Dennis M. Ritchie的文章(Chistory)https://www.bell-labs.com/usr/dmr/www/chist.html
Problems became evident when I tried to extend the type notation, especially to add structured (record) types. Structures, it seemed, should map in an intuitive way onto memory in the machine, but in a structure containing an array, there was no good place to stash the pointer containing the base of the array, nor any convenient way to arrange that it be initialized. For example, the directory entries of early Unix systems might be described in C as
struct {
int inumber;
char name[14];
};
I wanted the structure not merely to characterize an abstract object but also to describe a collection of bits that might be read from a directory. Where could the compiler hide the pointer to name that the semantics demanded? Even if structures were thought of more abstractly, and the space for pointers could be hidden somehow, how could I handle the technical problem of properly initializing these pointers when allocating a complicated object, perhaps one that specified structures containing arrays containing structures to arbitrary depth?
The solution constituted the crucial jump in the evolutionary chain between typeless BCPL and typed C. It eliminated the materialization of the pointer in storage, and instead caused the creation of the pointer when the array name is mentioned in an expression. The rule, which survives in today’s C, is that values of array type are converted, when they appear in expressions, into pointers to the first of the objects making up the array.
This invention enabled most existing B code to continue to work, despite the underlying shift in the language’s semantics. The few programs that assigned new values to an array name to adjust its origin—possible in B and BCPL, meaningless in C—were easily repaired. More important, the new language retained a coherent and workable (if unusual) explanation of the semantics of arrays, while opening the way to a more comprehensive type structure.
一.指针与数组的联系:
指针与数组是C语言中很重要的两个概念,它们之间有着密切的关系,利用这种关系,可以增强处理数组的灵活性,加快运行速度,本文着重讨论指针与数组之间的联系及在编程中的应用。
1.指针与数组的关系
当一个指针变量被初始化成数组名时,就说该指针变量指向了数组。如:
char str[20], *ptr;
ptr=str;
**ptr被置为数组str的第一个元素的地址,因为数组名就是该数组的首地址,**也是数组第一个元素的地址。此时可以认为指针ptr就是数组str(反之不成立),这样原来对数组的处理都可以用指针来实现。如对数组元素的访问,既可以用下标变量访问,也可以用指针访问。
2.指向数组元素的指针
若有如下定义:
int a[10], *pa;
pa=a;
则p=&a[0]是将数组第1个元素的地址赋给了指针变量p。
实际上,C语言中数组名就是数组的首地址,所以第一个元素的地址可以用两种方法获得:p=&a[0]或p=a。
这两种方法在形式上相像,其区别在于:pa是指针变量,a是数组名。值得注意的是:pa是一个可以变化的指针变量,而a是一个常数。因为数组一经被说明,数组的地址也就是固定的,因此a是不能变化的,不允许使用a++、++a或语句a+=10,而pa++、++pa、pa+=10则是正确的。由此可见,此时指针与数组融为一体。
3.指针与一维数组
理解指针与一维数组的关系,首先要了解在编译系统中,一维数组的存储组织形式和对数组元素的访问方法。
一维数组是一个线形表,它被存放在一片连续的内存单元中。C语言对数组的访问是通过数组名(数组的起始地址)加上相对于起始地址的相对量(由下标变量给出),得到要访问的数组元素的单元地址,然后再对计算出的单元地址的内容进行访问。通常把数据类型所占单元的字节个数称为扩大因子。
实际上编译系统将数组元素的形式a[i]转换成*(a+i),然后才进行运算。对于一般数组元素的形式:<数组名>[<下标表达式>],编译程序将其转换成:(<数组名>+<下标表达式>),其中下标表达式为:下标表达式扩大因子。整个式子计算结果是一个内存地址,最后的结果为:*<地址>=<地址所对应单元的地址的内容>。由此可见,C语言对数组的处理,实际上是转换成指针地址的运算。
数组与指针暗中结合在一起。因此,**任何能由下标完成的操作,都可以用指针来实现,**一个不带下标的数组名就是一个指向该数组的指针。
2)指向由j个整数组成的一维数组的指针变量
当指针变量p不是指向整型变量,而是指向一个包含j个元素的一维数组。如果p=a[0],则p++不是指向a[0][1],而是指向a[1]。这时p的增值以一维数组的长度为单位。
编译器为了简化对数组的支持,实际上是利用指针实现了对数组的支持。具体来说,就是将表达式中的数组元素引用转化为指针加偏移量的引用。这么说大家可能不理解,首先什么是引用呢?引用其实就是使用,从编译器的角度来看,就是从一个符号找到对应内存并进行读写的过程。为了理解这一个过程,我们先来看看对于一个普通变量,编译器是怎么做的。
比如我们用C语言写了这样的语句
int a;
a = 3;
编译器为了完成这两句代码,首先在编译过程中要创建一个符号表,样子大概如下图:
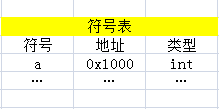
然后在运行过程中,编译器发现a=3这句代码时,会在符号表里找a对应的地址,然后把3放入对应的地址,即这里的0x1000。那如果是一个指针呢?即如果是p=3会怎么做呢?首先,符号表变成了这个样子
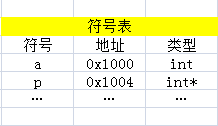
在运行过程中,编译器遇到p=3时,首先要从符号表中找到p的地址0x1004,然后取出0x1004中的内容,这里假设为0x2000,最后把3放到0x2000内存地址中,即*(0x2000)=3。
相信大家已经看明白了,想比于利用普通变量,利用指针存取数据的过程中多了一部取地址的的过程。这也就是指针变量于普通变量最大的不同。
下面再来看一下指针加偏移量的引用方式,还以上面的指针p为例,让我们来看一下*(p+2)=3的实现过程。首先,编译器从符号表中找到p然后,取出里面的内容0x2000,再根据其类型(int*),做一个运算,0x2000+2×sizeof(int)=0x2008。所以编译器会把3放入0x2008这个内存地址。整个过程可表示为*(*(0x1004)+2)=3。从这里也可以看出为什么指针必须有类型,因为在引用过程中要用到指针所指类型的长度。
最后来看一下,数组元素的引用是如何实现的,假设我们定义了一个数组,并对其元素进行了引用
int b[10];
b[4] = 3;
对应的符号表变成了这个样子!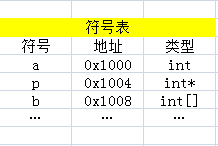
那b[4]=3如何完成呢?首先,找到符号b,然后发现其类型为int[](假想表达方式,C语言中不支持这样写),所以计算式变成了0x1008+4×sizeof(int)=0x1018,然后把3放入0x1018就可以了。用一个式子表达就是*(0x1008+4)=3。
从上面的寻址式子可以看出,普通变量、指针、数组三者对于编译器的区别。具体到数组,它即具有普通变量的直接性,即不用取两次地址里的内容而是取一次,同时又具有和指针相同的偏移量引用方式,即下标的实现实际是由指针加偏移量实现的。
为了表明上述事实(或者是为了提高C语言入门门槛),C语言对指针与数组的引用方式做了可以“交叉”使用的语法规定。就上面的例子来说,如果p指针指向数组b时,b[i]、(b+i)、p[i]、(p+i)都是对数组第i个元素的正确引用方式,这也给很多C语言学习者制造了“指针和数组一样”的错觉。
4.指针与字符数组
C语言中许多字符串操作都是由指向字符数组的指针及指针的运算来实现的。因为对于字符串来说,一般都是严格的顺序存取方式,使用指针可以打破这种存取方式,更为灵活地处理字符串。
另外由于字符串以′\0′作为结束符,而′\0′的ASCII码是0,它正好是C语言的逻辑假值,所以可以直接用它作为判断字符串结束的条件,而不需要用字符串的长度来判断。C语言中类似的字符串处理函数都是用指针来完成,使程序运行速度更快、效率更高,而且更易于理解。
二.指针与数组的区别:
1.把数组作为参数传递的时候,会退化为指针
在作为函数传递参数的时候,数组是等同于指针的,为什么呢?因为,数组在作为参数传递或者调用数组的时候,通常都是把数组首元素的地址作为参数来传递或者调用,这个时候数组名就相当于数组首元素的地址,也就是指针了。就是说void test (int array[]); void test (int * array),这两种函数声明其实都是一样的,形参这都是&array[0];只是表达的方式不一样
数组名作为函数形参时,在函数体内,其失去了本身的内涵,仅仅只是一个指针;很遗憾,在失去其内涵的同时,它还失去了其常量特性,可以作自增、自减等操作,可以被修改。
所以,数组名作为函数形参时,其沦落为一个普通指针!它的贵族身份被剥夺,成了一个地地道道的只拥有4个字节的平民。
典型的情况是
void func(int A[])
{
//sizeof(A)得到的是4bytes
}
int main()
{
int a[10]; //sizeof(a) 得到的结果是40bytes
funct(a);
}
2、数组名可作为指针常量
根据结论2,数组名可以转换为指向其指代实体的指针,所以程序1中的第5行数组名直接赋值给指针,程序2第7行直接将数组名作为指针形参都可成立。
下面的程序成立吗?
int intArray[10];
intArray++;
读者可以编译之,发现编译出错。原因在于,虽然数组名可以转换为指向其指代实体的指针,但是它只能被看作一个指针常量,不能被修改。
而指针,不管是指向结构体、数组还是基本数据类型的指针,都不包含原始数据结构的内涵,在WIN32平台下,sizeof操作的结果都是4。
顺便纠正一下许多程序员的另一个误解。许多程序员以为sizeof是一个函数,而实际上,它是一个操作符,不过其使用方式看起来的确太像一个函数了。语句sizeof(int)就可以说明sizeof的确不是一个函数,因为函数接纳形参(一个变量),世界上没有一个C/C++函数接纳一个数据类型(如int)为"形参"。
3.对于问题:
char a[3] = "abc";
strcpy(a,"end");//it's ok
char *a = "abc";
strcpy(a,"end"); //it's wrong
解释如下:
char *a = “abc”; abc是一个字符串常量,有它自己的存储空间,因为分配在只读数据块,我们无法直接访问。这样赋值后,a只能读,不能写
所以strcpy(a, “end”)不行,只有当你为a分配非常量的存储空间后才行
如:
char *a = new char[4];
strcpy(a, "end");
printf("%s", a);
delete []a
4.数组和指针的分配
数组是开辟一块连续的内存空间,数组本身的标示符代表整个数组,可以用sizeof取得真实的大小;指针则是只分配一个指针大小的内存,并可把它的值指向某个有效的内存空间
[全局的和静态的]
char *p= "hello ";//一个指针,指向只读数据块(section)里的 "hello ",可被编译器放入字符串池(也就是说, 你在写一个char *q= "hello ",可能和p共享数据)
char a[]= "hello ";//一个数组,分配在可写数据块(section),不会被放到字符串池中
其他:
1.编译时不会为指针分配存储空间, 但是指针在结构体中, 是会默认分配的,
2.数组的内部实现也是依靠指针, 只是数组名是一个指针常量, 数组一次寻址(即通过数组名直接找到数组元素), 指针需要两次寻址(先确定指针变量的己值,然后定位到指针的他值)
3.指针变量+1, 不是加一个地址量(即一个字节), 而是加一个内存单元, 具体的长度由指针类型决定
4.指针指向数组的时候, 只是指向数组的首地址, 他不代表数组类型, 可以通过 指针++的方式依次获取数组内容
5.数组名在两种情况下不被视为指向起始元素的指针。
a.作为sizeof运算符的操作数出现时
b.作为取址运算符&的操作数出现时
6.两个指针不能做加法运算,但是可以做减法运算
7.数组名是指针常量, 所以没有办法再次对一个数组名重新分配内存地址; 换言之, 可以对指针变量赋值, 但是不能对数组名赋值
8.二者在结构体中占用内存大小不同
void test12(){
struct test{
int *p;
};
size_t tmp1 = sizeof(struct test); //输出8
printf("%zu\n",tmp1);
struct test1{
int p[10];
};
size_t tmp2 = sizeof(struct test1); //输出40
printf("%zu\n",tmp2);
}
-
定义了一个指针, 是可以按数组的方式使用的
-
数组是比指针更高一层级的定义, 数组作为形参, 将退化为指针
如 int *p; … p[5]=2;
11.数组存数据,指针存地址
12.指针对比数组的一个优势: 可以扩容, 因为指针的内存可以通过malloc分配, 所以也可以通过realloc扩容
-
C语言中结构体数组:每一个元素都是一个结构体类型的变量,都包含结构体中所有的成员项
而JAVA中的数组, 类似与C中的指针数组, 存放的是对象的地址引用