Tensorflow
Tensorflow是当下最流行的深度学习框架之一, Tensorflow可以分为tensor(张量)和flow(流)两部分。不得不说 这个老师讲的是真的好呀,又基础又详细,很适合入门(keng)新手。
Tensor(张量)
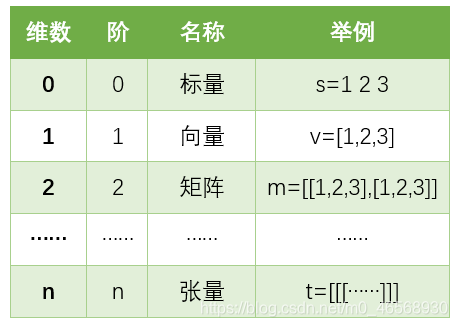
张量就是一个多维数组,用阶表示张量的维度。简单判断张量是几阶的方法:有几个[ ]就是几阶。
一、 创建张量
张量的创建可通过直接创建和由numpy数组转换,此外还有一些常用的特殊张量方法:
1. 直接创建
tf.constant(张量内容,dtype=数据类型)
import tensorflow as tf
t=tf.constant([2,3],dtype=tf.int64)#创建一个一阶张量
print(t)
>>tf.Tensor([2 3], shape=(2,), dtype=int64)
2.用numpy数据类型转换为tensor类型
tf.convert_to_tensor(数据名,dtype=数据类型)
import tensorflow as tf
import numpy as np
a=np.arange(0,5)
t=tf.convert_to_tensor(a,dtype=tf.int64)#将一维数组转化为一维张量
print(a,t)
>>[0 1 2 3 4] tf.Tensor([0 1 2 3 4], shape=(5,), dtype=int64)
3.创建特殊的张量
① 全为0的张量:维度如何表示:一维直接填一个数字,二维用[行,列],多维用[n,m,j,k……]
#全为0的张量
tf.zeros(3)#创建一维零张量:只需要指定张量内容中0的个数
tf.zeros([2,3])#二维
>><tf.Tensor: shape=(3,), dtype=float32, numpy=array([0., 0., 0.], dtype=float32)>
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=array([[0., 0., 0.],
[0., 0., 0.]], dtype=float32)>
② 全为1的张量:维度同上
#全为1的张量
tf.ones(3)
>><tf.Tensor: shape=(3,), dtype=float32, numpy=array([1., 1., 1.], dtype=float32)>
③ 全为指定值的张量:tf.fill(维度,指定值)
#全为指定值的张量
tf.fill([2,3],1)
>><tf.Tensor: shape=(2, 3), dtype=int32, numpy=array([[1, 1, 1],
[1, 1, 1]])>
④ 生成正态分布的随机数:tf.random.normal(维度,mean=均值,stddev=标准差)
tf.random.normal([3,3],mean=1,stddev=0.5)
>><tf.Tensor: shape=(3, 3), dtype=float32, numpy=array([[0.5939642 , 0.7801706 , 0.73448145],
[0.07946539, 1.8461295 , 1.7190137 ],
[0.7935035 , 1.1642232 , 0.63996214]], dtype=float32)>
⑤ 生成截断式正态分布的随机数:即生成的随机数位于(均值-2标准差,均值+2标准差)范围: tf.random.truncated_normal(维度,mean=均值,stddev=标准差)
tf.random.truncated_normal([3,3],mean=1,stddev=0.5)
>><tf.Tensor: shape=(3, 3), dtype=float32, numpy=array([[1.3027463 , 1.8570051 , 1.3586129 ],
[1.5800164 , 1.2975678 , 0.7345885 ],
[1.7934418 , 0.97875464, 1.0045136 ]], dtype=float32)>
⑥ 生成均匀分布的随机数:tf.random.uniform(维度,minval=最小值,maxval=最大值)
tf.random.uniform([3,3],minval=0,maxval=1)
>><tf.Tensor: shape=(3, 3), dtype=float32, numpy=array([[0.8119303 , 0.97470737, 0.5821942 ],
[0.07488775, 0.375291 , 0.68286586],
[0.23914921, 0.16803873, 0.78797734]], dtype=float32)>
二、 Tensorflow常用函数
1.平均、求和
① 轴向:axis:
axis=0:代表按列计算
axis=1:代表按行计算
不指定时,计算所有元素
② 平均值:
tf.reduce_mean(张量名,axis=操作轴)
③ 求和:
tf.reduce_sum(张量名,axis=操作轴)
t=tf.constant([[1,2,3],[5,6,7]])
print(t)
m=tf.reduce_mean(t,axis=0)#按列计算平均值
print(m)
s=tf.reduce_sum(t,axis=1)#按行计算和
print(s)
>>tf.Tensor([[1 2 3]
[5 6 7]], shape=(2, 3), dtype=int32)
tf.Tensor([3 4 5], shape=(3,), dtype=int32)
tf.Tensor([ 6 18], shape=(2,), dtype=int32)
2. 标记可训练变量:
tf.variable(初始值):将变量标记为“可训练”,被标记的变量会在反向传播中记录梯度信息。可用于神经网络训练中标记带训练参数。
tf.Variable(tf.constant([[1,2,3],[5,6,7]]))
>><tf.Variable 'Variable:0' shape=(2, 3) dtype=int32, numpy=array([[1, 2, 3],
[5, 6, 7]])>
3. 数学运算:
四则运算:只有张量维度相同才可计算
对应元素相加:tf.add(张量1,张量2)
对应元素相减:tf.subtract(张量1,张量2)
对应元素相乘:tf.multiply(张量1,张量2)
对应元素相除:tf.divide(张量1,张量2)
平方:tf.square(张量名)
次方:tf.pow(张量名,n次方数)
开方:tf.sqrt(张量名)
矩阵乘:tf.matmul(张量1,张量2)
t1=tf.fill([2,2],1.0)
t2=tf.fill([2,2],3.0)
print("t1:",t1)
print("t2:",t2)
print("t1+t2:",tf.add(t1,t2))
print("t1-t2:",tf.subtract(t1,t2))
print("t1*t2:",tf.multiply(t1,t2))
print("t1/t2:",tf.divide(t1,t2))
print("t1的平方:",tf.square(t1))
print("t1的三次方:",tf.pow(t1,3))
print("t1的开方:",tf.sqrt(t1))
>>t1: tf.Tensor([[1. 1.]
[1. 1.]], shape=(2, 2), dtype=float32)
t2: tf.Tensor([[3. 3.]
[3. 3.]], shape=(2, 2), dtype=float32)
t1+t2: tf.Tensor([[4. 4.]
[4. 4.]], shape=(2, 2), dtype=float32)
t1-t2: tf.Tensor([[-2. -2.]
[-2. -2.]], shape=(2, 2), dtype=float32)
t1*t2: tf.Tensor([[3. 3.]
[3. 3.]], shape=(2, 2), dtype=float32)
t1/t2: tf.Tensor([[0.33333334 0.33333334]
[0.33333334 0.33333334]], shape=(2, 2), dtype=float32)
t1的平方: tf.Tensor([[1. 1.]
[1. 1.]], shape=(2, 2), dtype=float32)
t1的三次方: tf.Tensor([[1. 1.]
[1. 1.]], shape=(2, 2), dtype=float32)
t1的开方: tf.Tensor([[1. 1.]
[1. 1.]], shape=(2, 2), dtype=float32)
4. 切分传入张量的第一维度,生成特征/标签对,构建数据集
data=tf.data.Dataset.from_tensor_slices((输入特征,标签))
5. 计算张量的梯度
tf.GradientTape
with tf.GradientTape() as tape:
计算步骤
grad=tape.gradient(loss,w)
#计算梯度
with tf.GradientTape() as tape:
w=tf.Variable(tf.constant(2.0))
loss=tf.pow(w,3)
grad=tape.gradient(loss,w)
print(grad)
>>tf.Tensor(12.0, shape=(), dtype=float32)
这里计算的是当x=2时的w^3的梯度值,其导数为3ww,所以其梯度值为32*2=12
6.遍历每个元素
enumerate(列表名)
#遍历所有元素
m=['a','b','c']
for i,element in enumerate(m):
print(i,element)
>>0 a
1 b
2 c
7.独热编码
将待转换数据转换为one_hot形式的数据输出:tf.one_hot(待转换数据,depth=几分类)
#one_hot
l=tf.constant([1,2,0])
print("l为:",l)
oh=tf.one_hot(l,depth=3)
print("独热编码为:",oh)
>>l为: tf.Tensor([1 2 0], shape=(3,), dtype=int32)
独热编码为: tf.Tensor([[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]], shape=(3, 3), dtype=float32)
8.激活函数softmax(y)
当输出为多分类时,可使用softmax使每个类别的概率输出符合概率分布
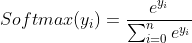
#softmax()
y=tf.constant([1.5,2.9,-0.8])
y_pro=tf.nn.softmax(y)
print("概率分布为:",y_pro)
>>概率分布为: tf.Tensor([0.19396915 0.7865837 0.01944712], shape=(3,), dtype=float32)
9. 自更新函数
w.assign_sub(w要自减的内容)注意这里是自减
在神经网络中需要不断更新迭代超参数,该函数可用于更新超参数.在调用自更新之前需要先将变量定义为可训练
#自更新
w=tf.Variable(2.0)#先设置W为可训练,初值为2
w.assign_sub(0.1)#自减0.1
print(w)
>><tf.Variable 'Variable:0' shape=() dtype=float32, numpy=1.9>
10.获取张量沿指定维度最大值的索引
tf.argmax(张量名,axis=操作轴) 注:索引是从0开始的
t=tf.constant([[1,4,3],[4,3,6]])
print(t)
print(tf.argmax(t,axis=0))#按列输出最大值的索引
>>tf.Tensor([[1 4 3]
[4 3 6]], shape=(2, 3), dtype=int32)
tf.Tensor([1 0 1], shape=(3,), dtype=int64)