一、sqoop
sqoop是一款开源的数据迁移工具,可以Hive与RDMS之间数据的导入导出操作。也可以实现HDFS和RDMS之间数据的迁移功能。
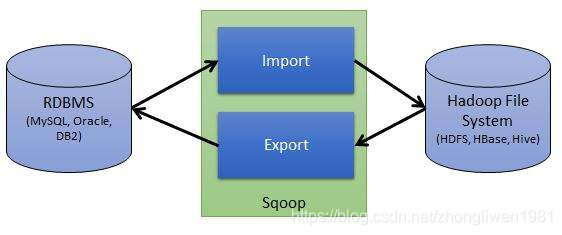
1.1 Sqoop的工作机制
1.1.1 导入机制
Sqoop导入操作就是将RDBMS数据导入到HDFS中。
执行导入操作时候,Sqoop会通过JDBC读取表中的列和列的数据类型,然后再把读取到的数据类型映射成Java数据类型,而底层运行的MapReduce会通过InputFormat对象从数据库中读取数据,并且DataDrivenDBInputFormat对象能够根据查询结果划分为不同的map任务,最后把这些任务发送到MapReduce集群中执行,Map任务的结果会填充到对应的实例中。
1.1.2 导出机制
Sqoop导出操作就是将HDFS中数据导出到RDBMS中。导出前,Sqoop会选择导出方法,通常是JDBC,接着Sqoop会生成一个Java类,这个类可以解析HDFS中的文本数据,并将相应的值插入表中。基于JDBC的导出方法会生成多条insert语句,每条insert语句均会向表中插入多条数据。同时为了确保不同I/O可以并行执行,在从HDFS读取数据并与数据库通信的时候,会启动多个线程同时执行。
1.2 Sqoop安装
下载地址:http://archive.apache.org/dist/sqoop/,下载完成后解压缩。
1.2.1 Sqoop配置
cd /export/servers/sqoop-1.4.7/conf
cp sqoop‐env‐template.sh sqoop‐env.sh
vi sqoop-env.sh
在sqoop-env.sh文件中添加如下内容:
export HADOOP_COMMON_HOME/export/servers/hadoop‐3.1.1
export HADOOP_MAPRED_HOME=/export/servers/hadoop‐3.1.1
export HIVE_HOME=/export/servers/apache‐hive‐3.1.1‐bin
1.2.2 添加依赖jar包
sqoop需要添加数据库的驱动包,以及java-json的依赖包。准备好jar包后,将他们添加到sqoop的lib目录下即可。
添加完成后,执行如下命令验证是否成功:
cd /export/servers/sqoop-1.4.7/
bin/sqoop-version
1.3 数据导入
1.3.1 sqoop命令
- 列出mysql中所有数据库:
bin/sqoop list‐databases ‐‐connect jdbc:mysql://192.168.31.7:3306/ ‐‐username root ‐‐password root
- 查看mysql数据库中有哪些表:
bin/sqoop list‐tables ‐‐connect jdbc:mysql://192.168.31.7:3306/azkaban ‐‐username root ‐‐password root
- 查看帮助文档:
bin/sqoop list‐databases ‐‐help
1.3.2 导入示例
- 表数据:
create table emp(
id int primary key auto_increment,
name varchar(255) not null default '',
dep varchar(20) default '',
salary int default 0,
dept char(2) default ''
);
create table emp_add(
id int primary key auto_increment,
hon varchar(20) not null default '',
street varchar(20) default '',
city varchar(20) default ''
);
create table emp_conn(
id int primary key auto_increment,
phone varchar(11) not null default '',
email varchar(50) default ''
);
insert into emp values(1201, 'gopal', 'manager', 50000, 'TP');
insert into emp values(1202, 'manisha', 'proof reader', 50000, 'TP');
insert into emp values(1203, 'khalil', 'php dev', 30000, 'AC');
insert into emp values(1204, 'prasanth', 'php dev', 30000, 'AC');
insert into emp values(1205, 'kranthi', 'admin', 20000, 'TP');
insert into emp_add values(1201, '288A', 'vgiri', 'jublee');
insert into emp_add values(1202, '108I', 'aoc', 'sec-bad');
insert into emp_add values(1203, '144Z', 'pgutta', 'hyd');
insert into emp_add values(1204, '78B', 'old city', 'sec-bad');
insert into emp_add values(1205, '720X', 'hitec', 'sec-bad');
insert into emp_conn values(1201, '2356742', '[email protected]');
insert into emp_conn values(1202, '1661663', '[email protected]');
insert into emp_conn values(1203, '8887776', '[email protected]');
insert into emp_conn values(1204, '9988774', '[email protected]');
insert into emp_conn values(1205, '1231231', '[email protected]');
导入命令:
# 将emp表数据导入到HDFS中
bin/sqoop import ‐‐connect jdbc:mysql://192.168.31.7:3306/azkaban ‐‐password root ‐‐username root ‐‐table emp ‐‐m 1
导入成功后,执行HDFS命令查看导入结果:
hdfs dfs -cat /user/root/emp/part*
也可以指定–target-dir参数,用来指定导出的HDFS目录。比如:
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --delete-target-dir --table emp --target-dir /sqoop/emp -m 1
默认sqoop使用逗号“,”分割每一列的数据。如果要指定分隔符,可以指定–fields-terminated-by参数。比如:
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --delete-target-dir --table emp --target-dir /sqoop/emp2 -m 1 --fields-terminated-by '\t'
也可以将数据导出到Hive中,导出步骤:
- 首先将
hive‐exec‐3.1.1.jar包拷贝到sqoop的lib目录下;
cp /export/servers/apache‐hive‐3.1.1‐bin/lib/hive‐exec‐3.1.1.jar /export/servers/sqoop‐1.4.7/lib
- 导出之前,需要先在hive中创建好需要的表;
create database sqooptohive;
use sqooptohive;
create external table emp_hive(id int,name string,dep string,salary int ,dept string) row format delimited fields terminated by '\001';
- 执行导出操作;
bin/sqoop import ‐‐connect jdbc:mysql://192.168.31.7:3306/azkaban ‐‐username root ‐‐password root ‐‐table emp ‐‐fields‐terminated‐by '\001' ‐‐hive‐import ‐‐hive‐table sqooptohive.emp_hive ‐‐hive‐overwrite ‐‐delete‐target‐dir ‐‐m 1
参数说明:
‐‐hive‐import:指定该命令是执行导入操作;
--hive-table:要导出的Hive表名;
--hive-overwrite:指定覆盖源数据;
-m:指定多少个map任务并发执行;
可以通过指定--hive-database参数,直接将mysql数据以及表结构一起导入到hive中;
bin/sqoop import ‐‐connect jdbc:mysql://192.168.31.7:3306/azkaban ‐‐username root ‐‐password root ‐‐table emp_conn ‐‐hive‐import ‐m 1 ‐‐hive‐database sqooptohive
如果只需要导出满足条件的数据,可以指定--where参数。
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --table emp_add --target‐dir /sqoop/emp_add -m 1 --delete‐target‐dir --where "city = 'sec‐bad'"
也可以通过指定--query参数指定要执行的sql命令。
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root -m 1 --query 'select * from emp_add where city="sec-bad" and $CONDITIONS' --target-dir /sqoop/emp_add --delete-target-dir
如果重复上面导入命令,发现后面导入操作会覆盖前面导入的数据。Sqoop还支持增量导入,即后面导入数据不会覆盖前面导入过的数据。如果要使用增量导入,需要指定三个参数:--incremental、--check-column、--last-value。
// 导入emp表中id大于1202的记录。
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --table emp --incremental append --check-column id --last-value 1202 -m 1 --target-dir /sqoop/increment
还可以通过--where参数来实现更加精准的控制。
bin/sqoop import --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --table emp --incremental append --check-column id --where "id > 1202" -m 1 --target-dir /sqoop/increment
注意:增量导入不能够指定–delete-target-dir参数。
1.4 数据导出
数据导出就是将数据从HDFS导出到RDMBS中。导出数据内容如下:

数据导出步骤:
- 第一步:在mysql数据库中创建一张表,表字段必须与HDFS中准备导出数据的类型和个数相同;
注意:执行数据导出之前,目标表必须已经存在。
create table emp_out(id int, name varchar(100), dep varchar(50), sal int, dept varchar(10), create_time timestamp);
- 第二步:执行导出;
bin/sqoop export --connect jdbc:mysql://192.168.31.7:3306/azkaban --username root --password root --table emp_out --export-dir /sqoop/emp --input-fields-terminated-by ","