root == null
|| (movable // 删除的条件
&& (root.right == null // 根节点的右子为空
|| (rl = root.left) == null // 或者根节点的左子为空
|| rl.left == null))) {
// 或者根节点的左子节点的左子节点为空
// 根节点为空||(删除条件&&(根节点右子为空||根节点左子为空||根节点左子的左子为空))
// 进入此处,显示数据量太少了,移除树形结构
tab[index] = first.untreeify(map); // too small
return;
}
// pl 为当前节点的左子 pr为当前节点的右子
TreeNode<K,V> p = this, pl = left, pr = right, replacement;
// 当前节点的左右节点都不为空
if (pl != null && pr != null) {
//
TreeNode<K,V> s = pr, sl;
// S = 当前节点(p)右子树的最深的左侧子节点
while ((sl = s.left) != null) // find successor
s = sl;
// s与P交换颜色
boolean c = s.red; s.red = p.red; p.red = c; // swap colors
// 记录s的右节点 记录当前节点的父亲节点
TreeNode<K,V> sr = s.right;
TreeNode<K,V> pp = p.parent;
// 如果s就是当前节点的右子树
if (s == pr) {
// p was s's direct parent

// 当前节点和s进行交换
p.parent = s;
// s的右节点已经备份
s.right = p;
}
else {

//如果s不是p的右子节点
// 得到s的父节点
TreeNode<K,V> sp = s.parent;
// sp成为p的父节点
if ((p.parent = sp) != null) {
if (s == sp.left)
// 根据s是原先位置的左子树还是右子树替换指定的位置
sp.left = p;
else
sp.right = p;
}
// 修改s的右子节点为当前节点的右节点
if ((s.right = pr) != null)
pr.parent = s;
}
// 当前节点的左子置为空
p.left = null;
if ((p.right = sr) != null)
// s的右子进行初始化
sr.parent = p;
if ((s.left = pl) != null)
// 当前节点的左子进行初始化
pl.parent = s;
if ((s.parent = pp) == null)
// pp 为空,证明当前节点为根节点,直接设置根节点即可
root = s;
else if (p == pp.left)
// 当前节点在上级节点的左子树还是右子树下,s用于替换
pp.left = s;
else
pp.right = s;
if (sr != null)
// s的右节点不为空
replacement = sr;
else
// 为空则为 p
replacement = p;
}
// 左节点不为空
else if (pl != null)
replacement = pl;
// 只有有节点不为空
else if (pr != null)
replacement = pr;
else
// 都为空
replacement = p;
// 左右节点至少有一个
if (replacement != p) {
// pp为当前节点的父节点,为替换节点的父节点
TreeNode<K,V> pp = replacement.parent = p.parent;
if (pp == null) // pp为空
root = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
// 全面清空 p当前对象
p.left = p.right = p.parent = null;
}
// 当前节点的颜色是不是为红色,是root,不是平衡二叉树
TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement);
if (replacement == p) {
// detach
// 清空p
TreeNode<K,V> pp = p.parent;
p.parent = null;
if (pp != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
}
}
// 移动标记,移动root至最前端
if (movable)
moveRootToFront(tab, r);
}
- 删除时平衡

// 删除时平衡
static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,
TreeNode<K,V> x) {
for (TreeNode<K,V> xp, xpl, xpr;;) {
// x 为当前 xp父 xpl父左 xpr父右
if (x == null || x == root)
// 无节点,或者为根节点无需平衡
return root;
else if ((xp = x.parent) == null) {
x.red = false;
// x的父节点为空,x为新的根节点
return x;
}
else if (x.red) {
// 当前节点为红色,父节点为黑色,当前节点顶替已经删除的父节点。
x.red = false;
return root;
}
// 当前节点为黑为父节点的左子
else if ((xpl = xp.left) == x) {
// fu父亲节点右子树不为空且为红色。
if ((xpr = xp.right) != null && xpr.red) {
// 父右节点为黑
xpr.red = false;
xp.red = true;
root = rotateLeft(root, xp);
xpr = (xp = x.parent) == null ? null : xp.right;
}
if (xpr == null)
x = xp;
else {
TreeNode<K,V> sl = xpr.left, sr = xpr.right;
if ((sr == null || !sr.red) &&
(sl == null || !sl.red)) {
xpr.red = true;
x = xp;
}
else {
if (sr == null || !sr.red) {
if (sl != null)
sl.red = false;
xpr.red = true;
root = rotateRight(root, xpr);
xpr = (xp = x.parent) == null ?
null : xp.right;
}
if (xpr != null) {
xpr.red = (xp == null) ? false : xp.red;
if ((sr = xpr.right) != null)
sr.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateLeft(root, xp);
}
x = root;
}
}
}
// 当前节点为父的右子
else {
// symmetric
if (xpl != null && xpl.red) {
xpl.red = false;
xp.red = true;
root = rotateRight(root, xp);
xpl = (xp = x.parent) == null ? null : xp.left;
}
if (xpl == null)
x = xp;
else {
TreeNode<K,V> sl = xpl.left, sr = xpl.right;
if ((sl == null || !sl.red) &&
(sr == null || !sr.red)) {
xpl.red = true;
x = xp;
}
else {
if (sl == null || !sl.red) {
if (sr != null)
sr.red = false;
xpl.red = true;
root = rotateLeft(root, xpl);
xpl = (xp = x.parent) == null ?
null : xp.left;
}
if (xpl != null) {
xpl.red = (xp == null) ? false : xp.red;
if ((sl = xpl.left) != null)
sl.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateRight(root, xp);
}
x = root;
}
}
}
}
}
g.查找节点
h.Hash扩容,红黑树的操作
- 树形结构进行分割
/**
* Splits nodes in a tree bin into lower and upper tree bins,
* or untreeifies if now too small. Called only from resize;
* see above discussion about split bits and indices.
*
* @param map the map
* @param tab the table for recording bin heads
* @param index the index of the table being split
* @param bit the bit of hash to split on
* 分割树形结构为上下树形结构
*/
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order
// 关于链表内容的分离 lo低位,hi高位,Head是顶部,Tail是尾部
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
//
int lc = 0, hc = 0;
for (TreeNode<K,V> e = b, next; e != null; e = next) {
// next赋值为下个节点
next = (TreeNode<K,V>)e.next;
// 下一个节点置空
e.next = null;
// 如果是低位
if ((e.hash & bit) == 0) {
// 低位尾部赋值给e的上一个完成闭环,如果低位尾部为空,证明现在还没有数据
if ((e.prev = loTail) == null)
// 那么e就是低位的头部
loHead = e;
else
// 在尾部继续链接
loTail.next = e;
// 变更尾部为最新的尾部
loTail = e;
// 统计
++lc;
}
else {
// 如果为高位的话,代码解释同上
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
// 低位有数据
if (loHead != null) {
// 低位的长度是否小于维持树形结构的阈值
if (lc <= UNTREEIFY_THRESHOLD)
// 不足则转换为链表
tab[index] = loHead.untreeify(map);
else {
// 足够的话 赋值给当前的hash位
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
// 高位不为空的话,低位的链表需要转换为树形结构
loHead.treeify(tab);
}
}
// / 高位不为空的话
if (hiHead != null) {
// 的长度是否小于维持树形结构的阈值
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
// 同理
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}
I.整体变量检查
/**
* Recursive invariant check
* 检查变量
*/
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {
// tp 父亲节点 tl左子树 tr右子树 tb上一个 tn下一个
TreeNode<K,V> tp = t.parent, tl = t.left, tr = t.right,
tb = t.prev, tn = (TreeNode<K,V>)t.next;
// tb是上一个节点
// 上一个节点为空,或者上节点的下节点不是自己
if (tb != null && tb.next != t)
return false;
// tn下一个
// 下节点为空,或者下节点的上节点不等于自己
if (tn != null && tn.prev != t)
return false;
// tp父亲节点
// 父节点不为空,父节点的左右节点都不等于自己
if (tp != null && t != tp.left && t != tp.right)
return false;
// 左节点不为空,左节点的父亲不是自己或者左节点的hash大于自己
if (tl != null && (tl.parent != t || tl.hash > t.hash))
return false;
// 右节点不为空,右节点的父亲不是自己或者右节点的hash小于自己
if (tr != null && (tr.parent != t || tr.hash < t.hash))
return false;
// 当前节点为红色并且左节点不为空,左节点也是红色,右节点不为空也为红色
if (t.red && tl != null && tl.red && tr != null && tr.red)
return false;
// 左节点不为空,检查左节点
if (tl != null && !checkInvariants(tl))
return false;
// 右节点不为空,检查右节点
if (tr != null && !checkInvariants(tr))
return false;
return true;
}
4.3 链表红黑树互转的解析
a.链表转红黑树 – 待完成
b.红黑树转链表 – 待完成
参考文献
注:源代码部分,来自java源代码3,注释是自己写的,删除或者部分删除原来的英文注释